以爬取百度首页为例子
直接上代码
import requests
url="http://www.baidu.com"
html=requests.get(url).text
print(html)
输出结果乱码,可这是为什么呢?很明显是编码问题造成的
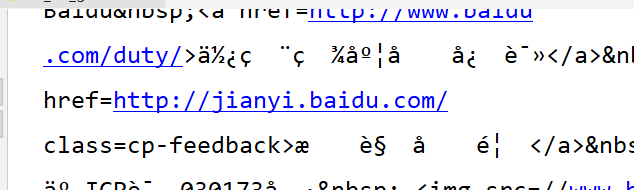
我们去百度看下网页源码,编码为utf-8

然而我们的编译器,采用的也是utf-8,都是utf-8为什么会乱码呢?这时候就想到了,直接输出百度首页的编码方式
import requests
import sys
//输出我们编译器所用的编码
print(sys.getdefaultencoding())
url="http://www.baidu.com"
html=requests.get(url)
//输出百度的编码
print(html.encoding)
输出结果如下
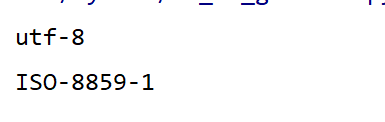
乖乖,进入是ISO-8859-1,不是utf-8,可这个是为什么呢,可能是由于网页压缩问题,我也是瞎猜的,哈哈。
那么我们就来用谷歌浏览器查看下该网页是否被压缩
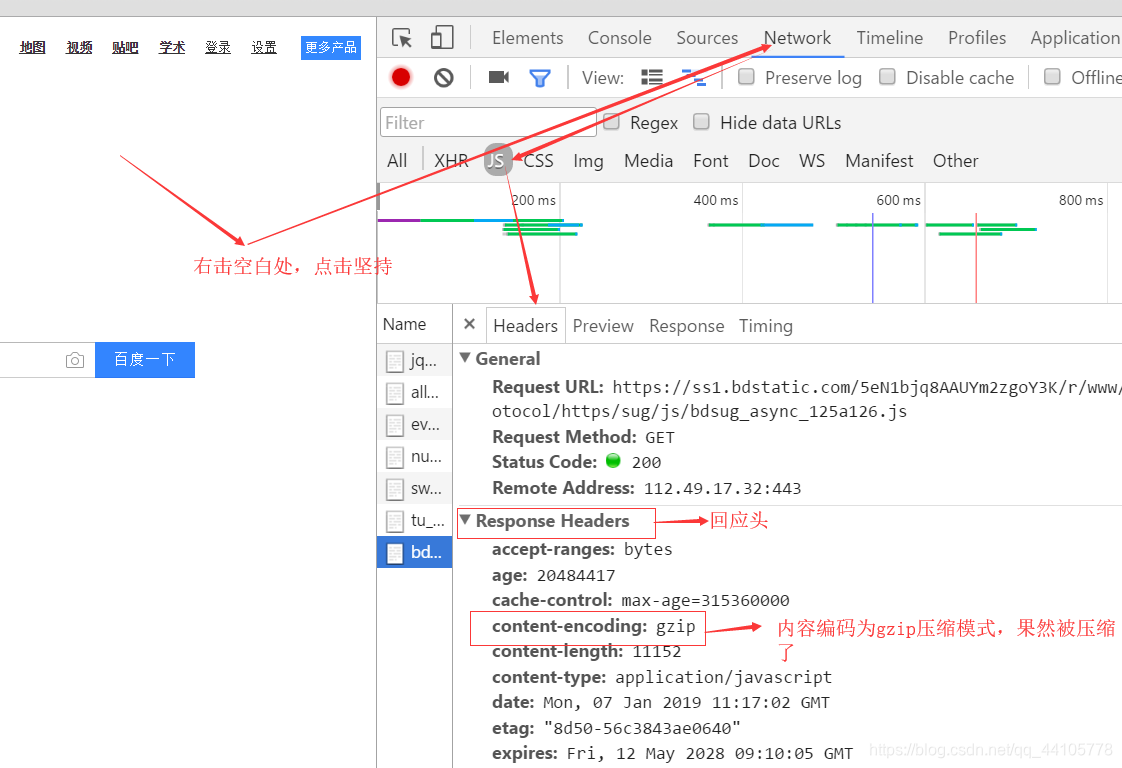
接下来我们就进行编码转化
import requests
url="http://www.baidu.com"
html=requests.get(url).text
#encode解码,将ISO-8859-1解码成unicode
html=html.encode("ISO-8859-1")
#decode编码,将unicode编码成utf-8
html=html.decode("utf-8")
print(html)
问题解决