Requests唯一的一个非转基因的Python HTTP库,人类可以安全享用。
警告:非专业使用其他HTTP库会导致危险的副作用,包括:安全缺陷症、冗余代码症、重新发明轮子症、啃文档症、抑郁、头疼、甚至死亡。1
环境准备:
# 新建Python3.x虚拟环境
> mkvirtualenv Py3_requests
# 安装request库
(Py3_requests) > pip install requests
# 环境
(Py3_requests) > python --version
Python 3.7.1
(Py3_requests) > pip list
Package Version
------------ ----------
certifi 2018.11.29
chardet 3.0.4
idna 2.8
pip 19.0.2
requests 2.21.0
setuptools 40.8.0
urllib3 1.24.1
wheel 0.33.0
(Py3_requests) >
Requests类库官方中文文档: http://docs.python-requests.org/zh_CN/latest/index.html
Requests类库GitHub源码:https://github.com/kennethreitz/requests
Requests类库作者Kenneth Reitz博客: https://www.kennethreitz.org
HTTP协议简介
什么是http协议?
- HyperText Transfer Protocol 超文本传输协议
- The Hypertext Transfer Protocol(HTTP) is a stateless(无状态)
application-level protocol for distributed(分布式),
collaborative(协作式), hypertext information systems(超文本信息系统).
curl命令
在Linux中curl是一个利用URL规则在命令行下工作的文件传输工具,可以说是一款很强大的http命令行工具。它支持文件的上传和下载,是综合传输工具,但按传统,习惯称url为下载工具。
语法:$ curl [option] [url]
常用参数:
-v 参数可以显示一次http通信的整个过程,包括端口连接和http request头信息。
(Py3_requests) > curl --help
# ... 省略
(Py3_requests) > curl -v http://www.baidu.com > tmp.txt
* Rebuilt URL to: http://www.baidu.com/
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0* Trying 14.215.177.39...
* TCP_NODELAY set
* Connected to www.baidu.com (14.215.177.39) port 80 (#0)
> GET / HTTP/1.1
> Host: www.baidu.com
> User-Agent: curl/7.55.1
> Accept: */*
>
< HTTP/1.1 200 OK
< Accept-Ranges: bytes
< Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
< Connection: Keep-Alive
< Content-Length: 2381
< Content-Type: text/html
< Date: Sun, 17 Feb 2019 11:18:49 GMT
< Etag: "588604d8-94d"
< Last-Modified: Mon, 23 Jan 2017 13:27:52 GMT
< Pragma: no-cache
< Server: bfe/1.0.8.18
< Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/
<
{ [1040 bytes data]
100 2381 100 2381 0 0 2381 0 0:00:01 --:--:-- 0:00:01 5850
* Connection #0 to host www.baidu.com left intact
(Py3_requests) >

Request
Start Line: 方法 地址 协议
Headers: key:value
> GET / HTTP/1.1 # ... Start Line
# ... Headers
> Host: www.baidu.com
> User-Agent: curl/7.55.1
> Accept: */*
>
Response
Start Line: 协议 状态码 具体解释
Headers: key:value
< HTTP/1.1 200 OK # ... Start Line
# ... Headers
< Accept-Ranges: bytes
< Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
< Connection: Keep-Alive
< Content-Length: 2381
< Content-Type: text/html
< Date: Sun, 17 Feb 2019 11:18:49 GMT
< Etag: "588604d8-94d"
< Last-Modified: Mon, 23 Jan 2017 13:27:52 GMT
< Pragma: no-cache
< Server: bfe/1.0.8.18
< Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/
<
Message Body
打开刚才的tmp.txt文件,html代码已经格式化:
<!DOCTYPE html>
<!--STATUS OK-->
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=Edge" />
<meta content="always" name="referrer" />
<link rel="stylesheet" type="text/css" href="http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css" />
<title>百度一下,你就知道</title>
</head>
<body link="#0000cc">
<div id="wrapper">
<div id="head">
<div class="head_wrapper">
<div class="s_form">
<div class="s_form_wrapper">
<div id="lg">
<img hidefocus="true" src="//www.baidu.com/img/bd_logo1.png" width="270" height="129" />
</div>
<form id="form" name="f" action="//www.baidu.com/s" class="fm">
<input type="hidden" name="bdorz_come" value="1" />
<input type="hidden" name="ie" value="utf-8" />
<input type="hidden" name="f" value="8" />
<input type="hidden" name="rsv_bp" value="1" />
<input type="hidden" name="rsv_idx" value="1" />
<input type="hidden" name="tn" value="baidu" />
<span class="bg s_ipt_wr"><input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off" autofocus="" /></span>
<span class="bg s_btn_wr"><input type="submit" id="su" value="百度一下" class="bg s_btn" /></span>
</form>
</div>
</div>
<div id="u1">
<a href="http://news.baidu.com" name="tj_trnews" class="mnav">新闻</a>
<a href="http://www.hao123.com" name="tj_trhao123" class="mnav">hao123</a>
<a href="http://map.baidu.com" name="tj_trmap" class="mnav">地图</a>
<a href="http://v.baidu.com" name="tj_trvideo" class="mnav">视频</a>
<a href="http://tieba.baidu.com" name="tj_trtieba" class="mnav">贴吧</a>
<noscript>
<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1" name="tj_login" class="lb">登录</a>
</noscript>
<script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');</script>
<a href="//www.baidu.com/more/" name="tj_briicon" class="bri" style="display: block;">更多产品</a>
</div>
</div>
</div>
<div id="ftCon">
<div id="ftConw">
<p id="lh"> <a href="http://home.baidu.com">关于百度</a> <a href="http://ir.baidu.com">About Baidu</a> </p>
<p id="cp">©2017 Baidu <a href="http://www.baidu.com/duty/">使用百度前必读</a> <a href="http://jianyi.baidu.com/" class="cp-feedback">意见反馈</a> 京ICP证030173号 <img src="//www.baidu.com/img/gs.gif" /> </p>
</div>
</div>
</div>
</body>
</html>
本地服务端
http://httpbin.org/ 是Requests作者自己写的服务端,这个网站能测试HTTP请求和响应的各种信息,比如cookie、ip、headers和登录验证等,且支持GET、POST等多种方法,对web开发和测试很有帮助。它用Python+Flask编写,是一个开源项目2。
注意:
Will it work with windows? - No.3
由于windows平台不支持gunicorn,gunicorn安装成功后,启动会出现ModuleNotFoundError: No module named 'fcntl'。
本地启动服务端程序,注意重新开一个concle。Linux下部署:
$ pip3 install httpbin
$ pip3 install gunicorn
# 启动服务
$ gunicorn -b :80 httpbin:app
启动之后可以看到
root@xxx:~# gunicorn -b :80 httpbin:app
[2019-02-19 10:29:26 +0800] [5110] [INFO] Starting gunicorn 19.9.0
[2019-02-19 10:29:26 +0800] [5110] [INFO] Listening at: http://0.0.0.0:80 (5110)
[2019-02-19 10:29:26 +0800] [5110] [INFO] Using worker: sync
[2019-02-19 10:29:26 +0800] [5114] [INFO] Booting worker with pid: 5114
然后访问就行了,这里将ip和域名进行了映射:

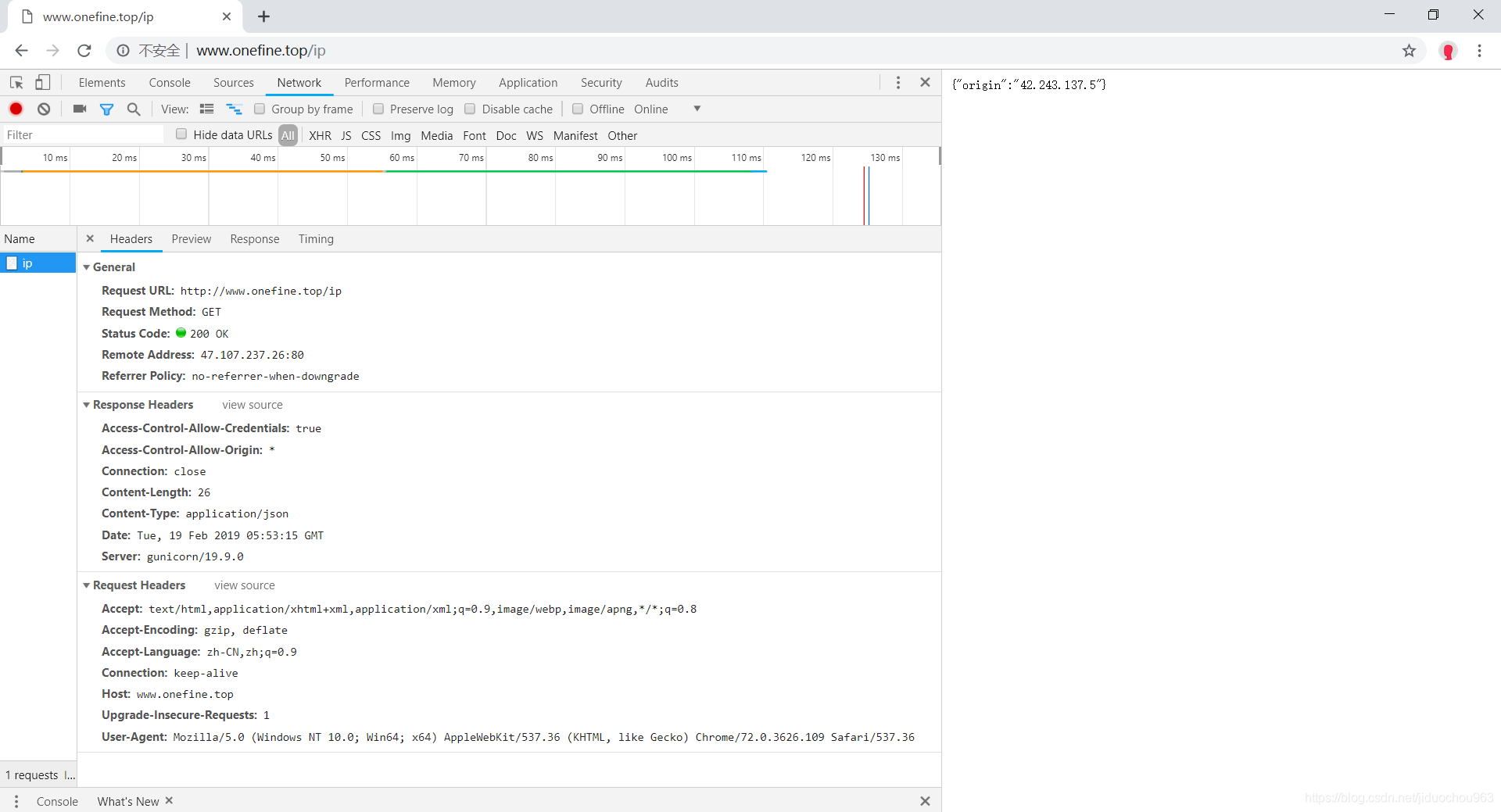
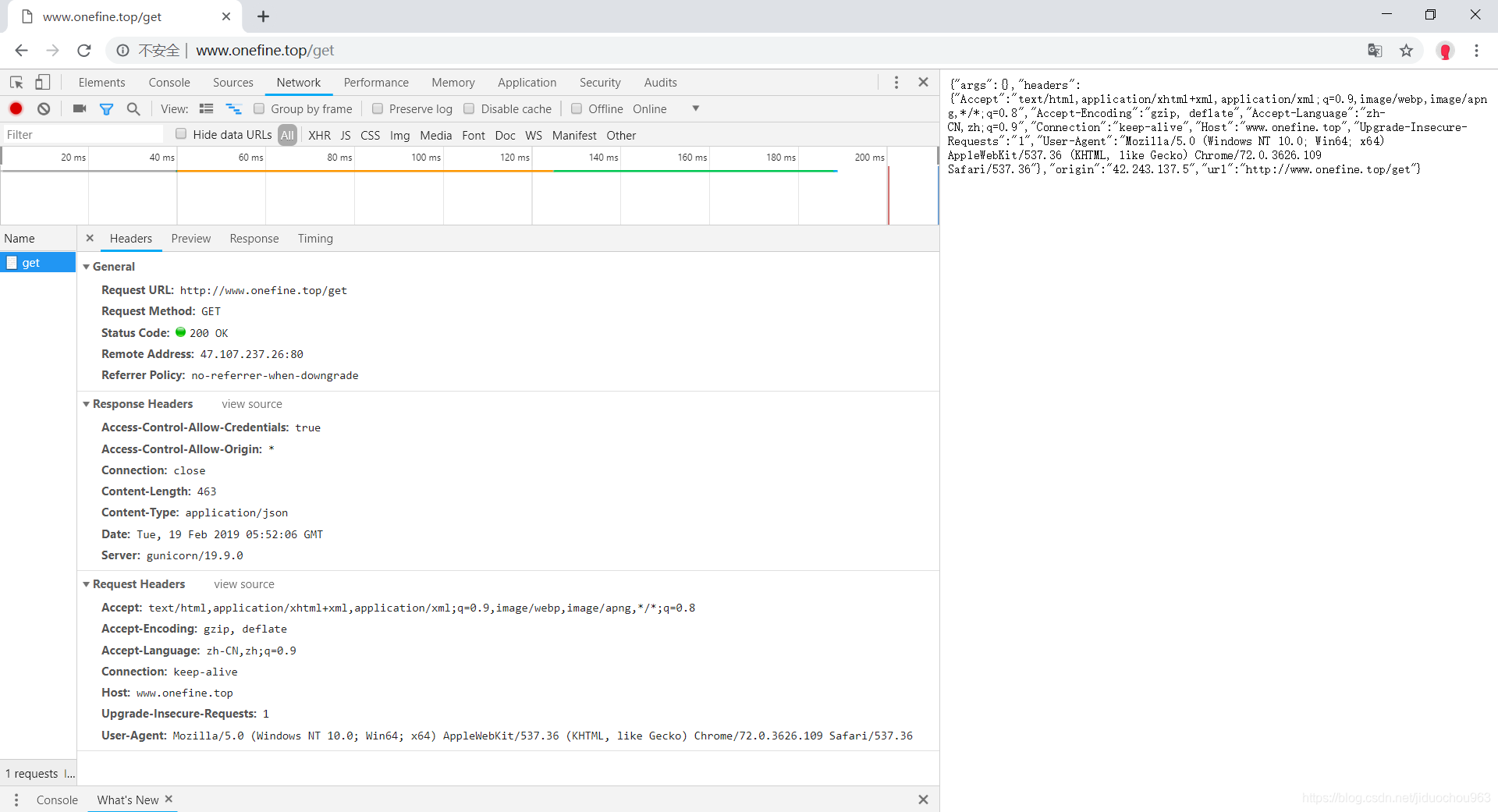
安装到本地后能加快访问速度,更高效帮助我们本地做测试。
1、使用urllib系列4
这里只做简单的介绍。
urllib,urllib2,urllib3是进化关系吗?
- urllib和urllib2是相互独立的模块(Python2.x中),Python3.x将两个模块进行了整合,整合之后的模块为urllib。
- urllib3提供线程安全连接池和文件post等支持,与urllib及urllib2的关系不大。
- requests库使用了urllib3,这样的好处是多次请求使用同一个socket。
注:这里在Python2.7环境
# -*- coding: utf-8 -*-
import urllib
import urllib2
URL_IP = 'http://www.onefine.top/ip'
URL_GET = 'http://www.onefine.top/get'
def use_simple_urllib2():
response = urllib2.urlopen(URL_IP)
print '>>>>Response Headers:'
print response.info() # 读取headers
print '>>>>Response body:'
print ''.join([line for line in response.readlines()]) # 读取body
def use_params_urllib2():
# GET请求,构建请求参数
params = urllib.urlencode({'param1': 'hello', 'param2': 'world'})
print '>>>Request params:'
print params
# 发送请求
response = urllib2.urlopen('?'.join([URL_GET, '%s']) % params)
# 处理响应
print '>>>>Response Headers:'
print response.info()
print '>>>>Status Code:'
print response.getcode()
print '>>>>Request body:'
print ''.join([line for line in response.readlines()])
if __name__ == '__main__':
print '>>>Use simple urllib2:'
use_simple_urllib2()
print ''
print '>>>Use params urllib2:'
use_params_urllib2()
执行结果:
>>>Use simple urllib2:
>>>>Response Headers:
Server: gunicorn/19.9.0
Date: Tue, 19 Feb 2019 05:28:11 GMT
Connection: close
Content-Type: application/json
Content-Length: 26
Access-Control-Allow-Origin: *
Access-Control-Allow-Credentials: true
>>>>Response body:
{"origin":"42.243.137.5"}
>>>Use params urllib2:
>>>Request params:
param2=world¶m1=hello
>>>>Response Headers:
Server: gunicorn/19.9.0
Date: Tue, 19 Feb 2019 05:28:11 GMT
Connection: close
Content-Type: application/json
Content-Length: 250
Access-Control-Allow-Origin: *
Access-Control-Allow-Credentials: true
>>>>Status Code:
200
>>>>Request body:
{"args":{"param1":"hello","param2":"world"},"headers":{"Accept-Encoding":"identity","Connection":"close","Host":"www.onefine.top","User-Agent":"Python-urllib/2.7"},"origin":"42.243.137.5","url":"http://www.onefine.top/get?param2=world¶m1=hello"}
2、使用requests
这里回到Python3.x环境:
# -*- coding: utf-8 -*-
import requests
URL_IP = 'http://www.onefine.top/ip'
URL_GET = 'http://www.onefine.top/get'
def use_simple_requests():
# get/post/options/put/delete
response = requests.get(URL_IP)
print('>>>>Response Headers:')
print(response.headers)
print('>>>>Response body:')
print(response.text) # 不需考虑编码等问题
def use_params_requests():
params = {'param1': 'hello', 'param2': 'world'}
response = requests.get(URL_GET, params=params)
print('>>>>Response Headers:')
print(response.headers)
print('>>>>Status Code:')
print(response.status_code)
print('>>>>Reason:')
print(response.reason)
print('>>>>Request body:')
print(response.text)
if __name__ == '__main__':
print('>>>Use simple requests:')
use_simple_requests()
print('')
print('>>>Use params requests:')
use_params_requests()
执行结果为:
>>>Use simple requests:
>>>>Response Headers:
{'Server': 'gunicorn/19.9.0', 'Date': 'Tue, 19 Feb 2019 05:38:00 GMT', 'Connection': 'close', 'Content-Type': 'application/json', 'Content-Length': '26', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true'}
>>>>Response body:
{"origin":"42.243.137.5"}
>>>Use params requests:
>>>>Response Headers:
{'Server': 'gunicorn/19.9.0', 'Date': 'Tue, 19 Feb 2019 05:38:00 GMT', 'Connection': 'close', 'Content-Type': 'application/json', 'Content-Length': '280', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true'}
>>>>Status Code:
200
>>>>Reason:
OK
>>>>Request body:
{"args":{"param1":"hello","param2":"world"},"headers":{"Accept":"*/*","Accept-Encoding":"gzip, deflate","Connection":"keep-alive","Host":"www.onefine.top","User-Agent":"python-requests/2.21.0"},"origin":"42.243.137.5","url":"http://www.onefine.top/get?param1=hello¶m2=world"}
我们对比一下使用urllib和requests的demo的响应头:
# urllib
"headers": {
"Accept-Encoding": "identity",
"Connection": "close",
"Host": "www.onefine.top",
"User-Agent": "Python-urllib/2.7"
},
# requests
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "keep-alive",
"Host": "www.onefine.top",
"User-Agent": "python-requests/2.21.0"
},
requests库有urllib3的支持,所以将connection状态置为keep-alive,多次请求使用一个连接,消耗更小的资源。
参考:
python中urllib, urllib2,urllib3, httplib,httplib2, request的区别 http://www.cnblogs.com/arxive/p/6194368.html
Python网络请求urllib和urllib3详解 https://www.jianshu.com/p/f05d33475c78
guicorn 是什么 https://www.cnblogs.com/ifkite/p/5460328.html
Linux curl命令详解 https://www.cnblogs.com/duhuo/p/5695256.html
curl 的使用 https://www.jianshu.com/p/f05bbd5007d9
Request类库官方文档 ↩︎
关于urllib的更多介绍,请参阅: https://blog.csdn.net/jiduochou963/article/details/87564467 ↩︎