周志华《机器学习》 学习笔记
最近开始学习机器学习,参考书籍西瓜书,做点笔记。
第八章 集成学习
8.1 个体与集成
集成学习:通过构建并结合多个学习起来完成学习任务;
集成目标:个体学习期有一定的准确性,学习器间有一定的差异;
在二分类问题y{-1,1}中,超过半数分类器正确,则集成分类
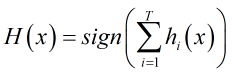
随着集成中个体分类器数目T的增大,集成的错误率将指数级下降,最终趋于零;
集成学习分为个体间强依赖、串行生成的序列化方法(Boosting)和不存在强依赖、同时生成的并行化方法(Bagging、随机森林);
8.2 Boosting
先从初始训练集训练出一个基学习器,再根据学习器的表现对样本进行调整,然后基于调整后的样本分布来训练下一个学习器;
Boosting族最著名的是AdaBoost,对应分类;
书中证明是基于及学习器线性组合,即来最小化指数损失函数
;
通过证明有:,若指数损失函数最小化,则分类错误率也将最小化;
通过证明,得到权重更新公式:;
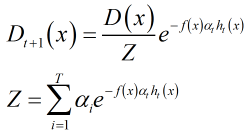
8.3 Bagging和随机森林
1.Bagging
Bagging通常对分类使用简单投票法,对回归使用简单平均法;
Bagging使用“有放回”采样的方式选取训练集,对于包含m个样本的训练集,进行m次有放回的随机采样操作,从而得到m个样本的采样集,这样训练集中有接近36.8%的样本没有被采到。按照相同的方式重复进行,我们就可以采集到T个包含m个样本的数据集,从而训练出T个基学习器,最终对这T个基学习器的输出进行结合。
AdaBoost关注降低偏差,Bagging关注与降低方差;
2.随机森林
RF是在以决策树为及学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入随机属性选择;
RF中基学习器的多样性来自样本扰动和属性扰动;
在选择划分属性时,RF先从候选属性集中随机挑选出一个包含K个属性的子集,再从这个子集中选择最优划分属性,一般推荐K=log2(d);
8.4 结合策略
1.平均法
2.投票法
3.学习法
本章内容主要介绍之前学习的学习器的集成使用,本章时间仓促,没做多少笔记,感觉在《统计学习方法》中对AdaBoost的讲解更清晰一点,后面的结合策略和多样性大多都是公式理解方面,看一遍有一个映像,在以后的应用中需要时回过头来查看。
笔记做的比较粗糙,还请见谅。
有不正确或者不完整的地方,欢迎补充。