商品搜索整合
实现步骤:
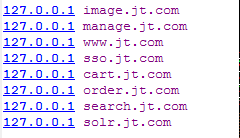
1.配置nginx和hosts文件
配置示例:
#全文搜索solr服务器
server {
listen 80;
server_name solr.jt.com;
#charset koi8-r;
#access_log logs/host.access.log main;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
location / {
proxy_pass http://192.168.234.234:8983;
proxy_connect_timeout 600;
proxy_read_timeout 600;
}
}
#全文搜索服务器
server {
listen 80;
server_name search.jt.com;
#charset koi8-r;
#access_log logs/host.access.log main;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
location / {
proxy_pass http://127.0.0.1:8086;
proxy_connect_timeout 600;
proxy_read_timeout 600;
}
}
hosts文件:
2.引入相关的pom依赖(添加到 jt-parent工程):
相关坐标:
<!-- solrj -->
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>5.2.1</version>
</dependency>
<!-- Lucene -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>5.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>5.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>5.2.1</version>
</dependency>
<!-- IK分词器 -->
<dependency>
<groupId>org.wltea.analyzer</groupId>
<artifactId>ik-analyzer</artifactId>
<version>5.3.0</version>
</dependency>
3.建立jt-search工程(web-app骨架),并添加jt-common工程,jt-dubbo工程的依赖

4.引入solr相关的配置文件
5.引入dubbo相关的配置文件
6.引入web.xml
7.在 jt-dubbo 工程自定义搜索服务的接口
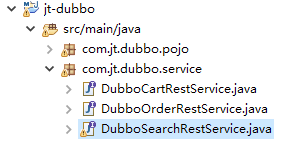
8.在 jt-dubbo 工程下创建Item的pojo类
Item类代码:
@JsonIgnoreProperties(ignoreUnknown=true)
public class Item extends BasePojo{
@Field(“id”)
private Long id;
@Field(“title”)
private String title;
@Field(“sellPoint”)
private String sellPoint;
@Field(“price”)
private Long price;
@Field(“image”)
private String image;
private String[] images;
9.配置 jt-search的 tomcat端口,启动测试 (8086端口)
全文检索商品
所在工程 jt-web
SearchController代码:
@Controller
public class SearchController {
@Autowired
private DubboSearchRestService dubboSearchRestService;
//http://www.jt.com/search.html?q=
@RequestMapping("/search")
public String search(String q,@RequestParam(defaultValue="1")Integer page,Model model) throws Exception{
//防止中文转页面时乱码
q = new String(q.getBytes("ISO-8859-1"),"UTF-8");
//设定每页显示的数据
int rows=20;
List<Item> itemList=dubboSearchRestService.getItemListBySearch(q,page,rows);
model.addAttribute("itemList", itemList);
model.addAttribute("query", q);
return "search";
}
}
所在工程 jt-dubbo
DubboSearchRestService接口代码:
@Path("search")
@Consumes({MediaType.APPLICATION_JSON,MediaType.TEXT_XML})
@Produces({ContentType.APPLICATION_JSON_UTF_8,ContentType.TEXT_XML_UTF_8})
public interface DubboSearchRestService {
@POST
@Path("item")
List<Item> getItemListBySearch(
@QueryParam(value="q")String q,
@QueryParam(value="page")Integer page,
@QueryParam(value="rows")int rows);
}
所在工程 jt-search
DubboSearchRestServiceImpl代码:
public class DubboSearchRestServiceImpl implements DubboSearchRestService{
@Autowired
private HttpSolrServer httpSolrServer;
@Override
public List<Item> getItemListBySearch(String q, Integer page, int rows) {
SolrQuery solrQuery=new SolrQuery();
solrQuery.setQuery(q);
//设置分页数据
solrQuery.setStart((page-1)*rows);
solrQuery.setRows(rows);
try {
QueryResponse queryResponse=httpSolrServer.query(solrQuery);
List<Item> itemList=queryResponse.getBeans(Item.class);
return itemList;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
}
注:修改search.jsp页面代码
爬虫介绍
概念介绍
爬虫是一种自动获取网页内容的程序,是搜索引擎的重要组成部分。
爬虫为搜索引擎从万维网上下载网页。
爬虫分为通用爬虫和聚焦爬虫
通用爬虫:例如Google,百度等爬虫,获取的是整个万维网的网页资源。
聚焦爬虫:是有选择的访问万维网上的网页与相关的链接,获取所需要的信息。聚焦爬虫并不追求大的覆盖,而将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
防采集
防采集,也称为防爬虫(反爬虫)是指屏蔽特定的搜索引擎的爬虫,一是为节省网站带宽,二是避免网站被恶意抓取页面。
当你采集某个网站数据一段时间之后,你就发现不让你采集数据了,简单来讲,网站为了防止自己的数据被机器程序大规模采集,而采取了一系列技术手段来限制采集。
常见的防采集手段有:
1)登录
2)封IP
3)验证码
4)Ajax异步加载
这些方法都非常有效,一般采集工具碰到这些的时候大多都歇菜了
爬虫的应用
互联网总是需要爬虫的,并且在大数据中,爬虫解决了数据源头问题,很关键。
Jsoup介绍
介绍
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。所以可以用来开发爬虫程序。
目前最常用的是利用Python来做爬虫,大数据阶段会讲到。
此外,也可以利用成熟且免费的爬虫工具,比如八爪鱼。
Jsoup API
获取document内容:
/*
* 1.明确目标站的链接地址
* 2.获取网页标签
* 3.解析想要的标签
* 本例中以新浪为抓取对象 ——http://www.sina.com.cn/
*/
@Test
public void testFetchSiteAll() throws Exception{
String url="http://blog.sina.com.cn/s/blog_e39f2af40102wwh6.html?tj=1";
Connection cn=Jsoup.connect(url);
//doc代表获取的网页对象
Document doc=cn.get();
}
抓取标题:
/*
* 定向抓取标题
* 对于抓取的内容的格式,分如下几种:
* 1.html
* 2.文本(json和jsonp格式)
*
* 本例是抓取京东商城 https://item.jd.com/5188000.html 手机商品的标题
*
*/
@Test
public void testFetchTitle() throws Exception{
String url="https://item.jd.com/5188000.html";
Connection cn=Jsoup.connect(url);
Document doc=cn.get();
//注意,如果是class,需要加点 。如果是标签,就直接写标签名
//Element el=doc.select(".sku-name").get(0);
//也可以通过多层级来定位,更精准,但注意用空格隔开
Element el=doc.select(".itemInfo-wrap .sku-name").get(0);
System.out.println(el.text());
}
抓取价格:
/*
* 抓取价格
* jsoup的缺点:如果jsoup抓取的页面,当页面加载完成后的数据ajax获取形成的,是抓取不到的。
*/
@Test
public void testFetchPrice() throws Exception{
String url="https://item.jd.com/4611415.html";
Connection cn=Jsoup.connect(url);
Document doc=cn.get();
// p-price J-p-4611415
//注意下面的写法。
Elements els=doc.select(".p-price").select(".J-p-4611415");
for(Element el:els){
System.out.println(el);
}
}
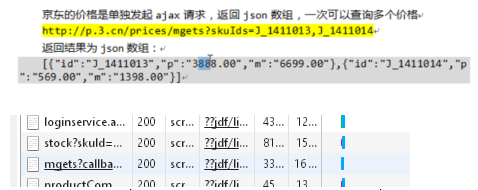
抓取商品价格2:
http://p.3.cn/prices/mgets?skuIds=J_3479621
抓取某个页面上所有商品标题:
/*
* 抓取京东手机某一页面上所有商品标题
*/
@Test
public void testFetchAllTitles() throws Exception{
String url="https://shouji.jd.com/";
Connection cn=Jsoup.connect(url);
Document doc=cn.get();
Elements els=doc.select(".p-name");
for(Element el:els){
System.out.println(el.text());
}
}
抓取商品介绍:
private ObjectMapper MAPPER=new ObjectMapper();
/*
*抓取商品详情介绍
*本例中,返回的是jsonp形式
*
*/

@Test
public void testFetchImage() throws Exception{
String url="http://d.3.cn/desc/3133829";
Connection cn=Jsoup.connect(url);
//因为此时返回不是html页面,所以不能用document来接。
String jsonp=cn.ignoreContentType(true).execute().body();
String json=jsonp.substring(9, jsonp.length()-1);
JsonNode jn=MAPPER.readTree(json);
String desc=jn.get("content").asText();
System.out.println(desc);
}
}
Jsoup爬取京东商品数据
抓取京东的所有3级商品分类的连接
/*
* ①抓取京东的所有3级商品分类的连接
*/
@Test
public void fetch_Jd_All_Level_3_ItemCat() throws Exception{
String url="https://www.jd.com/allSort.aspx";
Connection con=Jsoup.connect(url);
List<String> urlList=new ArrayList<>();
Document doc=con.get();
Elements els=doc.select(".clearfix dd a");
for(Element el:els){
String itemCatUrl=el.attr("href");
if(itemCatUrl.startsWith("//list.jd.com/list.html?cat=")){
urlList.add(itemCatUrl);
}
}
}
获取某个商品分类总的分页数量:
/*
* 获取某个商品分类总的分页数量
*/
@Test
public void fetch_oneItemCat_ALLTitle() throws Exception{
String url="http://list.jd.com/list.html?cat=737,1276,742";
Connection con=Jsoup.connect(url);
Document doc=con.get();
Element el=doc.select(".p-skip em b").get(0);
String pageMax=el.text();
}
获取某个商品分类所有页的商品标题数据
@Test
public void fetch_oneItemCat_ALLTitle() throws Exception{
String url="http://list.jd.com/list.html?cat=1713,4855,4882";
Connection con=Jsoup.connect(url);
Document doc=con.get();
Element el=doc.select(".p-skip em b").get(0);
String pageMax=el.text();
List<String> titleList=new ArrayList<>();
for(int i=0;i<Integer.parseInt(pageMax);i++){
String itemUrlWithPage="http://list.jd.com/list.html?cat=737,1276,742&"+i;
Connection c1=Jsoup.connect(itemUrlWithPage);
Document d=c1.get();
Elements title_els=d.select(".p-name");
for(Element title_el:title_els){
titleList.add(title_el.text());
}
}
}
爬取所有的商品分类标题:
@Test
public void fetch_allItemCat_allTitleInfo() throws Exception{
String url="https://www.jd.com/allSort.aspx";
Connection con=Jsoup.connect(url);
List<String> urlList=new ArrayList<>();
Jedis jedis=new Jedis("192.168.234.131",6379);
Document doc=con.get();
Elements els=doc.select(".clearfix dd a");
for(Element el:els){
String itemCatUrl=el.attr("href");
if(itemCatUrl.startsWith("//list.jd.com/list.html?cat=")){
urlList.add("http:"+itemCatUrl);
}
}
for(String itemCatUrl:urlList){
Connection itemCatConnection=Jsoup.connect(itemCatUrl);
Document itemCatDoc=itemCatConnection.get();
Element pageMaxEl=itemCatDoc.select(".p-skip em b").get(0);
int pageMax=Integer.parseInt(pageMaxEl.text());
for(int i=0;i<pageMax;i++){
String itemUrlWithPage=itemCatUrl+"&"+i;
Connection itemConWithPage=Jsoup.connect(itemUrlWithPage);
Document itemDoc=itemConWithPage.get();
Elements title_els=itemDoc.select(".p-name");
for(Element title_el:title_els){
jedis.lpush("jt-itemtitle",title_el.text());
}
}
}
}
/*
* 查看redis的list数据
*/
@Test
public void getDataFromRedis(){
Jedis jedis=new Jedis("192.168.234.131",6380);
Long count=jedis.llen("jt-itemtitle");
Set<String> keys=jedis.keys("*");
for(int i=0;i<count;i++){
System.out.println(jedis.lindex("jt-itemtitle", i));
}
}
Jsoup Select用法
1.通过标签名来查找:
测试代码:
<span>33</span>
<span>25</span>
select写法:
Elements elements = document.select("span");
2.通过id来查找:
<span id="mySpan">36</span>
<span>20</span>
Elements elements = document.select("#mySpan");
//通过id来查找,使用方法跟css指定元素一样,用#
3.通过class名来查找:
<span class="myClass">36</span>
<span>20</span>
Elements elements = document.select(".myClass");
//使用方法跟css指定元素一样,用.
4.利用标签内属性名查找元素:
<span class="class1" id="id1">36</span>
<span class="class2" id="id2">40</span>
Elements elements = document.select("span[class=class1]span[id=id1]");
//规则为 标签名【属性名=属性值】,多个属性即多个【】,如上
5.利用标签内属性名前缀查找元素:
<span class="class1" >36</span>
<span class="class2" >22</span>
Elements elements = document.select("span[^cl]");
//规则为 标签名【^属性名前缀】,多个属性即多个【】
6.利用标签内属性名+正则表达式查找元素
<span class="ABC" >36</span>
<span class="ADE" >22</span>
Elements elements = document.select("span[class~=^AB]");
//规则为 标签名【属性名~=正则表达式】,以上的正则表达式的意思是查找class值以AB为开头的标签
7.利用标签文本包含某些内容来查找:
<span>36</span>
<span>22</span>
Elements elements = document.select("span:contains(3)");
//规则为 标签名:contains(文本值)
8.利用标签文本包含某些内容+正则表达式来查找:
<span>36</span>
<span>22</span>
Elements elements = document.select("span:matchesOwn(^3)");
//规则为 标签名:matchesOwn(正则表达式),以上的正则表式的意思是以文本值以3为开头的标签
至此分布式项目阶段已完结,请关照后续的持续项目