目录
- 统计学基本知识梳理
- 离散变量的概率分布
- 大数定律
- 正态分布
第一部分—统计学基本知识梳理
这一部分是关于统计学的基本知识,包括数据的可视化:饼图、条形图、直方图、箱型图,以及几种常见的统计量,包括:均值、中位数、众数、全距、四分位数、方差、标准差。
信息图形化
图形是发现数据隐含模式的一种有效方法,通过图形,数据得以直观的体现。基本的图表形式如下:
- 饼图 :每个扇形的大小代表你所展示的每组数据的相对频率,一般早在对基本比例进行比较时较为有效,所使用的数据为不同组别。
- 条形图:条形图中的每一个长方形代表一个特定类,长方形的长度代表某种数值。长方形越大,数值越大,包括垂直条形图和水平条形图,处理的数据为类别数据;
- 直方图:直方图与条形图外观相似,但有两个区别:每个长方形的面积与频数成比例,图上的长方形没有间隔,处理的数据为数值型数据;
- 箱型图:箱形图,也叫盒须图,盒式图,boxplot,箱型图能够做到:直观明了地识别数据批中的异常值,利用箱线图判断数据批的偏态和尾重,利用箱线图比较几批数据的形状;
注:这是小论文里做算法性能评价指标那一块用到的,这是Spcing指标, 很实用。相关资料详情请参考:https://blog.csdn.net/qq_40587575/article/details/80215776
几种常见的统计量
从一大堆数字中看出模式和趋势颇为不易,而求出平均值往往是把握全局的第一步。有了平均数就能迅速的找出数据中最具代表性的数值,得出重要结论。常见的统计量包括:
1.均值:其与平均数不是同一个统计量,平均数包括均值,均值的计算方法是:
当一组数据相差不大时,使用均值能较好的表示数据的总体情况,但数据中一旦存在异常值时,均值将会出现偏差;
2.中位数:当偏斜数据和异常值出现时,我们采用除了均值以外的另一个平均数,将数据升序排列,然后取中间的数,如果有奇数个数,则中位数为位于中间的数值,如果有偶数个数,则将中间两个数相加,然后除以2;
3.众数:如果数据看上去体现了多种趋势或多批数据,那么我们就需要为每一批数据给出一个众数。众数是一组数据中出现次数最多的数值。
4.全距:也叫极差,可以衡量数据的分散情况,计算方法是:用数据集中的最大数减去数据集中的最小数。全距仅仅描述了数据的宽度,并没有描述数据在上下界之间的分布。
5.四分位数:为了消除异常值的影响,采用四分位数,其将数据一分为四,最小的四分位数下四分位数(Q1),最大的四分位数称为上四分位数(Q3),中间的四分位数为中位数,四分位距=上四分位数—下四分位数。
6.方差:能够度量数据的变异性,公式:
7.标准差:方差开根号就是标准差。除了基本公式以外,还有一个方差速算法:
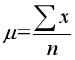
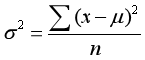
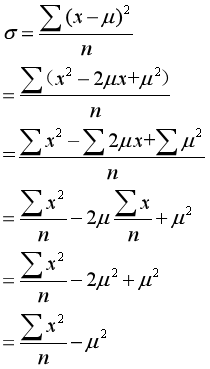
第二部分—离散变量的概率分布
这一部分主要总结的是离散变量的概率分布,包括二项分布、泊松分布。
二项分布
1.形式:
2.适用条件:
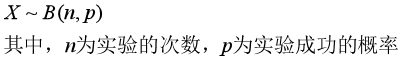
- 所进行的是一系列独立的实验;
- 每一次实验都存在失败和成功的可能,每一次实验的成功概率相同;
- 实验次数有限;
3.公式:
写作:X~B(n,p),其中,X表示“n次实验中成功的次数”,p是每一次实验成功的概率,n表示实验的次数。
4.期望和方差:
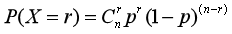
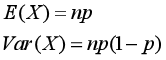
泊松分布
1.形式:
2.适用条件:
4. 单独事件在给定的区间内随机、独立的发生,给定区间可以是时间或空间,例如可以是一个星期,也可以是一英里;
5. 已知该区间内的事件平均发生的次数(或者叫发生率),且为有限值。

3.公式:
公式推导过程:
4.期望和方差:
相关扩展
6. 对于两个独立的随机的随机变量X,Y,
X+Y服从新的泊松分布,
7. 泊松分布和二项分布的关系(后续章节还有正态分布的转换):如果X~B(n,p),当n较大而p较小时,X可以近似表示成:
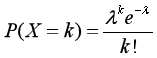

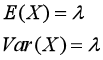
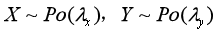
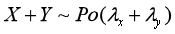
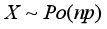
第三部分—大数定律
借用伯努利在结束《推测术》时就其结果的意义作的表述:“如果我们能把一切事件永恒地观察下去,则我们终将发现:世间的一切事物都受到因果律的支配,而我们也注定会在种种极其纷纭杂乱的现象中认识到某种必然。”
作为概率论中两个非常重要的定理,正是由于大数定律和中心极限定理是的存在,使得正态分布成为应用最为广泛的分布。大数定律的本质是一类极限定理,它是由概率的统计定义“频率收敛于概率”而来。基本定义为n个独立同分布的随机变量的观察值的均值依概率收敛于这些随机变量所属分布的理论均值,也就是总体均值。
定义:
设X1,X2,…,Xn是独立同分布的随机变量,记它们的公共均值为
。又设它们的方差存在并记为
。则对任意给定的ε>0,
这个式子指出了“当n很大时,
接近
”的确切含义。这里的“接近”是概率上的,也就是说虽然概率非常小,但还是有一定的概率出现意外情况(例如上面的式子中概率大于ε)。只是这样的可能性越来越小,这样的收敛性,在概率论中叫做“
依概率收敛于μ”。
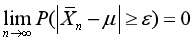
随机试验:
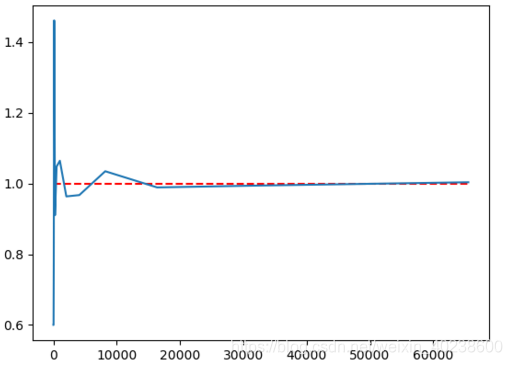
一枚硬币,正反两面,理论上正反出现的概率相等,100次实验正面应该出现50次,反面出现50次。利用MATLAB2017b编程进行实验,用random生成区间(0,1)之间的随机数,如果生成的数小于0.5,就记为硬币正面朝上,否则记为硬币反面朝上,统计正反面出现的次数之比,理论上试验次数越多(即抛硬币的次数越多),正反面出现的次数之比越接近于1(也就是说正反面各占一半).(等我有时间补上这个图)
此图源自网上,仅供学习参考。
随着实验次数的增加,正反面出现次数之比越来越接近于1,再次印证了大数定律。
第四部分—正态分布
前情回顾:
区别于之前的离散型概率分布,正态分布是一种连续性概率分布。区别在于:1.离散数据是一个个的确切值,往往能以某种方式进行计数,例如,机器在某一个特定时间段内的故障次数。2.连续数据涵盖的是一个范围,这个范围内的任何一个数值都有可能成为事件结果。总而言之,对于离散的概率分布来说,我们关心的是取得一个确定数值的概率,而对于离散的概率分布来说,我们关心的是取得一个特定范围的概率。
定义:
正态分布的概率密度函数为:
其中,
是均值,
是标准差。
特别的,标准正态分布的概率密度函数为:
此时,
=0,
=1,图像是关于x=0对称的。
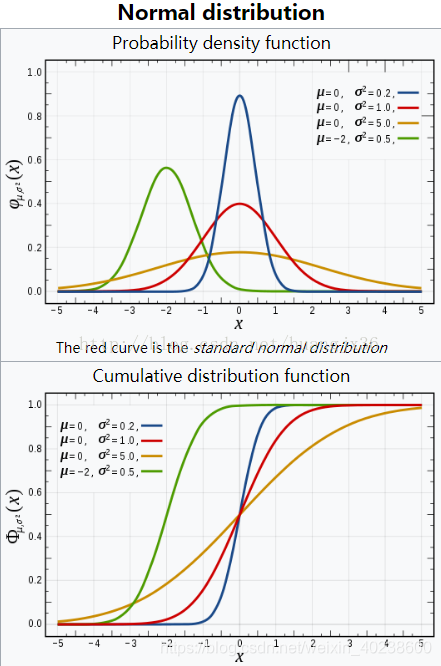
正态分布通过参数
和
进行定义,
是指曲线的中间位置,
指出分散性。如果一个连续随机变量X符合均值为
、标准差为
的正态分布,则通常写作X~N(
,
)。注意:
越大,数据分布的越分散,正态分布曲线越扁平、越宽。
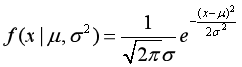
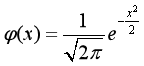
正态概率计算:
通常分为三步:
- 确定分布与范围:先确定数据分布能否用正态分布,能否求出均值和标准差,接着找出要求的区域面积;
- 标准化:就是将你的数据所服从的正态分布转换成标准正态分布X~N(0,1);
- 查找概率:一旦完成了标准化,就可以对照概率表进行查找;
标准分:一个变量的标准分即用这个变量减去其均值再除以这个变量的标准差的商,公式: ,标准分可将正态分布转换成N(0,1)分布。
正态分布的运用:
1.组合概率的计算
如果X和Y是独立的随机变量,且都符合正态分布,则符合
正态分布,即
则
2.线性变换和独立观察结果
线性变换影响概率分布中的基本数值,如果X符合正态分布,则aX+b也是正态分布,从而有
独立观察结果影响所处理事件的数量,和离散随机变量的独立观察结果类似,其期望和方差也有着同样的规律:
如果
,则
3.正态分布近似代替二项分布
比如有这么一道题:在40个问题中答对30道题以上的概率是多少?,如果使用二项分布来计算,将会十分复杂,二项分布的项和系数都很大。
When:关于什么时候用正态分布近似代替二项分布
一般来说,当
,有np和n(1-p)都大于5时,可以用正态分布替代二项分布。
How:关于如何用正态分布近似代替二项分布
当
,均值为np,方差为np(1-p),则可以使用
来近似替代二项分布。
注意:在计算近似值以前要先进行连续性修正
1.<=型概率求解
计算
的概率时,要确保所选择的范围中包含离散数值a,则需要计算P(X< a+0.5)。
2.>=型概率求解
计算
的概率时,则需要计算P(X> b-0.5)。
3.“介于”型概率的求解
计算
的概率时,则需要计算
4.正态分布近似代替泊松分布
比如有这么一道题:某一个网站预期发生的故障次数为每年40次,然后计算这个网站每年发生故障小于50次的概率?为了求出P(X< 50)的概率,我们需要求出50次以内所有X值分别对应的概率,非常费力
正态分布近似代替二项分布
如果
且
>15,则可用
来进行近似代替