harbor初期版本1.4是在vmware旗下,当前已经成立了新项目goharbor。并且1.6.0版本之后进行了重构,数据库由mysql转换到postgresql,部分表结构也稍微改变了,代码也增强了很多,同时新增了helm chartmuseum仓库功能。对于harbor这个项目,可能有些开发者不太了解或者疑惑,为什么不直接使用docker registry,然后在registry上面再增加一个Auth鉴权。当然对于个人开发者或者企业内部,完全可以这样,不用管授权的问题。但是对于一个企业对外提供镜像存储服务,没有授权,那是不行的,A上传的镜像,B可以随便进行操作,这就不能作为企业级的产品了。harbor项目的开源之处就在于此,集很多开源组件于自身,并且组件都是插拔式,企业可以根据自身需求进行模块选择,然后再对外提供统一的服务。
harbor依赖的软件环境是docker、docker-compose,单台机器的硬件配置至少2核4G。首先说一下,个人开发者如何快速启动harbor服务用于学习研究。访问https://github.com/goharbor/harbor/releases,下载对应的harbor 离线安装包。
tar -zxvf harbor-offline-installer-v1.7.0.tgz cd harbor ./prepare --with-clair ./install.sh --with-clair
./prepare 会把harbor.cfg中的配置参数渲染到对应的各个组件参数配置目录,即common/config下面。--with-clair表示启动镜像扫描功能,--with-chartmuseum 表示启动helm charmuseum功能,如果只需基础服务,直接./prepare && install.sh即可,停止harbor,请根据服务执行docker-compose -f docker-compose.yml -f docker-compose.clair.yml down 。单机服务所有的组件都是以容器方式启动的,包括存储层的redis、mysql、postgresql。
以上只是作为个人开发者研究使用,但如果用于企业的的产品线上,我们必须进行HA部署,防止单点故障,同时进行源码二次开发改造,融入到业务的的产品线中,对外提供稳定的镜像储存服务。下面,我们就把harbor作为企业项目来讲讲。
harbor依赖的数据存储中间件跟它的版本有很大关联,毕竟harbor项目可能也是两拨人开发,现在把它作为独立的项目,可能会开始发力把它功能做的更完善,代码写的更规范。harobr1.5之前的版本采用的数据库是mysql,redis不是必须的,即使ha部署时涉及到session同步存储,可以修改源码直接使用msyql代码,同时关闭registry的缓存功能,但是harbor依赖的镜像扫描组件是coreos的clair项目,这clair又只支持postgresql,并且clair官方并不想去支持其他数据库。对于大多中国互联网公司,用的最多的数据库莫过于msyql了,但是歪果开源项目偏偏都开始流行使用postgresql。不知道harbor官方是否考虑到这个问题,直接在1.6.0版本之后强制使用postgresql数据库,不再去支持mysql数据库了。我是在早期1.4版本构建了公司项目,迁库迁移数据,那就算了,只能修改源码,叠功能了,作为公司的个性化项目,本身也不可能轻易去同步官方代码,唯有谨慎功能迭代了。
通用的简易架构图
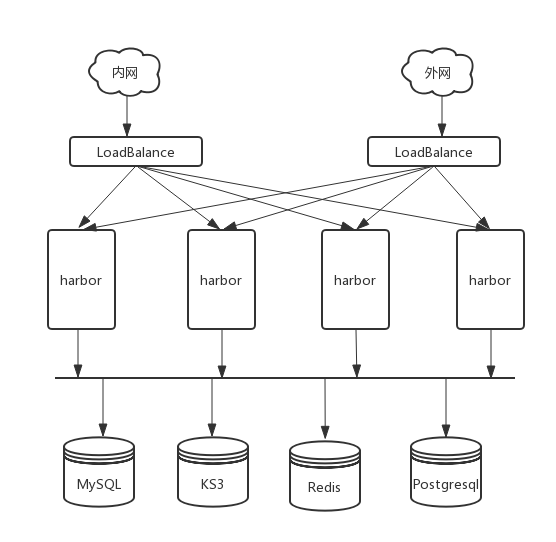
对于企业项目来说,重要的存储中间件,肯定都要抽离出来,当前各云厂商都具备这些云服务。对于当前采用harbor新版本部署服务的企业来说,它的开发者太幸运了,直接少了mysql组件,根本不会感知harbor的重构。早期的v1.4,就是必须依赖这些,到现在,已经稳定运行2年时间,不可能再去迁移数据库了。上面只是一个简单的参考模型,对于很多企业来说,直接全都走公网模式也行。
mysql是harbor的数据库,ks3、s3、oss等这些对象存储层用来存储镜像文件,redis主要用来进行registry缓存、session存储包括后期的helm chartmuseum缓存,postgresql用来存储clair从各大开源社区获取的CVE漏洞缺陷数据以及镜像层的扫描结构数据,当前CVE的数据从2002到2018年差不多将近20万条。
改造后的一个功能结构图
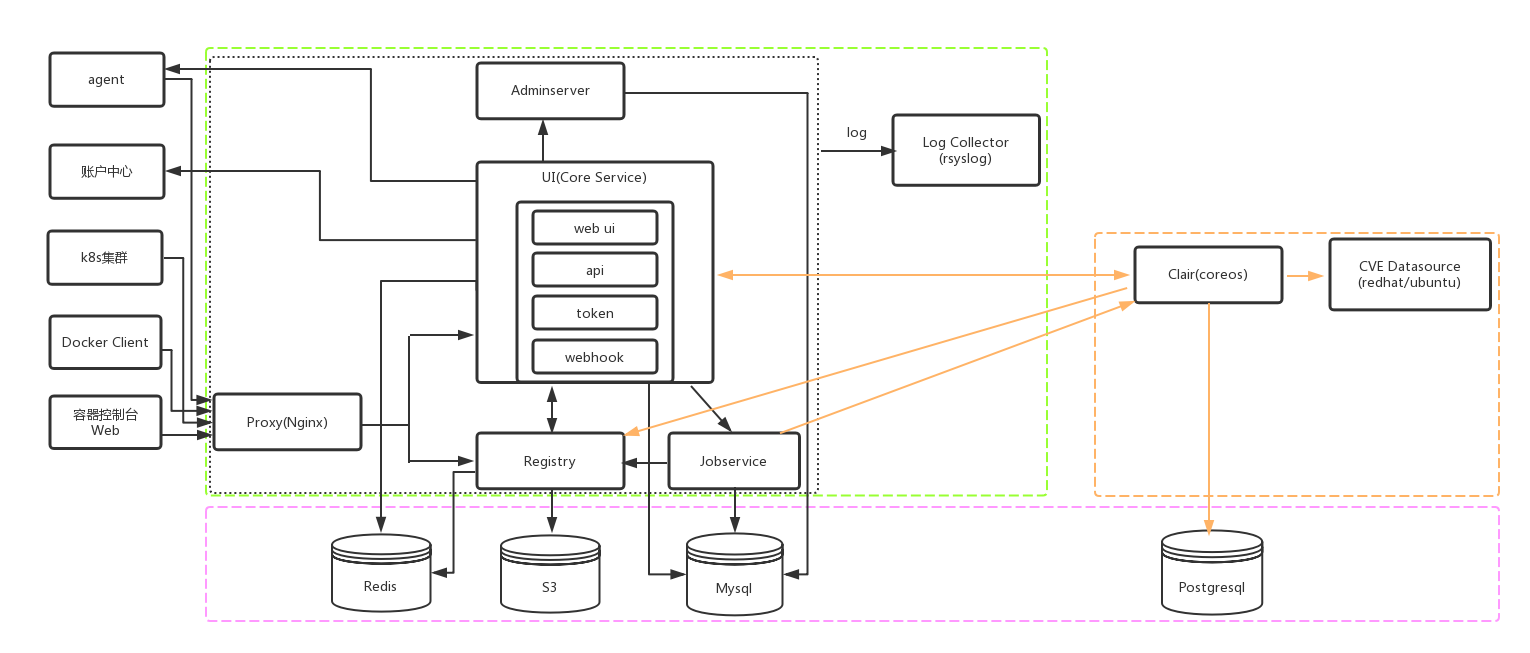
上图中的实线箭头代表的是请求方向。
harbor服务主要包含Proxy、Adminserver、Jobservice、UI、Registry、Log六个组件,这六个容器必须成功启动才能构成一个完整的整体服务。
harbor通过Proxy进行反向代理接收所有的请求,然后转发到对应的内部服务组件。所有进入Registry的请求都必须携带token,因此,需要访问Registry的服务必须先通过UI组件中的token服务获取一个有效token,再去请求Registry,典型的例子就是Docker Client的docker login、docker pull等相关请求。
Adminserver主要是用来管理系统启动配置,操作数据库中的配置表properties。
Jobservice主要处理两类定时任务,镜像扫描任务以及仓库镜像远程复制任务。
UI是业务核心模块,web ui是官方web管理端(已不对用户开放),api主要提供对外的rest http服务,token主要代理了registry的所有请求身份认证功能,基于jwt生成令牌,同时利用密钥加密。webhook主要提供给Registry、Clair的回调,当Registry镜像推送或者下拉成功时即通知UI,以及Clair漏洞数据有更新时通知UI。
Registry是镜像处理的核心组件,处理镜像的上传、下拉等,直接操作镜像存储服务,如KS3、FileSystem等。
Log是harbor内部的日志收集功能,harbor服务启动的时候,Log是最优先启动的模块。
编译
基于harbor的源码二次开发,当然需要进行编译。首先需要搞明白harbor目录下的Makefile以及子目录make/photon/Makefile文件,这两个文件是编译的核心流程。官方的编译命令
make package_offline GOBUILDIMAGE=golang:1.7.3 COMPILETAG=compile_golangimage CLARITYIMAGE=vmware/harbor-clarity-ui-builder:1.2.7
如果需要增加扩展功能,比如镜像扫描,则带上参数ClairFlag
make package_offline GOBUILDIMAGE=golang:1.7.3 COMPILETAG=compile_golangimage CLARITYIMAGE=vmware/harbor-clarity-ui-builder:1.2.7 CLAIRFLAG=true
官方给出的编译方法全都是基于在docker容器中进行的,不依赖当前的宿主机环境,比如编译adminserver、jobservice、ui等go模块代码都是启动一个运行go:1.7.3的容器,然后把harobr的源码目录映射到启动的容器目录中,进行编译,编译之后会在对应的目录下生成对应模块的可执行文件。以harbor的ui模块为例,makefile中的编译命令如下
@echo "compiling binary for ui (golang image)..."
@echo $(GOBASEPATH)
@echo $(GOBUILDPATH)
@$(DOCKERCMD) run --rm -v $(BUILDPATH):$(GOBUILDPATH) -w $(GOBUILDPATH_UI) $(GOBUILDIMAGE) $(GOIMAGEBUILD) -v -o $(GOBUILDMAKEPATH_UI)/$(UIBINARYNAME)
@echo "Done."
make执行的时候这个build_ui执行的命令即为(我当前的gopath为/data/go_workspace)
docker run --rm -v /data/go_workspace/src/github.com/vmware/harbor:/go/src/github.com/vmware/harbor -w /go/src/github.com/vmware/harbor/ui -v -o /data/go_workspace/src/github.com/vmware/harbor/make/dev/ui/harbor_ui
当然官方自带的ui则是由运行镜像vmware/harbor-clarity-ui-builder:1.2.7的容器进行构建,构建成功之后则会生成几个css、js文件。
docker run --rm -v /data/go_workspace/src/github.com/vmware/harbor/src:/harbor_src vmware/harbor-clarity-ui-builder:1.2.7 /bin/bash /entrypoint.sh
每次编译这些都会耗费很多时间,尤其是ui中的web,每次需要下载很多包。我们完全可以在宿主机上搭建go编译环境,每次快速编译,只需针对jobservice、adminserver、ui三个go模块,其他组件我们基本不会进行改动。
构建镜像
不需要每次都去下载那些依赖组件,可以在官方的基础上构建我们自己的基础镜像。官方构建ui模块的Dockerfile
FROM vmware/photon:1.0 RUN tdnf distro-sync -y || echo \ && tdnf erase vim -y \ && tdnf install sudo -y \ && tdnf clean all \ && groupadd -r -g 10000 harbor && useradd --no-log-init -r -g 10000 -u 10000 harbor \ && mkdir /harbor/ HEALTHCHECK CMD curl -s -o /dev/null -w "%{http_code}" 127.0.0.1:8080/api/systeminfo|grep 200 COPY ./make/dev/ui/harbor_ui ./src/favicon.ico ./make/photon/ui/start.sh ./VERSION /harbor/ COPY ./src/ui/views /harbor/views COPY ./src/ui/static /harbor/static RUN chmod u+x /harbor/start.sh /harbor/harbor_ui WORKDIR /harbor/ ENTRYPOINT ["/harbor/start.sh"]
因为官方的各模块的Dockerfile都是安装vim、sudo包,我们把它作为基础镜像
FROM vmware/photon:1.0 MAINTAINER [email protected] RUN tdnf distro-sync -y || echo \ && tdnf erase vim -y \ && tdnf install sudo -y \ && tdnf clean all \ && groupadd -r -g 10000 harbor && useradd --no-log-init -r -g 10000 -u 10000 harbor \ && mkdir /harbor/
执行 docker build -t xx.com/xx/harbor-photon:1.0 .
之后在我们的base镜像harbor-photon上进行build ui image
FROM xx/xx/harbor-photon:1.0 MAINTAINER [email protected] HEALTHCHECK CMD curl -s -o /dev/null -w "%{http_code}" 127.0.0.1:8080/api/systeminfo|grep 200 COPY harbor_ui favicon.ico start.sh VERSION /harbor/ COPY views /harbor/views COPY static /harbor/static RUN chmod u+x /harbor/start.sh /harbor/harbor_ui WORKDIR /harbor/ ENTRYPOINT ["/harbor/start.sh"]
之后,只需编写一个脚本,从git拉取源码,然后本地直接编译构建镜像,推送到远程仓库惊,应用部署,效率显著提高。