缘由
相信大家有时候面试的时候会遇到爬取微信公众号的事情,终于闲了会参考大佬文章自己也搞了一个微信公众号的爬取简单分享一下,莫嫌弃代码low。
借鉴知识
博客参考:https://blog.csdn.net/xc_zhou/article/details/85132587 先看一篇这个大佬的文章,理解一下微信公众号。
曾经尝试过抓取微信文章的小伙伴,一定很熟悉搜狗微信。搜狗微信是腾讯官方提供的搜索引擎,专门用来搜索微信公众号发表的文章(不包含服务号)
搜狗微信链接:https://weixin.sogou.com/
爬取步骤如下
第一步 创建自己的公众号
创建公众号地址:https://mp.weixin.qq.com/ # 创建方法就不说了。
第二步 查找微信公众号
第一步 如图:

第二步 如图:
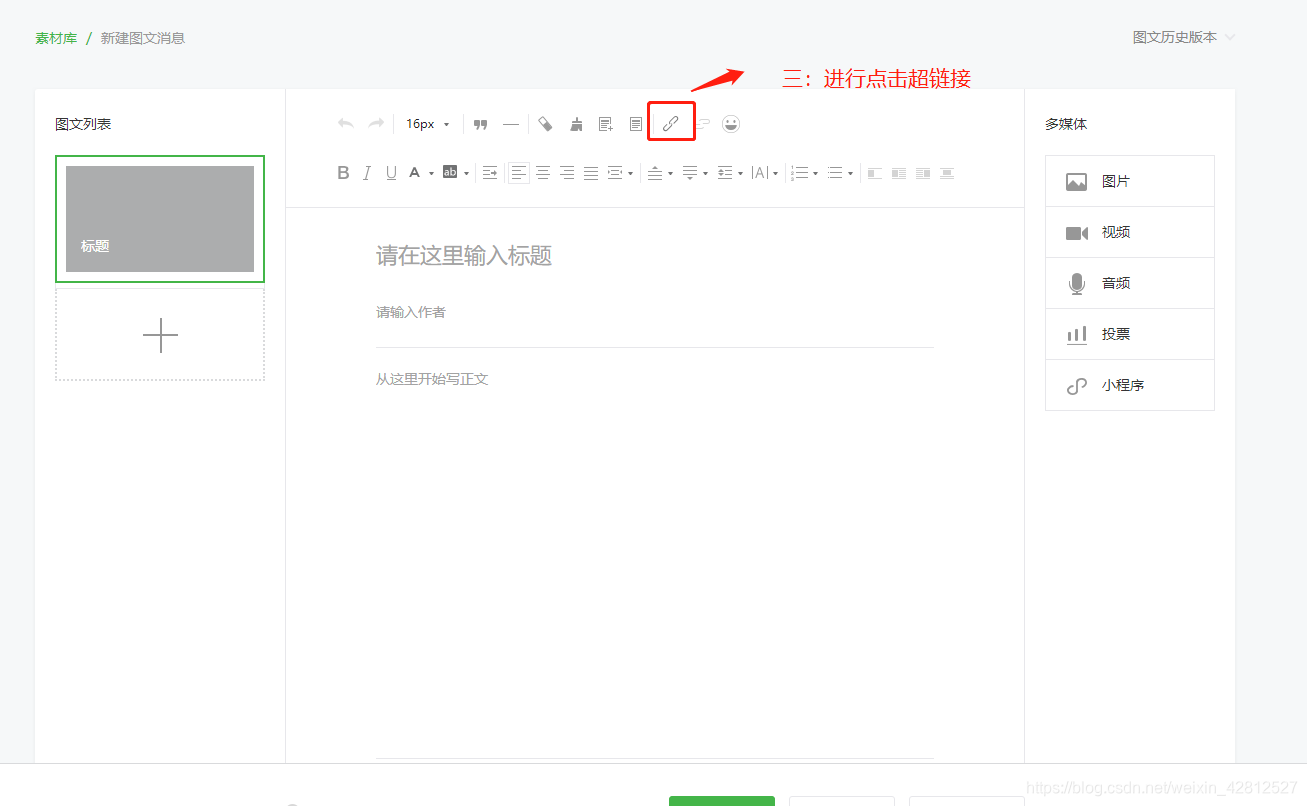
第三步 如图:
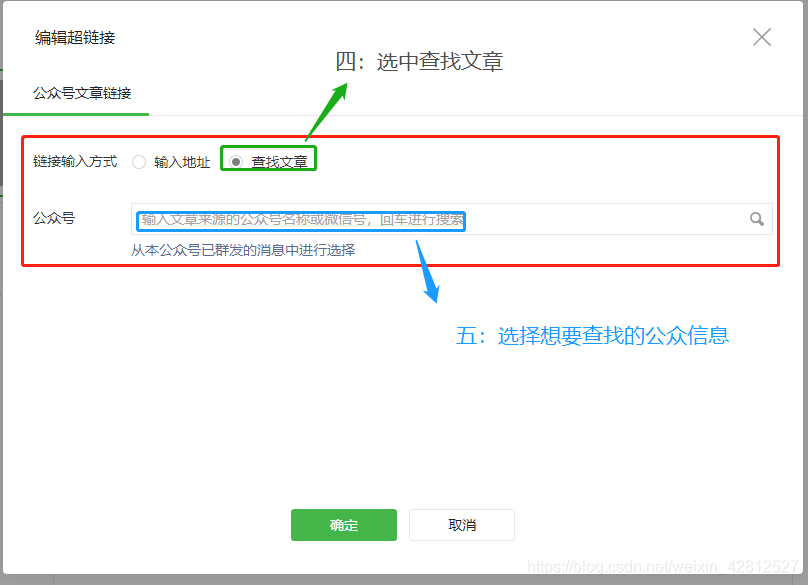
第四步 如图:
以计算机视觉为例,当然你也可以选取其他的,以及看请求需要提交的参数。
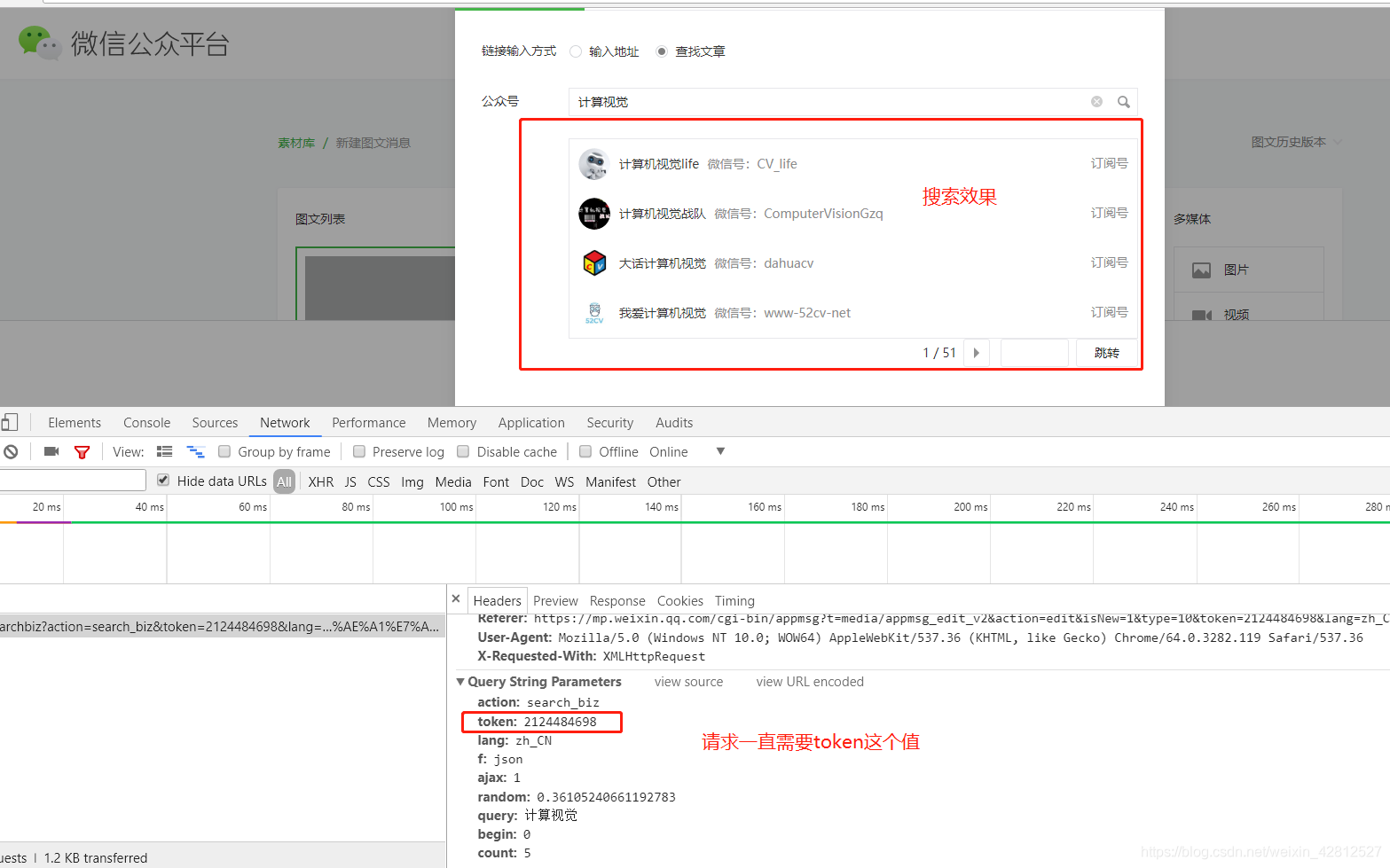
第五步 如图:
可以看出每个公众号都有fakeid这个参数,而想要访问每个公众号请求则必须需要这个参数,可看步骤6.

第六步 如图:
选定要爬取的文章,查看请求所需要提交的参数。
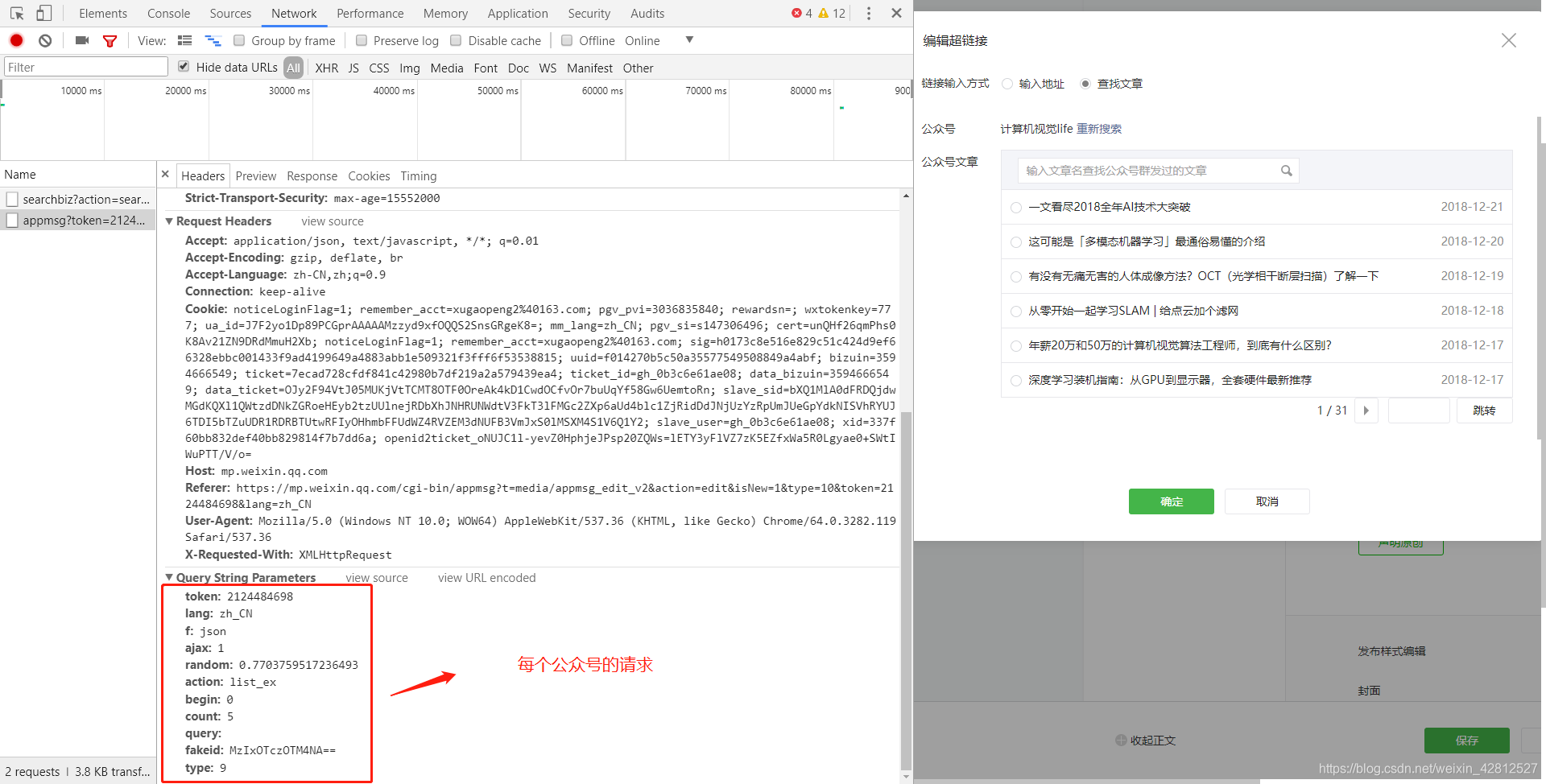
第七步 如图:
每个公众号 前五篇的文章信息。
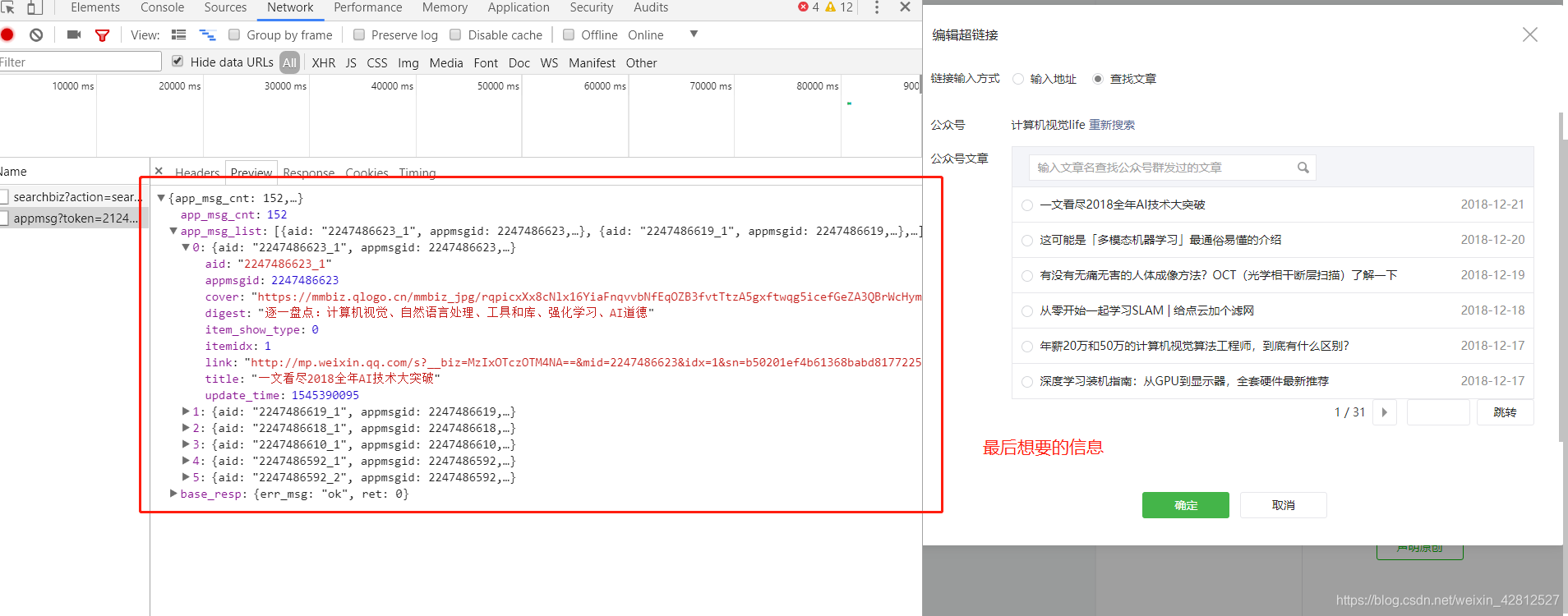
以上的步骤就是 微信公众号文章的请求了。那么分析过后用代码来实现吧。如果以上的分析你没有太理解建议参考大佬文章:
https://blog.csdn.net/xc_zhou/article/details/85132921
https://mp.weixin.qq.com/s?__biz=MzI5NDY1MjQzNA==&mid=2247483970&idx=1&sn=cde40462d2346ded8e8c11ab4442bbab&chksm=ec5edd3fdb2954299e5b4736b3729014d4853e50e643de06640ba3af370753db069667511db1&mpshare=1&scene=1&srcid=0612suzxGJXTmoak9i81rRSZ&pass_ticket=YsJz0pUrK8Yj6XuoyHfGbfjFAgRZ9wHQMTLCnfaYLlQGaOXangzh2LWgrfB8lf76#rd
代码如下
import re
import json
import time
import random
import requests
from scrapy import Selector
from selenium import webdriver
class PublicDocumentsSpider:
def __init__(self):
"""
初始化一些变量
"""
self.browser = webdriver.Chrome('G:\ChromDownLoad\chromedriver.exe')
self.browser.maximize_window()
self.user_name = '公众号用户名'
self.pass_word = '用户名密码'
def start_crawl(self):
"""
获取cookies信息 并以字典的形式保存到本地文件
:return:
"""
start_url = 'https://mp.weixin.qq.com/'
self.browser.get(start_url)
self.browser.find_element_by_xpath('//input[@name="account"]').send_keys(self.user_name) # 输送账号
self.browser.find_element_by_xpath('//input[@name="password"]').send_keys(self.pass_word) # 输送密码
time.sleep(2) # 这个时间 可以勾选 记住账号密码
self.browser.find_element_by_xpath('//a[@title="点击登录"]').click()
time.sleep(15) # 休眠15秒 拿出手机进行扫码
# 登陆过后进行访问首页 拿到自己想要的cookies值
self.browser.get(url='https://mp.weixin.qq.com/')
cookie_info = self.browser.get_cookies()
cookie_dict = {}
for each_info in cookie_info:
cookie_dict[each_info['name']] = each_info['value']
cookie_dict = json.dumps(cookie_dict)
with open('./cookie_dict.txt', 'w') as f:
f.write(cookie_dict)
self.browser.close()
def search_documents(self):
"""
搜索想要的公众号信息,并获得公众号的fakeid
:return:
"""
url = 'https://mp.weixin.qq.com'
# 设置headers
header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36"
}
# 读取上一步获取到的cookies
with open('cookie_dict.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie) # 变成字典
response = requests.get(url=url, cookies=cookies, headers=header)
token = re.findall(r'token=(\d+)', str(response.url))[0] # 因为在上文分析中得到需要token
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz'
search_headers = {
'Host': 'mp.weixin.qq.com',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36',
}
search_params = {
'action': 'search_biz',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': str(random.random()),
'query': str(input('想要搜索的公众号信息')),
'begin': 0,
'count': 5,
}
search_response = requests.get(url=search_url, headers=search_headers, cookies=cookies,
params=search_params).json()
search_info = search_response.get('list') # 拿到显示搜到的所有公众号
select_article_fakeid = search_info[0].get('fakeid') # 这里选择第一篇公众号文章
self.documents_info(cookies, token, select_article_fakeid)
def documents_info(self, cookies, token, select_article_fakeid):
"""
获取每个公众号的所有文章信息
:param cookies: cookies值
:param token: token值
:param select_article_fakeid: 每个公众号的fakeid。
:return:
"""
article_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg'
article_headers = {
'Host': 'mp.weixin.qq.com',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36',
}
article_params = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': 1,
'random': str(random.random()),
'action': 'list_ex',
'begin': 0,
'count': 5,
'query': '',
'fakeid': select_article_fakeid,
'type': 9,
}
try:
response_info = requests.get(url=article_url, headers=article_headers, cookies=cookies,
params=article_params)
except BaseException as e:
print(e)
else:
response_info = response_info.json()
self.app_msg(cookies, response_info.get('app_msg_list')) # 进行第一次下载.........
article_total = response_info.get('app_msg_cnt')
print('此公众号共有 %s 文章' % str(article_total))
all_page = int(int(article_total) / 5)
if all_page >= 1:
print('开始采集下一页..........')
for i in range(1, int(all_page) + 1):
article_params = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': 1,
'random': str(random.random()),
'action': 'list_ex',
'begin': str(int(i) * 5),
'count': 5,
'query': '',
'fakeid': select_article_fakeid,
'type': 9,
}
try:
response_info = requests.get(url=article_url, headers=article_headers, cookies=cookies,
params=article_params)
except BaseException as e:
print(e)
else:
response_info = response_info.json()
self.article_msg(cookies, response_info.get('app_msg_list')) # 进行第二次下载.........
else:
print('此公众号小于5篇文章')
def article_msg(self, cookies, app_msg_list):
"""
请求每篇文章进行获取自己想要的信息。
:param cookies: cookies值
:param app_msg_list: 公众号每页的文章信息 列表的形式。
:return:
"""
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'
}
for each_app_msg in app_msg_list:
each_link = each_app_msg.get('link')
each_title = each_app_msg.get('title')
try:
response = requests.get(url=each_link, headers=headers, cookies=cookies).text
except BaseException as e:
print(e)
else:
response = Selector(text=response)
original = response.xpath('//span[@id="copyright_logo"]/text()').extract_first() # 是否是原创
author = response.xpath(
'//span[@class="rich_media_meta rich_media_meta_text"]/text()').extract_first() # 原创作者
nick_author = response.xpath('//a[@id="js_name"]//text()').extract_first() # 微信公众号
public_time = response.xpath('//em[@id="publish_time"]/text()').extract_first() # 文章发表时间
article_html = response.xpath('//div[@id="js_content"]//p').extract_first() # 文章段
print(each_link, each_title, original, author, nick_author, public_time)
if __name__ == '__main__':
public_documents_spider = PublicDocumentsSpider()
public_documents_spider.start_crawl()
public_documents_spider.search_article()
ok ,以上的代码分享结束了。看一下成果。

以上就是获取的信息。当然你也可以选择自己想要的信息。整篇文章分享结束了。当然此接口不知道到底能采集多少公众号信息,建议搞搞代理IP,多建几个公众号。回去睡觉…