distill_basic_teacher
- torch.manual_seed(args.seed) 为CPU设置种子用于生成随机数,以使得结果是确定的
- 在定义网络的时候,如果层内有Variable,那么用nn定义,反之,则用nn.functional定义
- What does torch.backends.cudnn.benchmark do?
It enables benchmark mode in cudnn.It enables benchmark mode in cudnn.
benchmark mode is good whenever your input sizes for your network do not vary. This way, cudnn will look for the optimal set of algorithms for that particular configuration (which takes some time). This usually leads to faster runtime.
But if your input sizes changes at each iteration, then cudnn will benchmark every time a new size appears, possibly leading to worse runtime performances.
输入大小不变时,cudnn可以找到算法最优的参数组合,以加快运行时间。但输入大小在每个循环中改变时,cudnn每次都要改变基准,可能使运行时间变得更慢。 - 在主函数中加上一句
用以保证实验的可重复性,果然,两次运行的结果完全一致torch.backends.cudnn.deterministic = True
transform_train = transforms.Compose(
[
transforms.RandomCrop(mnist_image_shape, random_pad_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5), (0.5, 0.5))
]
)
class torchvision.transforms.Compose(transforms)
将多个transform组合起来使用。
class torchvision.transforms.RandomCrop(size, padding=0)
将给定的PIL.Image进行中心切割。切割中心点的位置随机选取。size可以是tuple也可以是Integer。
class torchvision.transforms.ToTensor
把一个取值范围是[0,255]的PIL.Image或者shape为(H,W,C)的numpy.ndarray,转换成形状为[C,H,W],取值范围是[0,1.0]的torch.FloadTensor
class torchvision.transforms.Normalize(mean, std)
给定均值:(R,G,B) 方差:(R,G,B),将会把Tensor正则化。即:Normalized_image=(image-mean)/std。
train_val_loader = torch.utils.data.DataLoader(train_val_dataset, batch_size=128, shuffle=True, num_workers=2)
num_workers (int, optional): how many subprocesses to use for data loading. 0 means that the data will be loaded in the main process.有多少子进程用来加载数据
for hparam_tuple in itertools.product(dropout_probabilities, weight_decays, learning_rate_decays,
momentums, learning_rates):
hparam = {}
hparam['dropout_input'] = hparam_tuple[0][0]
hparam['dropout_hidden'] = hparam_tuple[0][1]
hparam['weight_decay'] = hparam_tuple[1]
hparam['lr_decay'] = hparam_tuple[2]
hparam['momentum'] = hparam_tuple[3]
hparam['lr'] = hparam_tuple[4]
hparams_list.append(hparam)
itertools.product(dropout_probabilities, weight_decays, learning_rate_decays,momentums, learning_rates)
>>> import itertools
>>> itertools.product([1,2,3],[100,200])
<itertools.product object at 0x7f3e6dd7bc80>
>>> for item in itertools.product([1,2,3],[100,200]):
... print item
...
(1, 100)
(1, 200)
(2, 100)
(2, 200)
(3, 100)
(3, 200)
product(list1, list2) 依次取出list1中的每1个元素,与list2中的每1个元素,组成元组,
然后,将所有的元组组成一个列表,返回。
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=hparam['lr_decay'])
class torch.optim.lr_scheduler.StepLR(optimizer,step_size,gamma=0.1,last_epoch=-1)
设置每个参数组的学习率为 ,当last_epoch=-1时,令lr=lr
参数:
optimizer(Optimizer对象)--优化器
step_size(整数类型): 调整学习率的步长,每过step_size次,更新一次学习率
gamma(float 类型):学习率下降的乘数因子
last_epoch(int类型):最后一次epoch的索引,默认为-1.
示例:
>>> # Assuming optimizer uses lr = 0.05 for all groups
>>> # lr = 0.05 if epoch < 30
>>> # lr = 0.005 if 30 <= epoch < 60
>>> # lr = 0.0005 if 60 <= epoch < 90
>>> # ...
>>> scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
>>> for epoch in range(100):
>>> scheduler.step()
>>> train(...)
>>> validate(...)
先scheduler.step(),再train和validate。
nn.KLDivLoss

KL 散度,又叫做相对熵,算的是两个分布之间的距离,越相似则越接近零。
注意这里的 Xi 是 log概率.
nn.CrossEntropyLoss
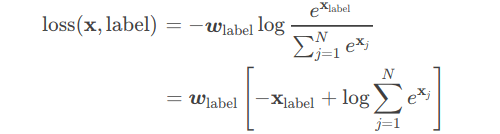
多分类用的交叉熵损失函数,用这个 loss 前面不需要加 Softmax 层。
且作用于结果和真实的标签之间。y必须是label。
Variable所在库
from torch.autograd import Variable
1、softmax
第i个 Softmax(x) 的组成是 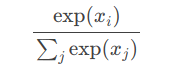
2、log_softmax
在softmax的结果上再做多一次log运算
While mathematically equivalent to log(softmax(x)), doing these two
operations separately is slower, and numerically unstable. This function
uses an alternative formulation to compute the output and gradient correctly.
用更高效的方式实现 log(softmax(x))
import torch
import torch.autograd as autograd
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
data=autograd.Variable(torch.FloatTensor([1.0,2.0,3.0]))
log_softmax=F.log_softmax(data,dim=0)
print(log_softmax)
softmax=F.softmax(data,dim=0)
print(softmax)
np_softmax=softmax.data.numpy()
log_np_softmax=np.log(np_softmax)
print(log_np_softmax)
3、nll_loss
用于多分类的负对数似然损失函数(Negative Log Likelihood)
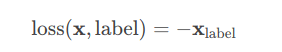
在前面接上一个 nn.LogSoftMax 层就等价于交叉熵损失了。事实上,nn.CrossEntropyLoss 也是调用这个函数。注意这里的 xlabelxlabel 和上个交叉熵损失里的不一样(虽然符号我给写一样了),这里是经过 logSoftMaxlogSoftMax 运算后的数值
1.1 loss = F.nll_loss(output, target) # the official default loss, log_softmax + nll_loss = cross entropy loss
1.2 loss = F.nll_loss(output, target, reduction=‘sum’)/batch_size
1.3 loss = F.nll_loss(output, target, reduction=‘sum’)
1.1和1.2的实现方式本质相同,1.1output如果是经过了log_softmax的作用,则相同于cross entropy loss,1.2和1.3中1.2是正确的,1.3相当于将loss放大了batch_size倍,等同于将learning rate设置成batch_size,导致结果不正确。
4、CrossEntropyLoss
weight = torch.Tensor([1,2,1,1,10])
loss_fn = torch.nn.CrossEntropyLoss(reduce=False, size_average=False, weight=weight)
input = Variable(torch.randn(3, 5)) # (batch_size, C)
target = Variable(torch.FloatTensor(3).random_(5))
#改为 target = Variable(torch.empty(3, dtype=torch.long).random_(5))
loss = loss_fn(input, target)
print(input); print(target); print(loss)
报错 RuntimeError: Expected object of scalar type Long but got scalar type Float for argument #2 ‘target’
解决方式:改为注释中的代码
return:
tensor([[-0.2921, 1.3323, 0.8146, 0.5525, 0.6106],
[-0.8828, -0.0712, 1.0634, 1.1096, 0.4252],
[ 2.8773, 0.1807, 0.8415, -0.0305, -1.3431]])
tensor([0, 4, 2])
tensor([ 2.6314, 17.5005, 2.2726])
保存模型
-
先建立一个字典,保存三个参数:
state = {‘net’:model.state_dict(), ‘optimizer’:optimizer.state_dict(), ‘epoch’:epoch}
-
调用torch.save():
torch.save(state, dir)
其中dir表示保存文件的绝对路径+保存文件名,如’/home/qinying/Desktop/modelpara.pth’
也可保存模型结果等等,放在字典中
save_path = checkpoints_path + utils.hparamToString(hparam) + '_final.tar'
torch.save({'results' : results[hparam_tuple],
'model_state_dict' : teacher_net.state_dict(),
'epoch' : num_epochs}, save_path)
.tar是linux下的压缩包形式
调用模型
当你想恢复某一阶段的训练(或者进行测试)时,那么就可以读取之前保存的网络模型参数等。
model必须要先初始化好。
checkpoint = torch.load(dir)
model.load_state_dict(checkpoint[‘net’])
optimizer.load_state_dict(checkpoint[‘optimizer’])
start_epoch = checkpoint[‘epoch’] + 1
load_path = checkpoints_path_teacher + utils.hparamToString(hparams_list[0]) + '_final.tar'
teacher_net = networks.TeacherNetwork()
teacher_net.load_state_dict(torch.load(load_path, map_location=fast_device)['model_state_dict'])
distill_basic_student
Loss是两者的结合,Hinton认为,最好的训练目标函数就是这样,并且第一个目标函数的权重要大一些。
def studentLossFn(teacher_pred, student_pred, y, T, alpha):
"""
Loss function for student network: Loss = alpha * (distillation loss with soft-target) + (1 - alpha) * (cross-entropy loss with true label)
Return: loss
"""
if (alpha > 0):
loss = F.kl_div(F.log_softmax(student_pred / T, dim=1), F.softmax(teacher_pred / T, dim=1), reduction='batchmean') * (T ** 2) * alpha + F.cross_entropy(student_pred, y) * (1 - alpha)
else:
loss = F.cross_entropy(student_pred, y)
return loss
模型结构图