scrapy简介
- Scrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用
于抓取web站点并从页面中提取结构化的数据。 - Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。
它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版
本又提供了web2.0爬虫的支持。
scrapy优势:
- 用户只需要定制开发几个模块, 就可以轻松实现爬虫, 用来抓取
网页内容和图片, 非常方便; - Scrapy使用了Twisted异步网络框架来处理网络通讯, 加快网页
下载速度, 不需要自己实现异步框架和多线程等, 并且包含了各
种中间件接口, 灵活完成各种需求
爬取网页的步骤
- 确定url地址;
- 获取页面信息;(urllib, requests);
- 解析页面提取需要的数据; (正则表达式, bs4, xpath)
- 保存到本地(csv, json, pymysql, redis);
- 清洗数据(删除不必要的内容 -----正则表达式);
- 分析数据(词云wordcloud + jieba)
组件及流程分析:
1.组件
Scrapy主要包括了以下组件:
- 引擎(Scrapy):用来处理整个系统的数据流, 触发事务(框架核心)
- 调度器(Scheduler):用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader):用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders):爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline): 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares):位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 爬虫中间件(Spider Middlewares): 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出
- 调度中间件(Scheduler Middewares):介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
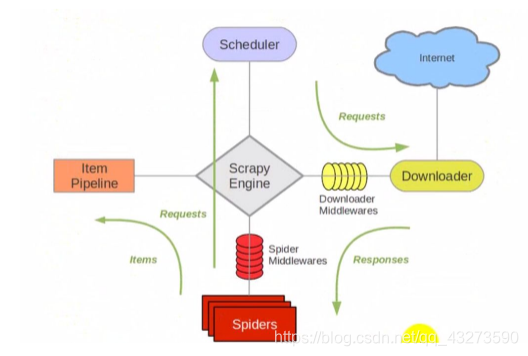
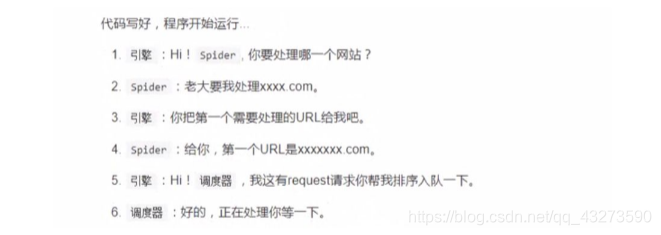
2.流程分析
- 确定url地址:http://www.imooc.com/course/list;(spider)
- 获取页面信息;(urllib, requests); —(scrapy中我们不要处理)—(Downloader)
- 解析页面提取需要的数据; (正则表达式, bs4, xpath)—: (spider)
课程链接, 课程的图片url, 课程的名称, 学习人数, 课程描述 - 保存到本地(csv, json, pymysql, redis); ----(pipeline)

环境
- Scrapy 1.6.0
实现步骤:
项目:爬取mooc上的课程信息
1. 工程创建
创建一个新的Scrapy项目
scrapy startproject mySpider
cd mySpider
tree
├── mySpider
│ ├── __init__.py
│ ├── items.py # 提取的数据信息
│ ├── middlewares.py # 中间键
│ ├── pipelines.py # 管道, 如何存储数据
│ ├── __pycache__
│ ├── settings.py # 设置信息
│ └── spiders # 爬虫(解析页面的信息)
│ ├── __init__.py
│ └── __pycache__
└── scrapy.cfg
2. 创建一个爬虫
scrapy genspider mooc "www.imooc.com"
cd mySpider/spiders/
vim mooc.py
#start_url
3. 定义爬取的items内容
Item 是保存爬取到的数据的容器
import scrapy
class CourseItem(scrapy.Item):
# Item对象是一个简单容器, 保存爬取到的数据, 类似于字典的操作;
# 实例化对象: course = CourseItem()
# course['title'] = "语文"
# course['title']
# course.keys()
# course.values()
# course.items()
# define the fields for your item here like:
# name = scrapy.Field()
# 课程链接, 课程的图片url, 课程的名称, 学习人数, 课程描述
# 课程标题
title = scrapy.Field()
# 课程的url地址
url = scrapy.Field()
# 课程图片url地址
image_url = scrapy.Field()
# 课程的描述
introduction = scrapy.Field()
# 学习人数
student = scrapy.Field()
4. 编写spider代码, 解析
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。
保存在 mySpider/spiders 目录下的 mooc.py 文件中:
import scrapy
from mySpider.items import CourseItem
class MoocSpider(scrapy.Spider):
# name: 用于区别爬虫, 必须是唯一的;
name = 'mooc'
# 允许爬取的域名;其他网站的页面直接跳过;
allowed_domains = ['www.imooc.com', 'img3.mukewang.com']
# 爬虫开启时第一个放入调度器的url地址;
start_urls = ['http://www.imooc.com/course/list']
# 被调用时, 每个出世url完成下载后, 返回一个响应对象,
# 负责将响应的数据分析, 提取需要的数据items以及生成下一步需要处理的url地址请求;
def parse(self, response):
# # 用来检测代码是否达到指定位置, 并用来调试并解析页面信息;
# from scrapy.shell import inspect_response
# inspect_response(response, self)
# 1). 实例化对象, CourseItem
course = CourseItem()
# 分析响应的内容
# scrapy分析页面使用的是xpath语法
# 2). 获取每个课程的信息: <div class="course-card-container">
courseDetails = response.xpath('//div[@class="course-card-container"]')
for courseDetail in courseDetails:
# 课程的名称:
# "htmlxxxx"
# 爬取新的网站, Scrapy里面进行调试(parse命令logging)
course['title'] = courseDetail.xpath('.//h3[@class="course-card-name"]/text()').extract()[0]
# 学习人数
course['student'] = courseDetail.xpath('.//span/text()').extract()[1]
# 课程描述:
course['introduction'] = courseDetail.xpath(".//p[@class='course-card-desc']/text()").extract()[0]
# 课程链接, h获取/learn/9 ====》 http://www.imooc.com/learn/9
course['url'] = "http://www.imooc.com" + courseDetail.xpath('.//a/@href').extract()[0]
# 课程的图片url:
course['image_url'] = 'http:' + courseDetail.xpath('.//img/@src').extract()[0]
yield course
# url跟进, 获取下一页是否有链接;href
url = response.xpath('.//a[contains(text(), "下一页")]/@href')[0].extract()
if url:
# 构建新的url
page = "http://www.imooc.com" + url
yield scrapy.Request(page, callback=self.parse)
- 当输入 response.selector 时, 您将获取到一个可以用于查询返回数据的selector(选择器), 以及映射到 response.selector.xpath() 、 response.selector.css() 的 快捷方法(shortcut): response.xpath() 和 response.css() 。
- 该selector根据response的类型自动选择最合适的分析规则(XML vs HTML)。
如果需要对爬取到的item做更多更为复杂的操作,您可以编写 Pipeline 。 类似于我们在创建项目时对Item做的,用于您编写自己的myspider/pipelines.py 也被创建。 不过如果您仅仅想要保存item,您不需要实现任何的pipeline。
5.
import json
from mySpider.settings import MOOCFilename
from scrapy.pipelines.images import ImagesPipeline
class MyspiderPipeline(object):
"""将爬取的信息保存为Json格式"""
def __init__(self):
self.f = open(MOOCFilename, 'w')
def process_item(self, item, spider):
# 默认传过来的item是json格式
import json
# 读取item中的数据, 并转成json格式;
line = json.dumps(dict(item), ensure_ascii=False, indent=4)
self.f.write(line + '\n')
# 一定要加, 返回给调度为器;
return item
def open_spider(self, spider):
"""开启爬虫时执行的函数"""
pass
def close_spider(self, spider):
"""当爬虫全部爬取结束的时候执行的函数"""
self.f.close()
class CsvPipeline(object):
"""将爬取的信息保存为csv格式"""
def __init__(self):
self.f = open('mooc.csv', 'w')
def process_item(self, item, spider):
# xxxx:xxxxx:xxxx
item = dict(item)
self.f.write("{0}:{1}:{1}\n".format(item['title'], item['student'], item['url']))
# 一定要加, 返回给调度为器;
return item
def open_spider(self, spider):
"""开启爬虫时执行的函数"""
pass
def close_spider(self, spider):
"""当爬虫全部爬取结束的时候执行的函数"""
self.f.close()
import pymysql
class MysqlPipeline(object):
"""
将爬取的信息保存到数据库中
1. 创建mooc数据库
"""
def __init__(self):
super(MysqlPipeline, self).__init__()
self.conn = pymysql.connect(
host='localhost',
user='root',
password='redhat',
db='Mooc',
charset='utf8',
)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
# xxxx:xxxxx:xxxx
# item时一个对象,
item = dict(item)
info = (item['title'], item['url'], item['image_url'], item['introduction'], item['student'])
insert_sqli = "insert into moocinfo values('%s', '%s', '%s', '%s', '%s'); " %(info)
# open('mooc.log', 'w').write(insert_sqli)
# # 用来检测代码是否达到指定位置, 并用来调试并解析页面信息;
self.cursor.execute(insert_sqli)
self.conn.commit()
return item
def open_spider(self, spider):
"""开启爬虫时执行的函数"""
create_sqli = "create table if not exists moocinfo (title varchar(50), url varchar(200), image_url varchar(200), introduction varchar(500), student int)"
self.cursor.execute(create_sqli)
def close_spider(self, spider):
"""当爬虫全部爬取结束的时候执行的函数"""
self.cursor.close()
self.conn.close()
import scrapy
# scrapy框架里面,
class ImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
# 返回一个request请求, 包含图片的url地址
yield scrapy.Request(item['image_url'])
# 当下载请求完成后执行的函数/方法
def item_completed(self, results, item, info):
# open('mooc.log', 'w').write(results)
# 获取下载的地址
image_path = [x['path'] for ok,x in results if ok]
if not image_path:
raise Exception("不包含图片")
else:
return item
6.在myspider/settings.py中加入以下代码
MOOCFilename = "mooc.txt"
ITEM_PIPELINES = {
# 管道的位置: 优先级, 0~1000, 数字越小, 优先级越高;
'mySpider.pipelines.MyspiderPipeline': 300,
'mySpider.pipelines.CsvPipeline': 400,
'mySpider.pipelines.MysqlPipeline': 500,
'mySpider.pipelines.ImagePipeline': 200,
}
IMAGES_STORE = '/home/kiosk/Desktop/day29/mySpider/img'
7.开始爬取
scrapy crawl imooc