教程目录
0x00 教程内容
- 环境及资源准备
- 生成容器
- 检验Hadoop与Spark
0x01 环境及资源准备
1. 安装Docker
请参考:D001.5 Docker入门(超级详细基础篇)的“0x01 Docker的安装”小节
2. 准备资源
a. 根据文末总结的文件目录结构,拷贝文章的资源,资源请参考:D001.6 Docker搭建Hadoop集群
b. 模仿Hadoop自己写一份,或者后期关注代码库:
邵奈一的学习库
c. Dockerfile参考文件
FROM ubuntu
MAINTAINER shaonaiyi [email protected]
ENV BUILD_ON 2017-11-16
RUN apt-get update -qqy
RUN apt-get -qqy install vim wget net-tools iputils-ping openssh-server
#添加JDK
ADD ./jdk-8u161-linux-x64.tar.gz /usr/local/
#添加hadoop
ADD ./hadoop-2.7.5.tar.gz /usr/local/
#添加scala
ADD ./scala-2.11.8.tgz /usr/local/
#添加spark
ADD ./spark-2.2.0-bin-hadoop2.7.tgz /usr/local/
ENV CHECKPOINT 2019-01-14
#增加JAVA_HOME环境变量
ENV JAVA_HOME /usr/local/jdk1.8.0_161
#hadoop环境变量
ENV HADOOP_HOME /usr/local/hadoop-2.7.5
#scala环境变量
ENV SCALA_HOME /usr/local/scala-2.11.8
#spark环境变量
ENV SPARK_HOME /usr/local/spark-2.2.0-bin-hadoop2.7
#将环境变量添加到系统变量中
ENV PATH $SCALA_HOME/bin:$SPARK_HOME/bin:$HADOOP_HOME/bin:$JAVA_HOME/bin:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$PATH
RUN ssh-keygen -t rsa -f ~/.ssh/id_rsa -P '' && \
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys && \
chmod 600 ~/.ssh/authorized_keys
#复制配置到/tmp目录
COPY config /tmp
#将配置移动到正确的位置
RUN mv /tmp/ssh_config ~/.ssh/config && \
mv /tmp/profile /etc/profile && \
mv /tmp/masters $SPARK_HOME/conf/masters && \
cp /tmp/slaves $SPARK_HOME/conf/ && \
mv /tmp/spark-defaults.conf $SPARK_HOME/conf/spark-defaults.conf && \
mv /tmp/spark-env.sh $SPARK_HOME/conf/spark-env.sh && \
mv /tmp/hadoop-env.sh $HADOOP_HOME/etc/hadoop/hadoop-env.sh && \
mv /tmp/hdfs-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml && \
mv /tmp/core-site.xml $HADOOP_HOME/etc/hadoop/core-site.xml && \
mv /tmp/yarn-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml && \
mv /tmp/mapred-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml && \
mv /tmp/master $HADOOP_HOME/etc/hadoop/master && \
mv /tmp/slaves $HADOOP_HOME/etc/hadoop/slaves && \
mv /tmp/start-hadoop.sh ~/start-hadoop.sh && \
mkdir -p /usr/local/hadoop2.7/dfs/data && \
mkdir -p /usr/local/hadoop2.7/dfs/name
RUN echo $JAVA_HOME
#设置工作目录
WORKDIR /root
#启动sshd服务
RUN /etc/init.d/ssh start
#修改start-hadoop.sh权限为700
RUN chmod 700 start-hadoop.sh
#修改root密码
RUN echo "root:shaonaiyi" | chpasswd
CMD ["/bin/bash"]
0x02 生成容器
1. 生成样本镜像
a. 切换成root用户(密码:shaonaiyi)
su root

b. 拷贝资源文件spark_sny_all进到docker_bigdata目录(如有则不用创建)
mkdir docker_bigdata

c. 生成样本镜像:shaonaiyi/spark
cd docker_bigdata/spark_sny_all
docker build -t shaonaiyi/spark .
此过程时间根据自己网络情况与自己装docker时的配置有关(10分钟左右)

出现下图表示成功:

2. 创建bigdata-spark网络
a. 修改脚本权限
chmod 700 build_network.sh
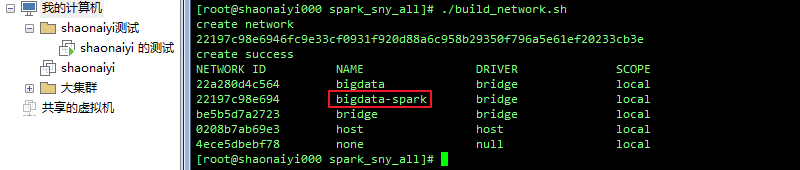
b. 创建网络
./build_network.sh
修改及创建后如图:
3. 启动容器
a. 修改脚本权限
cd config
chmod 700 start_containers.sh
b. 启动容器(映射的端口多的为master)
./start_containers.sh

0x03 检验Hadoop与Spark
1. 启动Hadoop与Spark
a. 查看启动的容器(显示跟刚刚一样)
docker ps
b. 进入容器hadoop-master(可用自己的容器ID)
docker attach hadoop-master
c. 修改脚本执行权限
ll
d. 启动Hadoop集群
./start-hadoop.sh
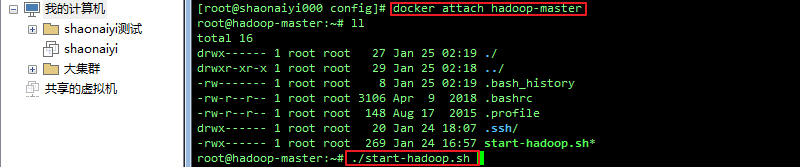
无报错,且有进程(如报错可以重新生成容器试试):

2. Web UI界面查看
a. 切换终端,查看端口映射(可看到51070端口映射到docker的50070端口)
docker port hadoop-master

b. 在我们的windows系统执行(虚拟机的ip:port)
ps:自行修改ip



2. 停止并删除容器指令
a. 修改脚本权限
cd /home/shaonaiyi/docker_bigdata/spark_sny_all/config/
chmod 700 stop_containers.sh
b. 删除容器
./stop_containers.sh
c. 查看执行的容器(没有则表示删除成功)
docker ps

0xFF 总结
- 如需要获取资源,可加微信:shaonaiyi888获取最新消息
- 本文为搭建Spark与Hadoop集群的实践篇,与上一篇有异曲同工之处:
D001.7 Docker搭建Hadoop集群(实践篇) - 本次教程使用了ubuntu镜像,可在docker hub官网搜索指定的版本:https://hub.docker.com/
- 后期会出教程:
a. 在集群内部传统模式安装HBase
b. 使用Dockerfile方式安装HBase
测试机ip为:192.168.128.128
非测试机为:192.168.128.129
有些时候使用测试机,有时候使用非测试机
读者请自行修改!
作者简介:邵奈一
大学大数据讲师、大学市场洞察者、专栏编辑
公众号、微博、CSDN:邵奈一
本系列课均为本人:邵奈一 原创,如转载请标明出处