版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Shrynh/article/details/87889693
第8章:HBase的应用场景及架构原理
HBase能做什么
- 海量数据存储:
- 海量存储与”关系型“数据库对比:海量-HBase一个表能够存储上百亿的行上百万的列;关系型数据库表里一般列设计不超过30个字段,行一般不超过5百万,否则要分表存储。
- 准实时查询:
- 海量数据能够准实时查询得到。
- HBase是针对海量数据,只有针对海量数据时才会发挥它的优势。如果只有上百万行的话,普通的关系型数据库就可以使用。
HBase在实际业务场景中的应用
-
交通
- 例如GPS信息、路口摄像头数据
-
金融
- 交易信息:取款、贷款信息……
-
电商
- 淘宝、京东……
-
移动电话信息
- 通话记录……
HBase的特点
1.容量大
 2.面向列
2.面向列
 3.多版本
3.多版本
 4.稀疏性
4.稀疏性

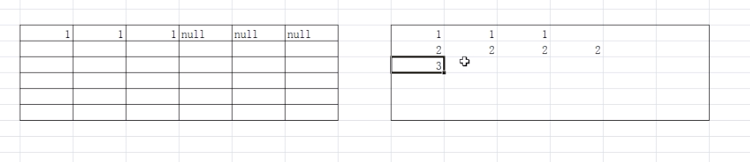 (左边:关系型数据库,确定了列数之后,每一行的数据相应列没有值必须赋空对象。
(左边:关系型数据库,确定了列数之后,每一行的数据相应列没有值必须赋空对象。
右边:列式存储。不需要确定列数,每一行数据需要多少列就存储多少列)
5.扩展性
底层依赖hdfs,磁盘不够的时候,可以直接添加datanode节点就好了。不需要像关系型数据库那样还要做数据迁移。
6.高可靠性
 高性能
高性能

HBase数据模型并举例说明
 举例:(面向列存储的表模型)
举例:(面向列存储的表模型)


(在设计表的时候,不需要设计有几个列,因为列数是没有上线、动态增加的。只需要设计有多少”列簇“就好了)
 (一张表数据很多时,会划分为多个region。会自动切分、也可以人工干预。)
(一张表数据很多时,会划分为多个region。会自动切分、也可以人工干预。)
 (但是HBase不支持条件查询,只支持row-key查询。所以关系型数据库的优势就在于复杂的条件查询。)
(但是HBase不支持条件查询,只支持row-key查询。所以关系型数据库的优势就在于复杂的条件查询。)
HBase表结构模型并举例说明
HBase表结构设计
 (设计只需要指定列簇。列根据数据情况动态增加)
(设计只需要指定列簇。列根据数据情况动态增加)
举例:

说明:
此系列文章为网课学习时所记录的笔记,希望给同为小白的学习者贡献一点帮助吧,如有理解错误之处,还请大佬指出。学习不就是不断纠错不断成长的过程嘛~