最近看了一篇文章,作者在不借助任何框架的情况下搭建了一个非常简单的神经网络,感觉有点儿意思。加之自己刚刚入门深度学习,于是按照流程实现了一遍,顺便在其中回顾所学的基础知识,如有疏漏,还望指正。
这是一个单层神经网络,只有输入层和输出层,对输出结果还做了Sigmoid非线性变换。如下是展示问题的表格:
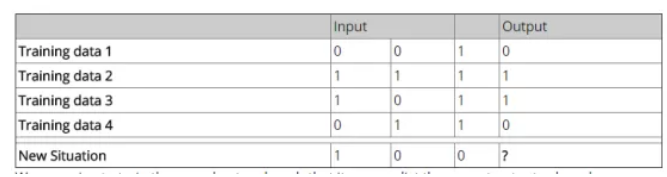
我们希望通过训练数据来训练模型,得到最后的输出结果。
import numpy as np
#定义网络结构和训练过程
class NeutralNetwork():
def __init__(self):
#利用随机数种子生成随机数,会使每次生成的初始权重相同
np.random.seed(1)
#生成了3*1的随机权重矩阵
self.synaptic_weights = 2*np.random.random((3,1))-1
#定义sigmoid激活函数
def sigmoid(self,x):
return 1/(1+np.exp(-x))
#定义sigmoid函数的导数
def sigmoid_derivative(self,x):
return x*(1-x)
#对节点的输出值进行激活
def think(self,inputs):
inputs = inputs.astype(float)
#前向传播结果
output = self.sigmoid(np.dot(inputs,self.synaptic_weights))
return output
#定义训练过程,参数为输入值,输出值,训练轮数
def train(self,training_inputs,training_outputs,train_steps):
for step in range(train_steps):
output = self.think(training_inputs)
#计算训练数据真实值和网络预测值的训练误差
error = training_outputs - output
#模拟反向传播过程,调整误差
adjustments = np.dot(training_inputs.T,error*self.sigmoid_derivative(output))
#微调权重参数
self.synaptic_weights = self.synaptic_weights + adjustments
上面定义了网络的结构的训练过程,在NeutralNetwork类中,我们定义了五个函数,第一个函数定义了边的权重,初始权重是的3乘1矩阵,其中数值大小随机生成,在-1~1之间;第二个函数使用了numpy中的部分函数定义了sigmoid激活函数,用于去线性化;第三个函数sigmoid_derivative()定义了sigmoid的求导结果,f’(x) = f(x)*(1-f(x)),用于对权重参数的调整;第四个函数定义了前向传播的过程,并对前向传播结果进行了sigmoid激活,返回最后的输出结果;第五个函数也是最主要的函数,定义了训练过程,其中有三个参数,分别代表训练数据的输入值、输出值和训练轮数,首先计算了训练数据真实值和网络预测值的训练误差,然后利用误差加权导数公式,根据所得到的误差范围,对权重进行了一些较小的调整。就这样,一个简单的神经网络结构结搞定了。
#定义主函数入口,只在本文件中执行
if __name__ == '__main__':
neutral_work = NeutralNetwork()
print("开始时的权重为:%s"%neutral_work.synaptic_weights)
#训练数据输入值
training_inputs = np.array([[0,0,1],
[1,1,1],
[1,0,1],
[0,1,1]])
#训练数据真实结果
training_outputs = np.array([[0,1,1,0]]).T
neutral_work.train(training_inputs,training_outputs,20000)
print("训练完成后的权重为:%s"%neutral_work.synaptic_weights)
#自定义数据做预测
user_input_one = str(input("请输入第一个值: "))
user_input_two = str(input("请输入第二个值: "))
user_input_three = str(input("请输入第三个值: "))
print("考虑新的输入值: ",user_input_one,user_input_two,user_input_three)
new_output = neutral_work.think(np.array([user_input_one,user_input_two,user_input_three]))
print("预测的输出值为:%s"%new_output)
接下来就是输入数据的训练过程了,设定训练轮数为20000,运行函数后最后结果如下:
开始时的权重为:[[-0.16595599]
[ 0.44064899]
[-0.99977125]]
训练完成后的权重为:[[10.38040701]
[-0.20641179]
[-4.98452047]]
请输入第一个值: 1
请输入第二个值: 0
请输入第三个值: 0
考虑新的输入值: 1 0 0
预测的输出值为:[0.99996897]
可以看到,在训练20000轮后,权重有了较大的改变,对预测数据的预测输出值非常接近于1。和训练数据类似,结果都和输入数据的第一位数字相同。就这样就完成了一个简单神经网络的搭建过程,可以对深度学习的基础知识有更深刻的了解。