手写RPC框架
客户端与NameNode通信的RPC原理,本篇手写RPC框架模拟客户端获取指定路径的元数据。
hdfs读写文件机制:https://blog.csdn.net/weixin_37581297/article/details/84633121
第一步,pom.xml
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.4</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.codehaus.jackson/jackson-core-asl -->
<dependency>
<groupId>org.codehaus.jackson</groupId>
<artifactId>jackson-core-asl</artifactId>
<version>1.9.13</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.codehaus.jackson/jackson-mapper-asl -->
<dependency>
<groupId>org.codehaus.jackson</groupId>
<artifactId>jackson-mapper-asl</artifactId>
<version>1.9.13</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.codehaus.jackson/jackson-jaxrs -->
<dependency>
<groupId>org.codehaus.jackson</groupId>
<artifactId>jackson-jaxrs</artifactId>
<version>1.9.13</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.codehaus.jackson/jackson-xc -->
<dependency>
<groupId>org.codehaus.jackson</groupId>
<artifactId>jackson-xc</artifactId>
<version>1.9.13</version>
</dependency>
第二步,定义协议:NameNodeProtocol
/**
* Project Name: Web_App
* Des: RPC框架通过接口的方式来定义协议。
* Created by Even on 2018/12/4
*/
public interface NameNodeProtocol {
/*1,定义versionID,Hadoop的RPC框架需要用到*/
static final long versionID = 1L;
/*2,模拟客户端获取指定路径的元数据*/
String getMetaData(String path);
}
第三步,定义协议实现类:NameNodeProtocolImpl
/**
* Project Name: Web_App
* Des:协议的实现类
* Created by Even on 2018/12/4
*/
public class NameNodeProtocolImpl implements NameNodeProtocol {
@Override
public String getMetaData(String path) {
/*返回元数据,路径+副本数+块信息*/
return path+":3 - {BLK_1,BLK_4,BLK_5}";
}
}
第四步:构造RPC Server端:RPCServer
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
import java.io.IOException;
/**
* Project Name: Web_App
* Des: RPC服务端代码
* Created by Even on 2018/12/4
*/
public class RPCServer {
public static void main(String[] args) throws IOException {
/*1,构造RPC框架,指定默认的配置*/
RPC.Builder rpc = new RPC.Builder(new Configuration());
/*2,绑定Host*/
rpc.setBindAddress("localhost");
/*3,绑定端口*/
rpc.setPort(9999);
/*4,设置协议*/
rpc.setProtocol(NameNodeProtocol.class);
/*5,设置协议实现类*/
rpc.setInstance(new NameNodeProtocolImpl());
/*6,启动服务*/
RPC.Server rpcServer = rpc.build();
rpcServer.start();
}
}
第五步:构造RPC客户端:RPCClient
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
import java.io.IOException;
import java.net.InetSocketAddress;
/**
* Project Name: Web_App
* Des: RPC客户端
* Created by Even on 2018/12/4
*/
public class RPCClient {
public static void main(String[] args) throws IOException {
/*1,通过代理模式获取协议*/
NameNodeProtocol rpcClient = RPC.getProxy(NameNodeProtocol.class, NameNodeProtocol.versionID, new
InetSocketAddress("localhost", 9999), new Configuration());
/*2,调用协议方法,发送请求*/
String meta = rpcClient.getMetaData("/even");
/*3,拿到元数据*/
System.out.println("meta:" + meta);
}
}
先启动服务端,再启动客户端。
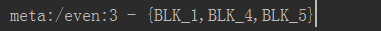
手写MR框架
wordCount项目是Hadoop入门级项目,下面在不引用Hadoop自带MapReduce框架前提下实现WordCount项目。
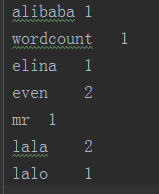
word文档:

需求:统计以上单词在文件中出现的次数。
第一步,封装数据:Context.class
import java.util.HashMap;
/**
* Project Name: Web_App
* Des: 数据传输的类,用于封装数据
* Created by Even on 2018/12/4
*/
public class Context {
private HashMap<Object, Object> contextMap = new HashMap<>();
/*读数据*/
public Object get(Object key) {
return contextMap.get(key);
}
/*写数据*/
public void write(Object key, Object value) {
contextMap.put(key, value);
}
/*获取Map全部数据*/
public HashMap<Object, Object> getContextMap() {
return contextMap;
}
}
第二步,定义Mapper接口
/**
* Project Name: Web_App
* Des:接口设计,map阶段处理数据
* Created by Even on 2018/12/4
*/
public interface Mapper {
/*把line拆分并封装到context中*/
void map(String line, Context context);
}
第三步,实现Mapper接口:
/**
* Project Name: Web_App
* Des:Mapper的实现
* Created by Even on 2018/12/4
*/
public class WorkCountMapper implements Mapper {
@Override
public void map(String line, Context context) {
/*1,切分数据,文件中的单词都是用兩個空格分开*/
String[] words = line.split(" {2}");
/*2,单词相同,value++*/
for (String word : words) {
Object value = context.get(word);
if (null == value) {
/*代表还没有计算该单词*/
context.write(word, 1);
} else {
int v = (int) value;
context.write(word, v + 1);
}
}
}
}
第四步,分析数据WordCount
package com.even.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.net.URISyntaxException;
import java.text.ParseException;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* Project Name: Web_App
* Des:
* Created by Even on 2018/12/4
*/
public class WordCount {
public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException, ParseException {
/*实例化Mapper*/
Mapper mapper = new WorkCountMapper();
Context context = new Context();
/*1,构建hdfs客户端*/
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.11.136:9000/"), new Configuration(), "root");
/*2,读取用户输入文件,已把文件放入hdfs的/even目录下*/
RemoteIterator<LocatedFileStatus> fileIterator = fs.listFiles(new Path("/even"), false);
while (fileIterator.hasNext()) {
LocatedFileStatus fileStatus = fileIterator.next();
FSDataInputStream in = fs.open(fileStatus.getPath());
BufferedReader br = new BufferedReader(new InputStreamReader(in, "utf-8"));
String line;
/*Mapper阶段*/
while ((line = br.readLine()) != null) {
//调用map方法执行业务逻辑
mapper.map(line, context);
}
br.close();
in.close();
}
/*4,建立输出目录*/
Path out = new Path("/even/out");
if (!fs.exists(out)) {
fs.mkdirs(out);
}
/*5,获取缓存*/
HashMap<Object, Object> contextMap = context.getContextMap();
/*6,创建输出文件*/
FSDataOutputStream out1 = fs.create(new Path("/even/out/out"));
/*7,遍历map,输出结果,相当于Reduce阶段*/
Set<Map.Entry<Object, Object>> entrySet = contextMap.entrySet();
for (Map.Entry<Object, Object> entry : entrySet) {
out1.write((entry.getKey().toString() + "\t" + entry.getValue().toString() + "\n").getBytes());
}
out1.close();
fs.close();
System.out.println("统计完毕!");
}
}
最終結果: