笔记说明:本文是我的学习笔记,大部分内容整理自 黄红梅,张良均等.Python数据分析与应用[M].北京:人民邮电出版社,2018:133-163. 还有部分片断知识来自网络搜索补充。
这本书挺好的哈,我觉得(个人看书感受),可以入手购买。
接上文
2.标准化
2.1离差标准化(min-max标准化)
2.1.1上栗子!
import pandas as pd
import numpy as np
detail = pd.read_csv("D:\\codes\\python\\data\\detail.csv",
index_col=0,encoding='gbk')
# 定义函数min-max标准化
def minmaxscale(data):
data=(data-data.min())/(data.max()-data.min())
return data
# 对菜品订单售价和销售做标准化
data1=minmaxscale(detail['counts'])
data2=minmaxscale(detail['amounts'])
data3=pd.concat([data1,data2],axis=1)
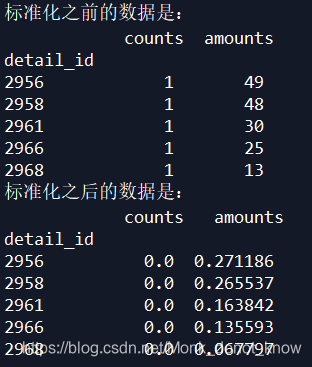
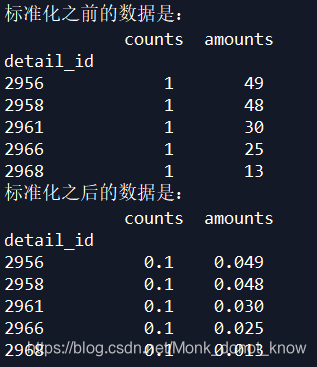
print('标准化之前的数据是:\n',detail[['counts','amounts']].head())
print('标准化之后的数据是:\n',data3.head())
诺,输出结果是这样的:
这个标准化有三点需要注意:
a.当数据值=min时,标准 化之后就会等于零;
b.在数据分布不均匀,又极差较大的情况下,标准化之后会出现数据的差别不大的现象;
c.在将来新的数据如果出现比现有数据max还大的情况,就会报错,这时候需要重新设置min,max。
2.2标准差标准化(Z分数标准化)
2.2.1上栗子!
def standardscale(data):
data=(data-data.mean())/data.std()
return data
# 对菜品订单售价和销售做标准化
data4=standardscale(detail['counts'])
data5=standardscale(detail['amounts'])
data6=pd.concat([data4,data5],axis=1)
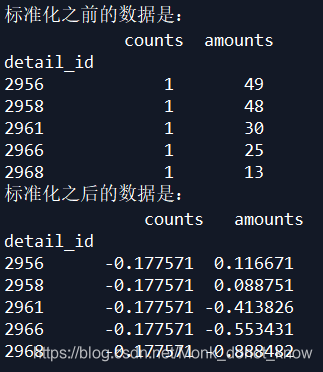
print('标准化之前的数据是:\n',detail[['counts','amounts']].head())
print('标准化之后的数据是:\n',data6.head())
诺,结果是这样的:
2.3小数定标标准化
这个标准化是第一次见,但是很简单,就是找到数据绝对值最大的那个数,然后除以10^(次方)。将数据映射到[-1,1]这个区间。
这里有点没懂?????????直接除以abs(max)不就行了吗????????看这个栗子的代码,我蒙了,谁给我解释一下啊
2.3.1上栗子!
def decimalscale(data):
data=data/10**np.ceil(np.log10(data.abs().max()))
return data
# 对菜品订单售价和销售做标准化
data7=decimalscale(detail['counts'])
data8=decimalscale(detail['amounts'])
data9=pd.concat([data7,data8],axis=1)
print('标准化之前的数据是:\n',detail[['counts','amounts']].head())
print('标准化之后的数据是:\n',data9.head())
np.ceil()就是取,离这个点最近的整数。
这样的话并不能保证端点值是可以取到的啊????疑问
结果是这样的:
3.数据转化
3.1哑变量处理
3.1哑变量处理
get_dummies(data, prefix=None, prefix_sep='_',
dummy_na=False, columns=None, sparse=False,
drop_first=False, dtype=None)
| 参数 | 说明 |
|---|---|
| data | 接收array、dataframe或者series。数据 |
| prefix | 接收string、string的列表或者dict,表示哑变量处理之后列名的前缀,默认none |
| prefix_na | 接收boolean。表示是否为nan值添加一列。默认false |
| columns | 接收类似list的数据,表示dataframe中需要编码的列名,默认none,表示对所有object和category类型进行编码 |
| sparse | 接收Boolean,表示虚拟列是否是稀疏的,默认false |
| drop_first | 接收Boolean,表示是否通过从k个分类别中删除第一级来获得k-1个分类级别,默认false |
3.1.1上栗子!
对菜品名称哑变量处理
detail = pd.read_csv("D:\\codes\\python\\data\\detail.csv",encoding='gbk')
data=detail.loc[0:7,'dishes_name']
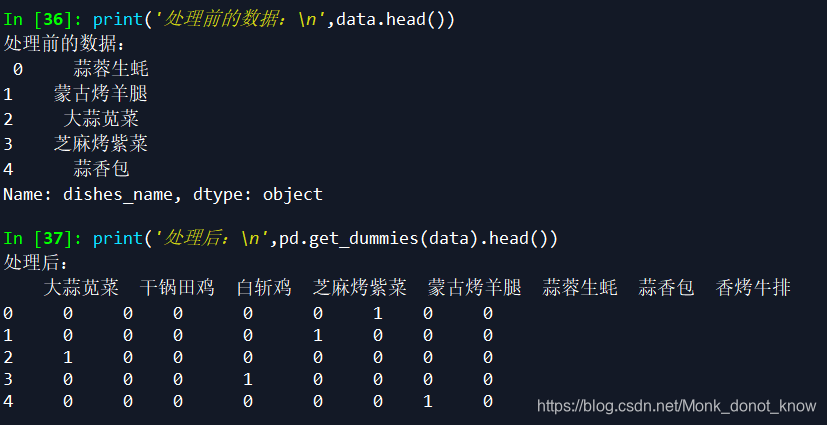
print('处理前的数据:\n',data.head())
print('处理后:\n',pd.get_dummies(data).head())
诺,结果如下:
3.2离散化连续型数据
首先要明确一下这里的一个概念,这里的方法其实就是特征工程里面常用的一个,无监督分箱法。
这个么,我经常使用卡方分箱方法。我在下一本书的学习也会整理这个知识,不过,网上有现成的,请看下面推荐的两个博客:
可以看这个博客
还有这个
3.2.1等宽法
cut(x, bins, right=True, labels=None, retbins=False,
precision=3, include_lowest=False, duplicates='raise')
| 参数 | 说明 |
|---|---|
| x | 接收array或者series,代表需要进行离散化处理的数据,无默认 |
| bins | 接收int、list、array、tuple。int的时候,代表离散化后的类别数目;若为序列,则表示进行切分的区间,每两个个数的间隔为一个区间。无默认 |
| right | 接收Boolean,代表右侧是否为闭区间,默认true |
| labels | 接收list、array。代表离散化后各个类别的名称。默认空 |
| retbins | 接收Boolean,代表是否返回区间标签,默认false |
| precision | 接收int,显示标签的精度,默认3 |
precision这个参数在np.set_printoptions(precision=4,suppress=True)这里也有,哈哈哈哈哈啊哈,突然想起来,就是调精度的。
numpy精度问题贼烦!不调这个的话,使用numpy随便计算一个矩阵,都有可能算错。比如:看2.1.3这个栗子
price=pd.cut(detail['amounts'],7)
print('离散化7类售价分别的数量是:',price.value_counts())
诺,结果如下:

3.2.2等频法
其实就是利用bins参数的序列进行设置等频区间。
#自定义函数等频法
def sameratecut(data,k):
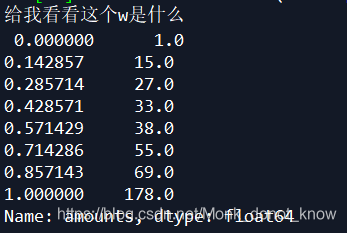
w=data.quantile(np.arange(0,1+1.0/k,1.0/k))
data=pd.cut(data,w)
print('给我看看这个w是什么','\n',w)
return data
# 看过w一眼就会明白,dataframe.quantile是设置分位数的函数。
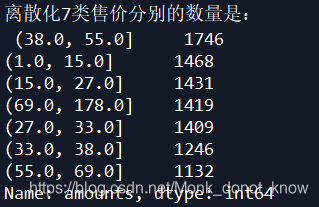
result=sameratecut(detail['amounts'],7).value_counts()
print('离散化7类售价分别的数量是:','\n',result)
这个dataframe.quantile()就是设置分位数的一个函数。
离散化结果如下:
3.3使用聚类分析等频离散化
def kmeancut(data,k):
from sklearn.cluster import KMeans
# 这个模型下一章sklearn介绍
kmodel=KMeans(n_clusters=k,n_jobs=5)
kmodel.fit(data.values.reshape((len(detail['amounts']),1)))
# 输出聚类中心,这个是kmeans函数自带属性,可以直接help(KMeans)查看帮助文档下的Attributes
c=pd.DataFrame(kmodel.cluster_centers_).sort_values(0)
#这个就是排了个序,axis=0,列排序
w=c.rolling(2).mean().iloc[1:] #相邻两项求中点作为边界点
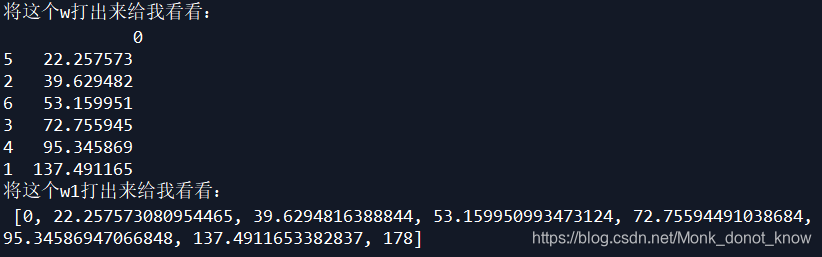
print('将这个w打出来给我看看:','\n',w)
w1=[0]+list(w[0])+[data.max()]
print('将这个w1打出来给我看看:','\n',w1)
data=pd.cut(data,w1)
return data
# 菜品售价等频离散化
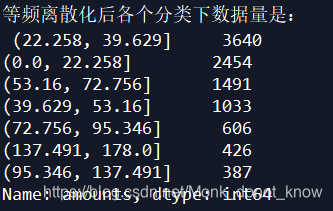
result=kmeancut(detail['amounts'],7).value_counts()
print('等频离散化后各个分类下数据量是:','\n',result)
pd.rolling_mean的使用方法在这里
但是啊,这个方法已经在新的pamdas里面不支持了,这本书有点过时,最新的使用方法是写为:
pd.rolling_mean(D.2) --> D.rolling(2).mean()