python2输出中文乱码问题
1、在源码文件第一行添加 #-*-coding:utf-8-*- 或 #encoding=utf-8 或 #encoding=UTF-8
注意:一定要在第一行!
2、在字符串前加 ‘ u ’
例: spring=u"这是一个测试字符串"
3、若上述2种方式仍然不能保证能输出正常输出中文,就需要做编码解码设置
即 encode: 编码(真实字符与二进制串的对应关系,真实字符→二进制串)
decode: 解码(二进制串与真实字符的对应关系,二进制串→真实字符)
① 打印字符串时,字符串本身的编码,与输出终端中所用编码不匹配
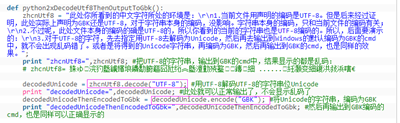
例:本身是UTF-8类型的字符串,但是却将其输出到Windows的cmd中,而cmd中默认是GBK编码的,导致两者不匹配

解决办法:
可以把UTF-8的字符,解码为对应的Unicode,(也可以进一步的,把Unicode字符串,编码为GBK)。然后再输出到
GBK的cmd中,就可以正常显示,不是乱码了:
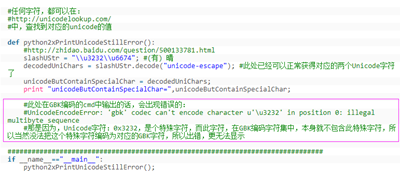
② 打印含某些特殊字符的Unicode类型字符串,但是输出终端中字符编码集中不包含这些特殊字符
例:把Unicode字符串,打印到Windows的cmd中,结果出错:
解决办法:
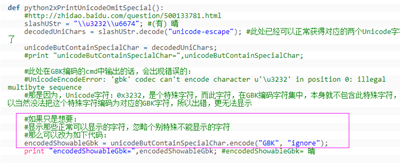
实例:
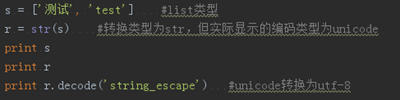
1. str 转换为 unicode


2. unicode 转换为str

参考文档:
python中的编码与解码: https://www.cnblogs.com/shine-lee/p/4504559.html
Python: 在Unicode和普通字符串之间转换: https://blog.csdn.net/u012448083/article/details/51918681
Python 2.x中常见字符编码和解码方面的错误及其解决办法:https://blog.csdn.net/gmj4850/article/details/17115285