最近接触mysql实时数据采集与转储,以及后续的计算与分析项目,在此介绍了Canal框架的使用,基于Canal框架的架构设计和升级,对Canal1.1.0架构进行了优化。
ali canal简介
Canal是阿里巴巴mysql数据库中binlog的增量订阅消费组件。早期的增长是为了满足阿里跨机房同步的需求。有内部和外部版本的Canal。外部版本是开源版本。它只支持mysql和mysql core(mariadb)5.7及以下版本。
基于日志的增量订阅用户支持的业务:
数据库镜像
数据库实时备份
多级指数(买卖双方指数)
搜索生成
业务缓存刷新
价格变动及其他重要商业新闻
工作原理
MySQL主备复制的实现
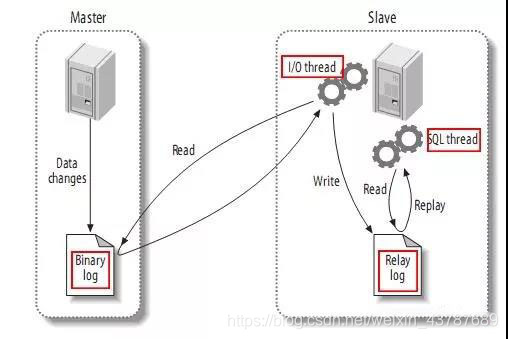
从高层来看,复制可以分为三个步骤:
主服务器将在二进制日志中记录更改(这些记录称为二进制日志事件,可以通过显示二进制日志事件来查看)。
从服务器将主服务器的二进制日志事件复制到其中继日志。
在中继日志中恢复事件,更改反映自身的数据。
很多小伙伴,对大数据的概念都是模糊不清的,大数据是什么,能做什么,学的时候,该按照什么线路去学习,学完往哪方面发展,想深入了解,想学习的同学欢迎加入大数据学习Qun:775908246,有大量干货(零基础以及进阶的经典实战)分享给大家,并且有清华大学毕业的资深大数据讲师给大家免费授课,给大家分享目前国内最完整的大数据高端实战实用学习流程体系。
canal原理:
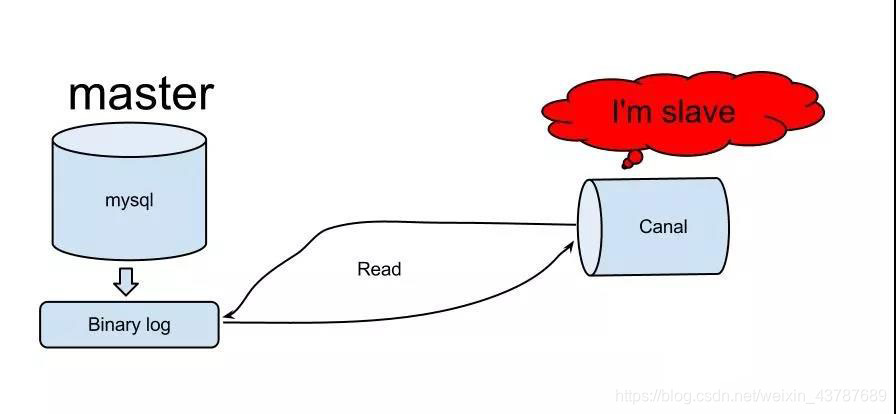
Canal模拟mysql slave的交互协议,伪装成mysql slave,发送dump协议给mysql master
mysql master接收到转储请求并开始将二进制日志推送到slave(即canal)
Canal解析二进制日志对象(最初是字节流)
架构设计
需要
事实上,这个要求非常简单。我们需要从MySQL中提取数据,将数据存储在Kafka中,并为后续程序提供数据存储或分析,但时间性要求实时性。
需求分析
根据以上要求,在进行总体设计时,从kafka获取数据进行计算和存储比较成熟,需要解决以前从mysql到kafka的数据存储问题。
从MySQL整体上获取数据有两种方法:
首先,您可以直接从MySQL中读取新数据,但这种方法不仅是判断新数据是否是新数据,而且还要考虑这种读取方法是否会影响其他用户的访问,而且很难实现实时性。
二是通过对mysql binlog的解析,解决了canal可以满足的实时数据提取和存储问题。然而,Canal不能直接储存在卡夫卡。它需要通过其他方式在卡夫卡中存储数据。
体系结构图
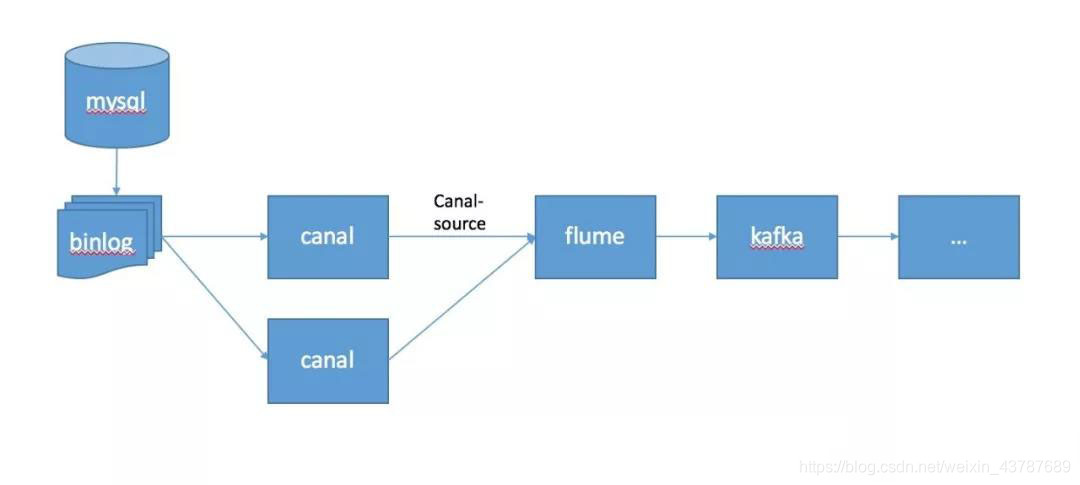
上图中mysql数据由binlog机制生成,binlog文件由canal解析,数据通过canal源传输到flume,然后通过flume写入kafka,提供给后续程序进行存储分析计算。这不是很详细。我们的重点是前面的数据采集。其中,渠源是一种需要自行开发的渠源插件。
我们的题目提到了上述结构的优化。实际上,这种优化主要是由于新版本的Canal提供了一些非常强大的功能,所以我们的总体框架得到了更好的改进。接下来,让我们来看一下新版本的Canal的介绍。
canal1.1.0介绍
重要功能优化
整体性能测试和优化提高了150%。
表结构TSDB相关的问题都是固定的(更多的DDL解析兼容性)
BIO修复binlog很长时间没有数据,导致半开链接无法恢复
新功能
普罗米修斯监测的本地支持
本机支持Kafka邮件传递
bilog订阅,本机支持阿里云RDS(解析自动备份切换/oss binlog离线解析)参考:【阿里云RDS快速入门】
本地支持Docker映像
mysql gtid模式订阅支持
mysql xa binlog事件
MySQL显示从属主机状态支持
基于Canal 1.1.0的建筑优化
事实上,我们在这里关注的最重要的功能是卡夫卡的支持,因为在我们之前的建筑设计过程中,数据从Canal中提取出来后不能直接存储在卡夫卡中,所以我们需要自己读写数据给卡夫卡。使用此功能,我们可以大大简化数据采集和存储过程。
优化架构图
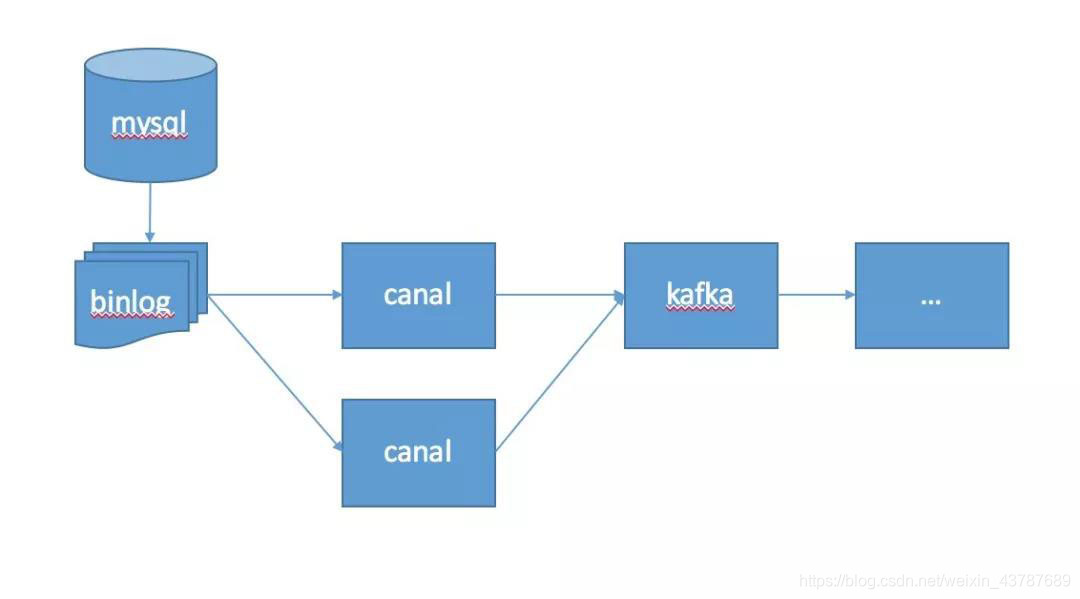
对于Canal 1.1.0,整体架构与上图相同。从Canal水槽卡夫卡的中间环节进行了优化,并通过Canal直接写入卡夫卡主题。经过整体优化后,我们不需要定制渠道渡槽源头的开发,也不需要考虑渡槽使用过程中遇到的问题。