正则表达式是一种字符串匹配和检索的规则,基本各种高级编程语言都实现了正则表达式规则,总体的语法规则也都相似,只是不同的编程语言会有些许的不同。正则表达式主要用在文本提取,笔者主要用在爬虫爬取后的文本数据的清洗,虽然在爬取文本数据时不一定要用正则表达式,比如用Xpath语法就可以快速定位相关数据在网页中的位置,但是当清洗处理爬取后的文本信息时,就需要用到正则表达式了,其简洁性和功能的强大性是不可取代的。
在python中,有一个标准模块re,其实现了所有正则表达式的功能。本文不讲具体的正则表达式的语法,主要讲一下正则表达式中的贪心算法和非贪心算法。要掌握贪心算法和非贪心算法,主要注意两点:1、在匹配时,如果在同一处,不同长度的字符串都符合这个匹配规则,那么贪心算法会选择最长长度进行匹配,非贪心算法会选择最短长度进行匹配;2、要注意正则表达式的匹配的优先级顺序是从左到右的。
下面举几个例子分别说明一下。如图一,用正则表达式语法匹配提前构造的字符串s,利用re模块的findall()方法进行匹配。其中第一条匹配语句中的正则表达式为'..s{3,5}',这里.表示匹配任意字符,{m,n}表示重复前面一个字符m到n次,这里'..s{3,5}'中,由于s可以重复3、4、5次,python正则表达式默认用贪心算法进行匹配,所以当字符串s中可以匹配5次的话,那么python正则表达式便会选择匹配最长的5次,所以这里返回的结果中,第二个为gpsssss,匹配了全部五个s;但是当我们利用非贪心算法进行匹配时,第二个结果中,尽管可以匹配5个s,但是由于是非贪心算法,则python正则表达式会选择匹配最短长度3次,所以返回的结果为gpsss。非贪心算法用?标志,即在特定的正则语法后面添加?就表示其前面的一个正则语法将用最短长度的非贪心算法进行匹配。
 (图一)
(图一)
下面再通过一个例子来说明一下匹配优先级的顺序是从左到右的。如图二,接着上面一个例子中对字符串s的定义,下面第一条匹配语句中,.*(p.*p).*这个语法,.*表示匹配任意字符串,()中的匹配到的内容表示这个函数要返回的结果。由于第一条语句是贪心算法,而且从左边的第一个.*开始匹配,因此这个.*会匹配最长的符合规则的字符串,所以.*后面的匹配将会从s的psssssxp开始,因为这样其左边匹配到的才是最长的,所以就会返回如下的结果。而尽管当在括号里面加上?也没有对结果造成影响,因为优先从左边的第一个.*开始匹配,这样已经可以确定结果了。但是当在第一个.*后面加上?进行非贪心匹配模式时,则左边会选择匹配最短长度,这样就是从s的第一个p开始匹配,接着进行第二个.*匹配,由于这里是贪心模式,所以就会选择最长长度匹配,从而就得到了第三条语句对应的结果。同样的,如果也在第二个.*后面加上?进行非贪心匹配模式,则就会得到pp的结果。
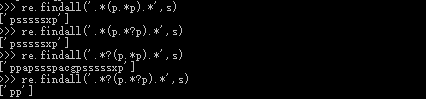 (图二)
(图二)