Spring源码-context:component-scan的解析过程
上次已经讲过 Spring源码-applicationcontent.xml解析过程 ,先回顾一下,上次讲了applicationcontext.xml 是如何解析的,主要流程其实就是获取applicationcontent.xml输入流=》解析成Doc=》根据子节点(标签)的属性判断是自定义还是默认的标签=》根据标签的类别进行解析=》调用解析类进行解析。上篇文章没有着重讲到针对applicationcontent.xml中的标签是通过什么方式来解析的?及其解析流程是什么样的?所以在这里我将从Spring中比较重要的标签<context:component-scan base-package=""/> 入手,讲一讲这个标签的解析类是怎么去解析的。
1. 先贴出本次标签配置已经对应的标签的解析类
标签配置:
<!-- annotation-config="true" 这是默认值,所以可以省略 -->
<context:component-scan base-package="cn.edu.his.pay cn.edu.his.pay2" annotation-config="true">
<!-- 排除@Controller的注解 -->
<context:exclude-filter type="annotation" expression="org.springframework.stereotype.Controller"/>
</context:component-scan>标签的解析类:
ComponentScanBeanDefinitionParser#parse
2. 再贴出核心流程总结图
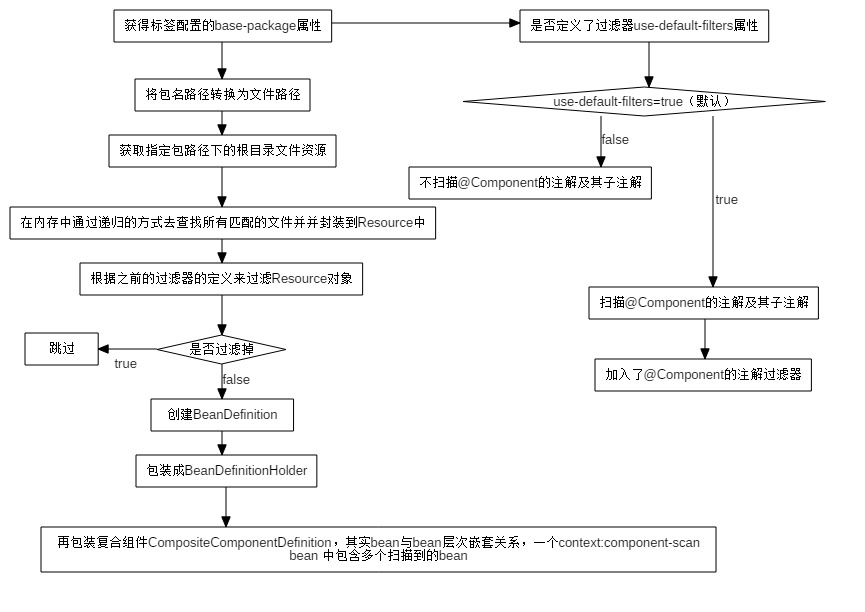
3. 如上已经对整个核心流程有一定的了解,那现在我们就针对开发中能遇到的一些问题进行源码层面的分析
1)如何配置多个包扫描路径?
正常我们都是用“,”来配置多个包扫描路径的,配置如下:
<context:component-scan base-package="cn.edu.his.pay,cn.edu.his.pay2">
</context:component-scan>但你阅读完源码后其实你会发现配置方式不止这一种,其实在根据base-package配置信息,使用到了StringTokenizer分割字符串,分割的规则是“,; \t\n”,如下是演示分割的代码:
package cn.edu.his.pay.controller.test;
import java.util.ArrayList;
import java.util.List;
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) {
StringTokenizer st = new StringTokenizer("cn.edu.his.pay cn.edu.his.pay2", ",; \t\n");
List<String> tokens = new ArrayList<>();
while (st.hasMoreTokens()) {
String token = st.nextToken();
if (true) {
token = token.trim();
}
if (!true || token.length() > 0) {
tokens.add(token);
}
}
System.out.println(tokens); //得到分割后的集合为 [cn.edu.his.pay, cn.edu.his.pay2]
}
}
其实可以得出,配置多路径扫描也可以用“,”、空格、“;”、“,;”来配置,扫描包得到的是一样的。
2)配置了context:component-scan标签后还需要配置context:annotation-config标签吗?
其实不用,因为context:component-scan标签中就对应context:annotation-config配置进行支持了,可以通过如下配置完成支持,其实这个annotation-config的属性还可以不设置,默认为true。
<!-- 不需要这样再配置了 -->
<!-- <context:annotation-config /> -->
<context:component-scan base-package="cn.edu.his.pay,cn.edu.his.pay2" annotation-config="true">
</context:component-scan>如下是相关部分源代码:
// 如有必要,注册注释配置处理器。
boolean annotationConfig = true;
if (element.hasAttribute(ANNOTATION_CONFIG_ATTRIBUTE)) {
annotationConfig = Boolean.valueOf(element.getAttribute(ANNOTATION_CONFIG_ATTRIBUTE));
}
if (annotationConfig) {
Set<BeanDefinitionHolder> processorDefinitions =
AnnotationConfigUtils.registerAnnotationConfigProcessors(readerContext.getRegistry(), source);
for (BeanDefinitionHolder processorDefinition : processorDefinitions) {
compositeDef.addNestedComponent(new BeanComponentDefinition(processorDefinition));
}
}3)配置了use-default-filters到底有什么用?
use-default-filters的配置方式如下,不配置默认该属性为true,默认会将@Component过滤器的注册。
<context:component-scan base-package="cn.edu.his.pay,cn.edu.his.pay2" use-default-filters="true">
</context:component-scan>这里配置use-default-filters=true其实就是让Spring过滤的时候将代码有@Component和@Component子注解的Class封装到BeanDefinition中。
4)那哪些是@Component的子注解了?
其实只要是注解上带有@Component的注解都是@Component的子注解。

5)我们经常在context:component-scan标签中定义子标签context:exclude-filter和context:include-filter 这又有什么用了?
其实这二个标签的用处还是挺多的,一般我们在配置配置文件的时候,都喜欢进行分层配置,比如:service的用一个my-service.xml,而mvc的我们用一个my-mvc.xml来单独配置,这个时候这二个标签就能用着了。这二个配置文件下都需要配置包扫描context:component-scan,所以这里为了避免重复扫描,可能会采用如下方式来配置:
my-service.xml
<context:component-scan base-package="cn.edu.his.pay">
<!-- 排除@Controller的注解 -->
<context:exclude-filter type="annotation" expression="org.springframework.stereotype.Controller"/>
</context:component-scan>my-mvc.xml
<context:component-scan base-package="cn.edu.his.pay">
<!-- 排除@Service的注解 -->
<context:exclude-filter type="annotation" expression="org.springframework.stereotype.Service"/>
</context:component-scan>简单的理解就是:context:exclude-filter(将包下带有指定类型指定注解的类进行过滤掉,不注册成BeanDefinition),context:include-filter(将包下带有指定类型指定注解的类进行注册成BeanDefinition),所以我们经常为了避免重复的去注册BeanDefinition而配置指定的过滤规则。