关于Python协程的讨论,一般出现最多的几个关键字就是:
- 阻塞
- 非阻塞
- 同步
- 异步
- 并发
- 并行
- 协程
- asyncio
- aiohttp
概念知识的话,感觉以下两篇博文都讲得不错,这里就不转了,直接贴地址:
http://python.jobbole.com/87310/
http://python.jobbole.com/88291/
https://aiohttp.readthedocs.io/en/stable/client_quickstart.html #这个是aiohttp的文档
我在下面的内容就当作一些练习题好了。
- 定义一个协程函数,请求一次腾讯网
import asyncio
import aiohttp
async def get_page(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
page = await resp.text(encoding='GB18030')
print(page)
url = 'https://www.qq.com'
loop = asyncio.get_event_loop()
loop.run_until_complete(get_page(url))
- 给协程添加一个回调函数,抓取腾讯网的标题
import asyncio
import aiohttp
import re
async def get_page(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
page = await resp.text(encoding='GB18030')
return page
def callback(future):
pattern = '<title>(.*?)</title>'
item = re.findall(pattern, future.result())
print(item)
url = 'https://www.qq.com'
loop = asyncio.get_event_loop()
task = asyncio.ensure_future(get_page(url))
task.add_done_callback(callback)
loop.run_until_complete(task)
- 并发请求100次腾讯网,平均耗时约为:2.349秒
import asyncio
import aiohttp
import re
import time
async def get_page(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
page = await resp.text(encoding='GB18030')
return page
def callback(future):
pattern = '<title>(.*?)</title>'
item = re.findall(pattern, future.result())
print(item)
url = 'https://www.qq.com'
loop = asyncio.get_event_loop()
tasks = [asyncio.ensure_future(get_page(url)) for _ in range(100)]
for task in tasks:
task.add_done_callback(callback)
start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
print(time.time() - start)
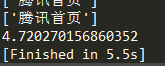

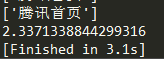
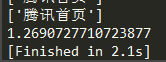
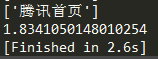
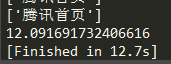
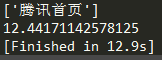
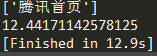
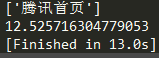
- 上面是利用异步的方式,下面用同步的方式请求100次腾讯网,平均耗时为:12.222秒
import requests
import re
import time
def get_page(url):
resp = requests.get(url)
return resp.text
def parse(page):
pattern = '<title>(.*?)</title>'
item = re.findall(pattern, page)
print(item)
url = 'https://www.qq.com'
start = time.time()
for _ in range(100):
page = get_page(url)
parse(page)
print(time.time() - start)
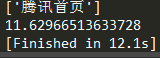
- 接着尝试开100条线程,得出平均耗时为:1.976秒
import requests
import re
import threading
import time
def get_page(url):
resp = requests.get(url)
return resp.text
def parse(page):
pattern = '<title>(.*?)</title>'
item = re.findall(pattern, page)
print(item)
def main(url):
page = get_page(url)
parse(page)
url = 'https://www.qq.com'
ts = [threading.Thread(target=main, args=(url,)) for _ in range(100)]
start = time.time()
for t in ts:
t.start()
for t in ts:
t.join()
print(time.time() - start)
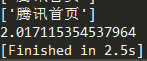
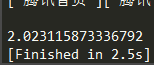
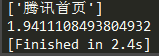
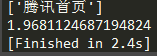
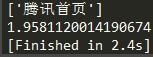
到目前来看,同步多线程的请求方式与异步协程的请求方式,效率是差不多的。
下面再请求另一个网站:豆瓣电影信息,这个网站比起腾讯网首页的响应速度要慢得多。而且我会抓取更多的信息,代码根据我之前的一篇博客来作出一些修改 https://blog.csdn.net/eighttoes/article/details/86159500
- 首先,异步协程的方式请求30次(豆瓣网会封禁爬虫,暂时使用30次),平均耗时为:1.199秒
import asyncio
import aiohttp
import uagent #https://blog.csdn.net/eighttoes/article/details/82996377
import re
import redis
import time
async def get_page(url):
headers = {'User-Agent': uagent.get_ua()}
async with aiohttp.ClientSession() as session:
async with session.get(url, headers=headers) as resp:
page = await resp.text()
return page
#一个回调函数,作用是爬取一些字段用于显示,不用过多关注
def callback(future):
page = future.result()
pattern1 = '<span property="v:itemreviewed">(.*?)</span>'
item1 = re.findall(pattern1, page)
pattern2 = 'rel="v:directedBy">(.*?)</a>'
item2 = re.findall(pattern2, page)
pattern3 = '<span property="v:initialReleaseDate" content="(.*?)">'
item3 = re.findall(pattern3, page)
pattern4 = '<span class="pl">制片国家/地区:</span>(.*?)<br/>'
item4 = re.findall(pattern4, page)
pattern5 = '<span class="pl">片长:</span> <span property="v:runtime" content=".*">(.*?)</span><br/>'
item5 = re.findall(pattern5, page)
pattern6 = '<strong class="ll rating_num" property="v:average">(.*?)</strong>'
item6 = re.findall(pattern6, page)
pattern7 = '<span property="v:genre">(.*?)</span>'
item7 = re.findall(pattern7, page)
pattern8 = '<a href="collections" class="rating_people"><span property="v:votes">(.*?)</span>人评价</a>'
item8 = re.findall(pattern8, page)
print((item1, item2, item3, item4, item5, item6, item7, item8))
#我在redis中保存了一些url,现在从其中取出30个url,准备用于发起请求
r = redis.StrictRedis(host='localhost', port=6379, db=0)
urls = [r.rpop('movie_lists').decode() for _ in range(30)]
tasks = [asyncio.ensure_future(get_page(url)) for url in urls]
for task in tasks:
task.add_done_callback(callback)
loop = asyncio.get_event_loop()
start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
print(time.time() - start)





- 接着用同步多线程的方式,请求30次,平均耗时为:1.126秒
import requests
import uagent #https://blog.csdn.net/eighttoes/article/details/82996377
import re
import redis
import threading
import time
def get_page(url):
headers = {'User-Agent': uagent.get_ua()}
resp = requests.get(url, headers=headers)
page = resp.text
return page
#一个解析字段的函数,作用是爬取一些字段用于显示,不用过多关注
def parse(page):
pattern1 = '<span property="v:itemreviewed">(.*?)</span>'
item1 = re.findall(pattern1, page)
pattern2 = 'rel="v:directedBy">(.*?)</a>'
item2 = re.findall(pattern2, page)
pattern3 = '<span property="v:initialReleaseDate" content="(.*?)">'
item3 = re.findall(pattern3, page)
pattern4 = '<span class="pl">制片国家/地区:</span>(.*?)<br/>'
item4 = re.findall(pattern4, page)
pattern5 = '<span class="pl">片长:</span> <span property="v:runtime" content=".*">(.*?)</span><br/>'
item5 = re.findall(pattern5, page)
pattern6 = '<strong class="ll rating_num" property="v:average">(.*?)</strong>'
item6 = re.findall(pattern6, page)
pattern7 = '<span property="v:genre">(.*?)</span>'
item7 = re.findall(pattern7, page)
pattern8 = '<a href="collections" class="rating_people"><span property="v:votes">(.*?)</span>人评价</a>'
item8 = re.findall(pattern8, page)
print((item1, item2, item3, item4, item5, item6, item7, item8))
def main(url):
page = get_page(url)
parse(page)
#我在redis中保存了一些url,现在从其中取出30个url,准备用于发起请求
r = redis.StrictRedis(host='localhost', port=6379, db=0)
urls = [r.rpop('movie_lists').decode() for _ in range(30)]
ts = [threading.Thread(target=main, args=(url,)) for url in urls]
start = time.time()
for t in ts:
t.start()
for t in ts:
t.join()
print(time.time() - start)





同样的,同步多线程的请求方式与异步协程的请求方式,效率还是相差无几。
- 现在回到请求腾讯网的例子,这次我把异步协程的并发量设置为500,平均耗时为:13.5918秒
import asyncio
import aiohttp
import re
import time
async def get_page(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
page = await resp.text(encoding='GB18030')
return page
def callback(future):
pattern = '<title>(.*?)</title>'
item = re.findall(pattern, future.result())
print(item)
url = 'https://www.qq.com'
loop = asyncio.get_event_loop()
tasks = [asyncio.ensure_future(get_page(url)) for _ in range(500)]
for task in tasks:
task.add_done_callback(callback)
start = time.time()
loop.run_until_complete(asyncio.wait(tasks))
print(time.time() - start)
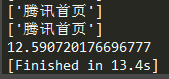

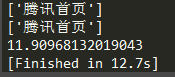
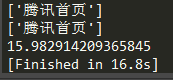
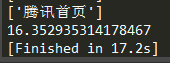
*然后是同步多线程,开500条线程,平均耗时为:10.98秒
import requests
import re
import threading
import time
def get_page(url):
resp = requests.get(url)
return resp.text
def parse(page):
pattern = '<title>(.*?)</title>'
item = re.findall(pattern, page)
print(item)
def main(url):
page = get_page(url)
parse(page)
url = 'https://www.qq.com'
ts = [threading.Thread(target=main, args=(url,)) for _ in range(500)]
start = time.time()
for t in ts:
t.start()
for t in ts:
t.join()
print(time.time() - start)

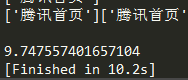
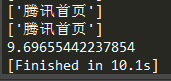
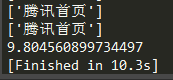
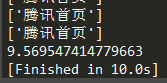
看来同步多线程和异步协程的效率是差不多的。后来我再把协程的并发量增加到1000,程序运行不了了,出现了ValueError: too many file descriptors in select(),不过多线程开到1000条还能运行。
扫描二维码关注公众号,回复:
5302329 查看本文章

既然效率差不多,那么使用哪种编程方式就是看个人喜好了。
这里讨论的效率问题是基于网络IO的情景,其他情景我不知道。