我们上篇文章了解了一下VGGNet的网络结构还有训练环节,这篇文章是分享VGGNet做的分类实验和总结,也算是VGGNet的分享收尾工作~(接上篇)
4.分类实验
数据集:ILSVRC的数据从2012 用到了2014,数据集有三类:训练集(1.3M张图),验证集(50K张图),测试集(100K张图还有标签,买一送一吗?)用两种方法来评估:top-1和top-5的错误率。前者是多类分类的错误率,例如,错误分类图像的比例;后者是ILSVRC主要使用的检验标准,top5的类别里没有ground truth的比率。
4.1单尺度评估
测试图像的Q=S对于固定的S,Q=0.5(Smin+Smax),对于抖动S。表三显示了结果。
首先,我们注意到使用LRN没有改善网络A的性能,所以就不用了。
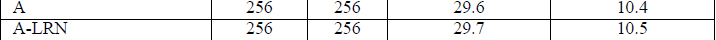
第二,观察对于卷积层的加深,分类错误率的下降:从A网络的11层到E网络的19层。除了相同的深度,C的配置(它可是有3个1X1卷积的啊!),表现得没有D的配置好啊,D用了3X3。

这表明了尽管附加的非线性的确有帮助(C比B好啊),通过无冗余的感受野的卷积核获取空间信息也是很重要的(就是说1X1的卷积核冗余)。当网络结构深度达到19时,错误达到饱和,但是更深的模型可能从更大的数据集中有更好的表现(作者很有预见性的啊,看看ResNet)。通过对比B这样的一个5个5X5卷积的浅层网络和将所有5X5替换成两个3X3,可以得出结论,深且具有小卷积核的网络比浅且具有大卷积核的网络的错误率降低了7%。
最后,尺度抖动在训练的过程中比将尺度固定,有更好的性能,尽管在测试的时候只有用一个尺寸。这证实了训练集的抖动尺度造成的数据增强有利于获取多尺度图像的统计特性。

4.2多尺度评估
评估在测试时也使用尺度抖动。设置不同Q值,并平均结果的先验概率值得到输出的类别。考虑到训练和测试尺度之间的巨大差异导致性能下降,使用固定S训练的模型在三个测试图像大小上进行评估,接近训练尺度:Q ={S-32,S+32},同时使用尺度抖动的训练网络允许网络在测试时使用更多,取值更广的Q值,所以模型被训练时,S ∈ [Smin; Smax],在评估时,Q值的取值Q = {Smin, 0.5(Smin + Smax), Smax}.表4展示了评估结果,表明测试时使用尺度抖动会有更好的表现(和单一固定尺寸比)。训练时尺度抖动比不抖动更好。最好的单网络在验证集上的表现是:在测试集,E配置获得top-5的错误率达到7.3%。

4.3多切割评估
在表5中,我们比较密集卷积网络的评估和多切割图的评估。我们同样还补充了两种评估技术通过平均他们的softmax输出。使用多切割图估计比密集评估好了那么一丢丢,并且两种方法是互补的,他们的结合体表现更加出色。我们假设这是由于对于卷积边界条件的不同处理造成的。
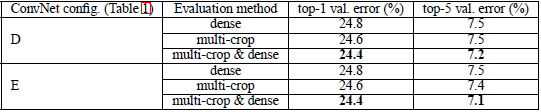
4.4卷积网络融合(网络融合啊!)
对几个模型的输出进行softmax之后取平均。由于模型的互补性,这改善了性能,并且在AlexNet和ZFNet,OverFeat中使用。
结果在表6中显示,在ILSVRC比赛结果提交的时候我们只训练了单尺度的模型(这个时间来不及的场景似曾相识啊!)和多尺度模型D(通过精调全连接层而非所有层)。结果形成了ILSVRC的测试错误率7.3%(的好成绩啊!)在提交之后,通过考虑了只组合两个最好的多尺度模型(配置D和E)使用密集评估将错误降到了7.0%;使用结合密集评估和多crop结合将错误率降到了6.8%。值得一提的是最好模型的错误率达到了7.1%(就是E模型)。
4.5和最新的技术成果进行比较
最终,对比VGGNet和表7上的最新的技术。在2014比赛的分类任务上VGG队伍保持住了第二名的位置,通过组合7个模型将错误率降到了7.3%,在提交结果之后,通过组合两个模型将错误率降低到了6.8%。

正如表7可以看到的,VGGNet很优秀!结果和分类任务的冠军(GoogLeNet 获得了6.7%的错误率)有得一拼,并优于ILSVRC-2013的获胜者(他们用了外来的训练数据获得11.2%的错误率,如果不用那些数据将获得11.7%的错误率)。这些成绩是很优秀的,VGGNet最好的成绩是通过组合两个模型获得的,比大部分ILSVRC中的提交模型的混合模型数量少得多。考虑到单网络的结果,VGGNet的错误率比单GoogleNet低了0.9%,得到7.0%的测试错误率。值得注意的是,VGGNet并没有偏离LeCun等人的经典ConvNet架构,但通过大幅增加深度来改善它。
5.结论(!!!)
任务:大尺度图像分类
得益点:深度有利于提高分类准确率,对于视觉表现也很重要。
感觉他们还能有GPU支持,咱们能有4GPU吗!
6.参考
https://www.aiuai.cn/aifarm138.html 深度好文啊,感谢大大~
原文->VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION