MySQL允许通过触发器、存储过程、函数的形式来存储代码。从MySQL5.1开始,还可以在定时任务中存放代码,这个定时任务也被称为事件。存储过程和存储函数都被同城为存储程序。
这四种存储代码都使用特殊的sql语句扩展,它包含了很多过程处理语法,例如循环和条件分支等。不同类型的存储代码的主要却别在于其执行的上下文;也就是其输入和输出。存储过程和存储函数都可以接受参数然后返回值,但是触发器和事件却不行。
一般来说,存储代码是一种很好的共享和服用代码的方法。不过因为不同的关系数据库都有各自的语法规则,所以不同的数据库很难复用这些存储代码。
这里讲主要惯出存储代码的性能,而不是如何实现。如果打算学习如何编写存储过程,可以阅读由Guy Harrison和Steven Feuerstein编写的MySQL Stored Procedure Programming(O`Reilly)。
有人吵到使用存储代码,也有人反对。这里我们列举下它的优缺点。
优点:
① 它在服务器内部执行,距离数据最近,另外在服务器上执行还可以节省带宽和网络延迟。
② 这是一种代码重用。可以方便的同一业务规则,保证某些行为总是一直,所以也可以为应用提供一定的安全性。
③ 它可以简化代码的维护和版本更新。
④ 它可以帮助提升安全,比如提供更细粒度的权限控制。应用程序也可以通过存储过程的接口访问那些没有权限的表。
⑤ 服务器端可以缓存存储过程的执行计划,这对于需要反复调用的过程,会大大降低消耗。
⑥ 因为是在服务器端部署的,所以备份、维护都可以在服务器端完成。所以存储程序的维护工作会很简单。并且没有外部依赖。
⑦ 它可以在应用开发和数据库开发人员之间更好的分工。
缺点:
① MySQL本身没有提供好用的开发和调试工具,所以编写MySQL的存储代码比其他的数据库更难。
② 它的效率比应用程序的代码会差些。例如它可以使用的函数非常有限,所以使用存储代码很难编写复杂的字符串维护和很复杂的处理逻辑。
③ 存储代码可能会给应用程序代码的负数带来额外的复杂性。因为需要额外部署MySQL内部的存储代码。
④ 因为存储程序都部署在服务器内,所以可能有安全隐患。如果将非标准的加密功能放在存储程序中,那么若数据库被龚波,数据也就泄露了。但是若将加密函数放在应用程序代码中,那么攻击者必须同时攻破程序和数据库才能获得数据。
⑤ 存储过程会给数据库服务器增加额外的压力,而数据库服务器的扩展性相比应用服务器要差很多。
⑥ MySQL并没有什么选项可以控制存储程序的资源消耗,所以在存储过程中出现错误,可能会导致服务器崩溃。
⑦ 存储代码在MySQL中的实现有很多限制;执行计划缓存使链接级别的,游标的物化和临时表相同,在MySQL5.5以前,异常处理也很困难等等。
⑧ 调试MySQL的存储过程是一件很困难的事情。如果慢日志只是给出CALL XYZ('A'),通常很难定位到底是什么导致的问题,这时不得不看看存储过程中的sql语句是如何编写的。
⑨ 它和基于语句的二进制日志赋值合作的不是很好。在基于语句的复制中,使用存储代码有很多的坑。
存储代码是一种帮助应用隐藏复杂性,使得应用开发更简单的方法。不过,它的性能可能更低,而且会给MySQL的赋值等增加潜在的风险。
1 存储过程和函数
MySQL的架构本身和优化器的特性使得存储代码有一些天然的限制,它的性能也一定程度受限:
① 优化器无法使用关键字deterministic来优化单个查询中多次调用存储函数的情况。
② 优化器无法评估存储函数的执行成本。
③ 每个拦截都有独立的存储过程的执行计划缓存。如果有多个链接需要调用同一个存储过程,将会浪费缓存空间来反复缓存同样的执行计划。
④ 存储程序和赋值是一组诡异的组合。如果可以,最好不要赋值对存储程序的调用。直接赋值由存储程序改变的数据会更好。MySQL5.1引入的行赋值能够改善这个问题。
我们通常会希望存储程序越小、月简单越好。希望将更加复杂的处理逻辑讲给上层的应用实现,通常这样会使代码更易读,易维护,也会更灵活。这样做也会让你拥有更多的计算资源,潜在的还会让你拥有更多的缓存资源。
不过,对于某些操作,存储过程比其他的实现要快的多;特别是当一个存储过程调用可以代替很多小查询的时候。如果查询很小,相比这个查询执行的成本,解析和网络开销就变得非常明显。为了证明这一点,我们先创建一个简单的存储过程,用来写入一定数量的数据到一个表中,下面是存储过程代码:

然后对存储过程执行基准测试,看插入100W记录的时间,并和通过客户端程序逐条插入100W记录的时间进行对比。这里结构和硬件并不重要;重要的是两种方式的相对速度。另外,我们还测试了使用MySQL Proxy链接MySQL来执行客户端程序测试的性能。

可以看到存储过程要快很多,很大程度因为它无需网络通信开销、解析开销和优化器开销等。
2 触发器
触发器可以让你在执行insert、update或者delete的时候,执行一些特定的操作。可以在MySQL中指定是在sql语句执行前竹筏还是在执行后触发。触发器本身没有返回值,不过他们可以读取或修改sql语句所影响的数据。所以,可以使用触发器实现一些强制限制,或者某些业务逻辑,否自,就需要在应用程序中实现这些逻辑。
因为使用触发器可以减少客户端和服务器之间的通信,所以触发器可以贱货应用逻辑,还可以调性能。另外,还可以用于自动更新反范式化数据或者汇总表数据。例如,在实例数据库sakila中,我们可以使用触发器来维护film_text表。
MySQL触发器的实现非常简单,所以功能也有限。如果你在其他数据库产品中重度依赖触发器,那么在使用MySQL的时候需要注意,很多时候MySQL触发器的表现和预想的并不一样:
① 对每一个表的每一个时间,最多只能定义一个触发器。
② MySQL只支持基于行的触发。也就是说,触发器始终是针对一条记录的,如果变更数据集非常大,效率会很低。
下面这些触发器本身的限制也适用于MySQL:
① 触发器可以掩盖服务器背后的工作,一个简单的SQL语句背后,因为触发器,可能包含了很多看不见的工作。例如,触发器可能会更新另一个相关表,那么这个触发器会让这条sql影响的记录翻倍。
② 触发器的问题很难排查,如果某个性能问题和触发器相关,会很难分析和定位。
③ 触发器可能导致死锁和锁等待。如果触发器失败,那么原来的sql语句也会失败。
如果仅考虑性能,那么MySQL触发器的实现中对服务器限制最大的就是他的基于行的触发设计。因为性能的原因,很多时候无法使用触发器来维护魂总和缓存表。使用触发器而不是批量更新的一个重要原因就是,使用触发器可以保证数据总是一致的。
触发器并不能一定保证更新的原子性。例如,一个触发器在更新MyISAM表的时候,如果遇到什么作物,是没有办法回滚的。这时,触发器可以抛出错误。假设你在一个MyISAM表上建立一个after update的触发器,用来更新另一个MyISAM表。如果触发器在更新第二个表的时候遇到错误导致更新失败,那么第一个表的更新并不会回滚。
在InnoDB表上的触发器是在同一个事物中完成的,所以他们执行的操作时院子的,原操作和触发器操作会同时失败或成功。不过,如果在InnoDB表上建立触发器去检查数据的一致性,需要特别小心MVCC,很有可能会获得错误的结果。加入打算编写一个before insert触发器来检查写入的数据对应列在另一个表中是存在的,而并没有使用select for update,那么并发的更新语句可能会like更新对应的记录,导致数据不一致。
还可以使用触发器来记录数据变更日志。这对实现一些自定义的赋值会非常方便,比如需要先断开链接,然后修改数据,最后在将所有的修改重新合并回去的情况。
3 事件
事件时MySQL5.1引入的一种新的存储代码的方式。它类似于linux的定时任务,不过是完全在MySQL内部实现的。你可以创建时间,指定MySQL在某个时候执行一段sql。
时间在一个独立时间调度线程中被初始化,这个线程和处理链接的线程没有任何关系。它不接受任何参数,也没有任何的返回值。可以在MySQL的日志中看到命令的执行记录,还可以在表information_schema.events中看到哥哥事件状态。
类似的,一些适用于存储过程的考虑也同样适用于事件。首先,创建时间意味着给服务器带来额外工作。时间实现机制本身的开销并不大,但是时间需要执行sql,则可能会对性能有很大的影响。时间和其他的存储程序一样,在和基于语句的复制一起工作时,也可能会触发同样的问题。时间的一些典型应用包括定期的维护任务、重建缓存、构建汇总表来模拟物化视图,或者存储用于监控和诊断的状态值。
虽然事件调度是一个单独的线程,但是事件本身是可以并行执行的。MySQL会创建一个新的进程用于时间执行。在时间的代码中,如果你调用函数connection_id(),也会返回一个唯一值,和一般的线程返回值一样;虽然时间和MySQL的链接线程是无关的,这个函数返回的只是线程ID。这里的进程和线程声明周期就是时间的执行过程。可以通过show processlist中的command列来查看,这些线程的该列总是显示为connect。
虽然时间处理进程需要创建一个线程来真正的执行时间,但该线程在事件执行结束后会被销毁,而不会放到线程缓存中,并且状态值threads_created也不会被增加。
4 在存储程序中保留注释
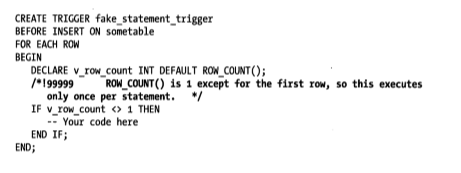
存储过程、存储函数、触发器、事件通常都会包含大量的重要代码,在这些代码中添加注释就很有必要了但是这些注释可能不会存储在MySQL服务器中,因为MySQL的命令行客户端会自动过滤注释。
一个将数据存储到存储过程中的技巧就是使用版本相关的注释,因为这样的注释可能被MySQL服务器执行。服务器和客户端都知道这不是普通的注释,所以不会删除它。为了让这段注释不被执行,可以指定一个非常大的版本号例如99999 :