在(四)的基础上我们封装了knnClassify和train_test_split的类,具体代码如下,当然也可以直接引入sklearn里面的方法
import numpy as np
from matplotlib import pyplot as plt
from math import sqrt
from collections import Counter
class knnClassify:
def __init__(self,k):
"""初始化编译器"""
self.k = k
self._X_train = None
self._Y_train = None
def fit(self,X_train,Y_train):
'''很简单,喂数据即可'''
assert (X_train.shape[0] == Y_train.shape[0], "the size of X_train must equal Y_train")
self._X_train = X_train
self._Y_train = Y_train
return self
def predict(self,x_predict):
'''对传过来的x_predict进行预测'''
assert (self._X_train is not None and self._Y_train is not None,
"must be not NULL")
y_predict = [self._predict(x) for x in x_predict]
return np.array(y_predict)
def _predict(self,x):
'''进行预测的方法'''
assert (x.shape[0] == self._X_train.shape[1],
"x must equal _X_train")
#获取点与点间的距离,放进distances中去
distances = [sqrt(np.sum((x - x_train)**2)) for x_train in self._X_train]
#按下标进行排序
nearst = np.argsort(distances)
#获取到点的对应y的值
topk_y = [self._Y_train[i] for i in nearst[:self.k]]
#进行统计票数
votes = Counter(topk_y)
#获取到做多票数预测到的结果
return votes.most_common(1)[0][0]
def __repr__(self):
return "KNN(k) = %d" % self.k
另外我们还写了数据分割的代码,分割成训练数据,训练结果,测试数据,测试结果
import numpy as np
def train_test_model(X,Y,test_ratio = 0.2):
'''进行数据集的操作,进行分割操作'''
assert (X.shape[0] == Y.shape[0],
"the size of X must equal y")
assert (0.0 <= test_ratio <= 1.0,
"test_ratio must a vail")
#对X的数据进行索引的乱序
shuffled_indexs = np.random.permutation(len(X))
test_size = int(len(X) * test_ratio)
#测试的索引为乱序的前%20
test_indexs = shuffled_indexs[:test_size]
train_indexs = shuffled_indexs[test_size:]
#训练数据,训练结构的分割
X_train = X[train_indexs]
Y_train = Y[train_indexs]
#测试数据,测试结构的分割
X_test = X[test_indexs]
Y_test = Y[test_indexs]
return X_train,Y_train,X_test,Y_test
现在我们sklearn中的load_digits的数据集来进行操作吧
手写数字的识别
from sklearn import datasets
from matplotlib import pyplot as plt
from sklearn import datasets
from matplotlib import pyplot as plt
digits = datasets.load_digits()
digits.keys()
dict_keys([‘data’, ‘target’, ‘target_names’, ‘images’, ‘DESCR’])
X = digits.data
Y = digits.target
X[123]
array([ 0., 0., 5., 15., 14., 3., 0., 0., 0., 0., 13., 15., 9.,
15., 2., 0., 0., 4., 16., 12., 0., 10., 6., 0., 0., 8.,
16., 9., 0., 8., 10., 0., 0., 7., 15., 5., 0., 12., 11.,
0., 0., 7., 13., 0., 5., 16., 6., 0., 0., 0., 16., 12.,
15., 13., 1., 0., 0., 0., 6., 16., 12., 2., 0., 0.])
some_digist = X[123]
Y[123]
8
some_digist_image = some_digist.reshape(8,8)
plt.imshow(some_digist_image)
plt.imshow(some_digist_image)
<matplotlib.image.AxesImage at 0x29ead4ffba8>
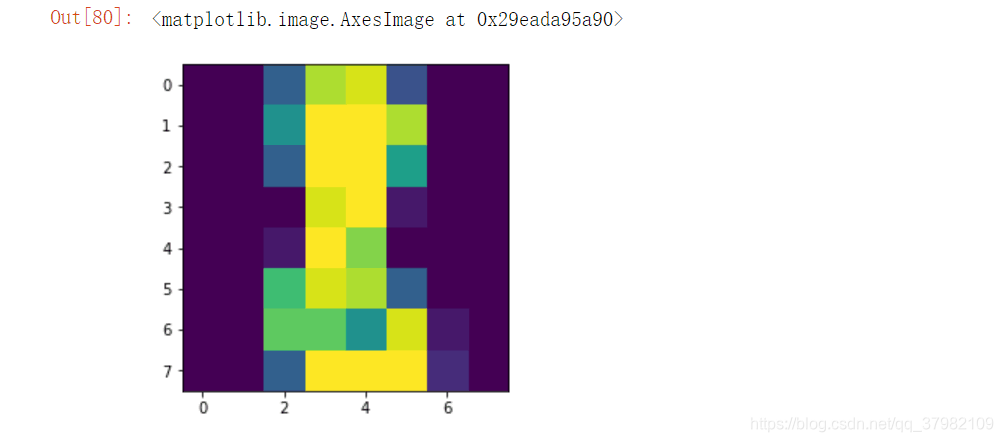
老实讲,这8好抽象呀
分割数据啦
import train_test_model
import train_test_model
X_train,Y_train,X_test,Y_test = train_test_model(X,Y)
测试数据啦
import knnClassify
knn_clf = knnClassify(k = 6)
knn_clf.fit(X_train,Y_train)
KNN(k) = 6
Y_predict = knn_clf.predict(X_test)
sum(Y_predict == Y_test) / len(Y_test)
得出测试结果
0.9860724233983287