“大数据”这个词儿已经在 IT 圈蔓延到各个领域,如果真要刨根问底的问一句“如何实现大数据分析”,恐怕是 IT 圈里的好些人也一时半会儿解释不清楚吧。所以尝试把大数据分析这个事做个深入浅出的剖析还是很有意义的。仁者见仁智者见智,能力所限,表达如有不准确的地方希望你能用包容的心态多理解和指导。
首先,用5秒钟的时间扫描一下下面的这段内容吧:

知道上面是一段日志文件的片段的请举手。敢问阁下您是一位受人尊敬的码农吧?

看上面内容像天书的请举手。请不要怀疑自己的能力,证明你是一个正常人,你的人生依然充满希望和光明。

如果把上面的日志信息归纳如下,看起来是不是有点感觉了。
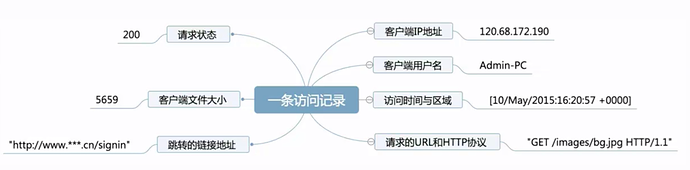
每当你访问一个网站时,从你打开网站首页开始,到你离开那个网站,只要网站愿意,你的一举一动就会不停的产生类似上面这样日志记录,无数人的访问会产生大量的访问记录,这个网站的“用户访问情况大数据”就这样产生了。
接着思考,这些用户访问情况的大数据有什么价值呢?
没错!做网站用户行为分析呀,了解用户在网站上的动向、喜好,然后给用户推荐更他更有可能感兴趣的内容,为网站的运营决策提供数据参考等等,这个过程用一句带点技术范儿的话总结就是:“日志掘金“。

日志掘金就是大数据分析的一个具体的应用场景。因为原始的日志文件(数据源)的信息是大而全的,而且结构有些复杂不易读懂,所以日志掘金就像淘金一样,从茫茫的数据海洋中,通过过滤、清洗,筛出有价值的关键信息—— KPI(黄金)。

那么继续思考,如何通过技术实现从“数据源”过滤出“KPI”呢?下面是一个简要的数据掘金流程图,请稍微耐点心看看(图下的文字解读会让你柳暗花明又一村):

用户上网产生的行为被“日志文件”记录下来,因为网站的访问量很大,所以产生的日志文件也很大,为了能够更高效的对这个文件进行分析,所以把它保存到一个叫“ HDFS ”的分布式文件系统中。这个过程中一份完整的“日志文件”会被拆分成n个小文件(按照每个小文件64MB等分),拆分后的每个小文件会再复制2个备份(n个小文件就变成了3n个),然后将这些小文件保存到“ HDFS ”系统的划分出来的存储节点上(一个存储节点可以简单理解为一台电脑),保存的过程中同一份小文件和它的拷贝要保存在不同的存储节点上(目的是为了防止某几台电脑坏了,没有备份的话就会造成文件缺失)。

通过上面的过程,接下来从一个大日志文件中查找数据就演变为可以利用一群计算节点(计算机),同时从n个小文件中并行的查找数据了,然后再将每个节点查找的结果进行合并汇总,这个过程就是 MapReduce 数据清洗。
这个过程有点复杂,举个栗子:从一个包含一组单词的文件中(理解为“日志文件”)统计每个单词出现的次数。首先将一个大文件拆分为三个小文件,然后分别统计每个小文件中每个单词出现的次数,最后汇总每个小文件统计的结果。具体如下图所示:

经过 MapReduce 数据清洗之后,从一个数据结构不规则、大而全的日志文件中提取出需要的关键指标数据了,请注意提取后的数据依然保存在 HDFS 中。再深入思考一下,如何从提取后的数据进行统计呢?这个时候可以有多种方案了,下图例举了2个方案,这两个方案我们不展开详细说明了,总而言之是能够从 HDFS 中进行数据的统计了。

最后再思考一个问题:既然已经能够统计分析了,为什么还要再多此一举将 HDFS 中的数据导入到 HBase 和 MySQL 数据库中呢?这不是画蛇添足吗?
这是因为需要把数据统计分析的结果和数据明细能够方便的提供给别人(比如:前端开发同学)去使用,满足别人坐享其成的快感!
举个栗子吧:
小马不懂大数据底层技术,但他在百度上找到了一个叫“图表秀”的数据可视化分析软件。他请团队的技术大牛将公司产品网站运行的大数据进行采集、清洗,将网站 KPI 数据保存到本地的一个数据库中,这样每次给领导做月度汇报时,他就熟练的利用“图表秀”来制作各种丰富多样的数据图表。
其实,上面这个日志分析的过程还是蛮复杂的,市面上有一些专业的日志分析软件将数据采集、清洗、统计、可视化分析的过程做成了成熟的软件产品,这就降低了技术门槛,提升了日志掘金的效率。比较知名的有 SaCa DataInsight