一、算法原理
k近邻法(k-nearest neighbor,k-NN)是一种基本分类与回归方法。本书只讨论分类问题中的k近邻法。k近邻法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类。k近邻法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其k个最近邻的训练实例的类别,通过多数表决等方式进行预测。k近邻法不具有显式的学习过程。k近邻法实际上利用训练数据集对特征向量空间进行划分,并作为其分类的“模型”。
1.常用的相似性度量
特征空间中两个实例点的距离是两个实例点相似程度的反映。常用的相似性度量如下:
(1)欧氏距离:多维坐标下的距离,常见的有二维坐标、三维坐标。
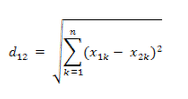
(2)曼哈顿距离:出租车距离或者曼哈顿距离表示两个点在标准坐标系下的绝对轴距总和。
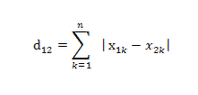
(3)切比雪夫距离:两个点之间的距离定义式其各个坐标数值差的最大值。
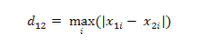
更多的相似性度量可以查看:https://blog.csdn.net/xholes/article/details/52708854
2.k值的选择

k值的选择会对k近邻法的结果产生重大影响。
如果选择较小的k值,就相当于用较小的邻域中的训练实例进行预测,“学习”的近似误差(approximation error)会减小,只有与输入实例较近的(相似的)训练实例才会对预测结果起作用。但缺点是“学习”的估计误差(estimation error)会增大,预测结果会对近邻的实例点非常敏感[2]。如果邻近的实例点恰巧是噪声,预测就会出错。换句话说,k值的减小就意味着整体模型变得复杂,容易发生过拟合。
如果选择较大的k值,就相当于用较大邻域中的训练实例进行预测。其优点是可以减少学习的估计误差。但缺点是学习的近似误差会增大。这时与输入实例较远的(不相似的)训练实例也会对预测起作用,使预测发生错误。k值的增大就意味着整体的模型变得简单。
如果k=N,那么无论输入实例是什么,都将简单地预测它属于在训练实例中最多的类。这时,模型过于简单,完全忽略训练实例中的大量有用信息,是不可取的。在应用中,k值一般取一个比较小的数值。通常采用交叉验证法来选取最优的k值。
3.kd树
kd树是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是二叉树, 表示对k维空间的一个划分( partition) 。 构造kd树相当于不断地用垂直于坐标轴的超平面将k维空间切分, 构成一系列的k维超矩形区域。 kd树的每个结点对应于一个k维超矩形区域。构造kd树的方法如下: 构造根结点, 使根结点对应于k维空间中包含所有实例点的超矩形区域; 通过下面的递归方法, 不断地对k维空间进行切分, 生成子结点。 在超矩形区域( 结点) 上选择一个坐标轴和在此坐标轴上的一个切分点, 确定一个超平面, 这个超平面通过选定的切分点并垂直于选定的坐标轴, 将当前超矩形区域切分为左右两个子区域(子结点); 这时, 实例被分到两个子区域。 这个过程直到子区域内没有实例时终止( 终止时的结点为叶结点) 。 在此过程中, 将实例保存在相应的结点上。通常, 依次选择坐标轴对空间切分, 选择训练实例点在选定坐标轴上的中位数( median)为切分点, 这样得到的kd树是平衡的。 注意, 平衡的kd树搜索时的效率未必是最优的。(详情看《统计学习方法》)
4.knn回归
KNN算法也可以用于回归问题。假设离散样本最近的k个训练样本的标签值为,则对样本的回归预测输出值为
即所有邻居的标签的均值,在这里最近的k个邻居的贡献被认为是相等的。同样也可以采用带权重的方案。权重可以人为的设定,例如设置为与距离成反比或者采用高斯函数。带权重的回归预测函数为
二、算法实践
1.knn识别Iris数据集
#Author zsl
import math
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from itertools import combinations
from collections import Counter
#加载iris数据
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal lenth', 'sepal width', 'petal length', 'petal width', 'label']
print(df)
data = np.array(df)
X, y = data[:, :-1], data[:, -1]
X_train, X_test, y_train,y_test = train_test_split(X, y, test_size=0.2)
#可视化iris数据
plt.scatter(df[:50]['sepal lenth'], df[:50]['sepal width'], label='0')
plt.scatter(df[50:100]['sepal lenth'], df[50:100]['sepal width'], label='1')
plt.scatter(df[100:150]['sepal lenth'], df[100:150]['sepal width'], label='2')
plt.title('iris show')
plt.xlabel('sepal lenth')
plt.ylabel('sepal width')
plt.legend()
plt.show()
#构建KNN类
class KNN:
def __init__(self, X_train, y_train, n_neighbors = 3, p = 2):
'''
parameter: n_neighbors 临近点个数
parameter: p度量距离
'''
self.n = n_neighbors
self.p = p
self.X_train = X_train
self.y_train = y_train
def predict(self, X):
#取出n个点
knn_list = []
for i in range(self.n):
dist = np.linalg.norm(X - self.X_train[i], ord=self.p)
knn_list.append((dist, self.y_train[i]))
for i in range(self.n, len(self.X_train)):
max_index = knn_list.index(max(knn_list, key=lambda x:x[0]))
dist = np.linalg.norm(X-self.X_train[i], ord=self.p)
if knn_list[max_index][0] > dist:
knn_list[max_index] = (dist, self.y_train[i])
#统计
knn = [k[-1] for k in knn_list]
count_pairs = Counter(knn)
max_count = sorted(count_pairs, key = lambda x:x)[-1]
return max_count
def score(self, X_test, y_test):
right_count = 0
n = 10
for X,y in zip(X_test, y_test):
label = self.predict(X)
if label == y:
right_count += 1
return right_count / len(X_train)
if __name__ == '__main__':
clf = KNN(X_train, y_train)
#print(clf.score(X_test, y_test))
test_point = [6.0, 3.0, 4.0, 2.0]
print (clf.predict(test_point))2.kd树实现
#Author zsl
from math import sqrt
from collections import namedtuple
#kd-tree每个结点中主要包含的数据结构如下
class KdNode(object):
def __init__(self, dom_elt, split, left, right):
self.dom_elt = dom_elt #k维向量结点(k维空间中的一个样本点)
self.split =split #整数(进行分割维度的序号)
self.left = left #该结点分割超平面左子空间构成的kd-tree
self.right = right #该结点分割超平面右子空间构成的kd-tree
class KdTree(object):
def __init__(self, data):
k = len(data[0])
def CreateNode(split, data_set): #按第split维划分数据集创建kdnode
if not data_set:
return None
data_set.sort(key=lambda x: x[split])
split_pos = len(data_set) // 2
median = data_set[split_pos]
split_next = (split + 1) % k
#递归的创建kd树
return KdNode(median, split,
CreateNode(split_next, data_set[:split_pos]),
CreateNode(split_next, data_set[split_pos + 1:]))
self.root = CreateNode(0, data)
def preorder(root):
print(root.dom_elt)
if root.left:
preorder(root.left)
if root.right:
preorder(root.right)
result = namedtuple("Result_tuple", "nearest_point nearest_dist nodes_visited")
def find_nearest(tree, point):
k = len(point) #数据维度
def travel(kd_node, target, max_dist):
if kd_node is None:
return result([0]*k, float("inf"), 0)
nodes_visited = 1
s = kd_node.split #进行分割的维度
pivot = kd_node.dom_elt #进行分割的“轴”
if target[s] <= pivot[s]:
near_node = kd_node.left
further_node = kd_node.right
else:
near_node = kd_node.right
further_node = kd_node.left
temp1 = travel(near_node, target, max_dist)
nearest = temp1.nearest_point
dist = temp1.nearest_dist
nodes_visited += temp1.nodes_visited
if dist < max_dist:
max_dist = dist
temp_dist = abs(pivot[s] - target[s])
if max_dist< temp_dist:
return result(nearest, dist, nodes_visited) #不相交则可以直接返回
temp_dist = sqrt(sum((p1 - p2) ** 2 for p1, p2 in zip(pivot, target)))
if temp_dist < dist:
nearest = pivot
dist = temp_dist
max_dist = dist
#检查另外一个子结点对应的区域是否有更近的点
temp2 = travel(further_node, target, max_dist)
nodes_visited += temp2.nodes_visited
if temp2.nearest_dist < dist: #如果另一个子节点内存在更近距离
nearest = temp2.nearest_point
dist = temp2.nearest_dist
return result(nearest, dist, nodes_visited)
return travel(tree.root, point, float("inf"))
if __name__ =="__main__":
data = [[2,3], [5,4], [9,6], [4,7], [8,1], [7,2]]
kd = KdTree(data)
preorder(kd.root)
ret = find_nearest(kd, [3, 4.5])
print (ret)3.sklearn实现
官网英文文档:http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html
sklearn实现手写数字的识别。数字图片是32x32的二进制图像,为了方便计算,我们可以将32x32的二进制图像转换为1x1024的向量。(来自《机器学习实战》https://blog.csdn.net/c406495762/article/details/75172850)
KNeighborsClassifier(n_neighbors=5, weights=’uniform’, algorithm=’auto’,
leaf_size=30, p=2, metric=’minkowski’, metric_params=None, n_jobs=None, **kwargs)KNneighborsClassifier参数说明:
- n_neighbors:默认为5,就是k-NN的k的值,选取最近的k个点。
- weights:默认是uniform,参数可以是uniform、distance,也可以是用户自己定义的函数。uniform是均等的权重,就说所有的邻近点的权重都是相等的。distance是不均等的权重,距离近的点比距离远的点的影响大。用户自定义的函数,接收距离的数组,返回一组维数相同的权重。
- algorithm:快速k近邻搜索算法,默认参数为auto,可以理解为算法自己决定合适的搜索算法。除此之外,用户也可以自己指定搜索算法ball_tree、kd_tree、brute方法进行搜索,brute是蛮力搜索,也就是线性扫描,当训练集很大时,计算非常耗时。kd_tree,构造kd树存储数据以便对其进行快速检索的树形数据结构,kd树也就是数据结构中的二叉树。以中值切分构造的树,每个结点是一个超矩形,在维数小于20时效率高。ball tree是为了克服kd树高纬失效而发明的,其构造过程是以质心C和半径r分割样本空间,每个节点是一个超球体。
- leaf_size:默认是30,这个是构造的kd树和ball树的大小。这个值的设置会影响树构建的速度和搜索速度,同样也影响着存储树所需的内存大小。需要根据问题的性质选择最优的大小。
- metric:用于距离度量,默认度量是minkowski,也就是p=2的欧氏距离(欧几里德度量)。
- p:距离度量公式。在上小结,我们使用欧氏距离公式进行距离度量。除此之外,还有其他的度量方法,例如曼哈顿距离。这个参数默认为2,也就是默认使用欧式距离公式进行距离度量。也可以设置为1,使用曼哈顿距离公式进行距离度量。
- metric_params:距离公式的其他关键参数,这个可以不管,使用默认的None即可。
- n_jobs:并行处理设置。默认为1,临近点搜索并行工作数。如果为-1,那么CPU的所有cores都用于并行工作。
# -*- coding: UTF-8 -*-
import numpy as np
import operator
from os import listdir
from sklearn.neighbors import KNeighborsClassifier as kNN
"""
函数说明:将32x32的二进制图像转换为1x1024向量。
Parameters:
filename - 文件名
Returns:
returnVect - 返回的二进制图像的1x1024向量
Modify:
2017-07-15
"""
def img2vector(filename):
#创建1x1024零向量
returnVect = np.zeros((1, 1024))
#打开文件
fr = open(filename)
#按行读取
for i in range(32):
#读一行数据
lineStr = fr.readline()
#每一行的前32个元素依次添加到returnVect中
for j in range(32):
returnVect[0, 32*i+j] = int(lineStr[j])
#返回转换后的1x1024向量
return returnVect
"""
函数说明:手写数字分类测试
Parameters:
无
Returns:
无
Modify:
2017-07-15
"""
def handwritingClassTest():
#测试集的Labels
hwLabels = []
#返回trainingDigits目录下的文件名
trainingFileList = listdir('trainingDigits')
#返回文件夹下文件的个数
m = len(trainingFileList)
#初始化训练的Mat矩阵,测试集
trainingMat = np.zeros((m, 1024))
#从文件名中解析出训练集的类别
for i in range(m):
#获得文件的名字
fileNameStr = trainingFileList[i]
#获得分类的数字
classNumber = int(fileNameStr.split('_')[0])
#将获得的类别添加到hwLabels中
hwLabels.append(classNumber)
#将每一个文件的1x1024数据存储到trainingMat矩阵中
trainingMat[i,:] = img2vector('trainingDigits/%s' % (fileNameStr))
#构建kNN分类器
neigh = kNN(n_neighbors = 3, algorithm = 'auto')
#拟合模型, trainingMat为测试矩阵,hwLabels为对应的标签
neigh.fit(trainingMat, hwLabels)
#返回testDigits目录下的文件列表
testFileList = listdir('testDigits')
#错误检测计数
errorCount = 0.0
#测试数据的数量
mTest = len(testFileList)
#从文件中解析出测试集的类别并进行分类测试
for i in range(mTest):
#获得文件的名字
fileNameStr = testFileList[i]
#获得分类的数字
classNumber = int(fileNameStr.split('_')[0])
#获得测试集的1x1024向量,用于训练
vectorUnderTest = img2vector('testDigits/%s' % (fileNameStr))
#获得预测结果
# classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
classifierResult = neigh.predict(vectorUnderTest)
print("分类返回结果为%d\t真实结果为%d" % (classifierResult, classNumber))
if(classifierResult != classNumber):
errorCount += 1.0
print("总共错了%d个数据\n错误率为%f%%" % (errorCount, errorCount/mTest * 100))
"""
函数说明:main函数
Parameters:
无
Returns:
无
Modify:
2017-07-15
"""
if __name__ == '__main__':
handwritingClassTest()三、算法总结
kNN算法的优缺点
优点
- 简单好用,容易理解,精度高,理论成熟,既可以用来做分类也可以用来做回归;
- 可用于数值型数据和离散型数据;
- 训练时间复杂度为O(n);无数据输入假定;
- 对异常值不敏感
缺点
- 计算复杂性高;空间复杂性高;
- 样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少);
- 一般数值很大的时候不用这个,计算量太大。但是单个样本又不能太少,否则容易发生误分。
- 最大的缺点是无法给出数据的内在含义。
- 需要大量的内存
四、面试题
1.knn中的k值的如何选取?
在应用中,k值一般取一个比较小的数值。通常采用交叉验证法来选取最优的k值。
2.kd树建立过程中切分维度的顺序是否可以优化?
构建开始前,对比数据点在各维度的分布情况,数据点在某一维度坐标值的方差越大分布越分散,方差越小分布越集中。从方差大的维度开始切分可以获得很好的切分效果和平衡性。