Java中高级面试题
一.基础知识:
1)集合类:List和Set比较,各自的子类比较(ArrayList,Vector,LinkedList;HashSet,TreeSet);
ArrayList 底层数组实现 地址连续 查询/更改速度快 , 插入/删除速度慢。
Vector 底层数组实现 线程安全 ;很多方法包含了sync标识符; 但性能较低,相比ArrayList。
LinkedList 底层链表实现;查询速度相对较慢,插入、删除速度快。
HashSet 底层Entry数组实现(每个EntryNode会指向下一个,哈希桶、链表);根据Hash算法,设置key,如果哈希碰撞,同一个哈希值下,可能是个线性表(同一Hash值小于8数据),或红黑树(同一Hash值大于等于8个数据,使用二叉树查询、遍历要快一点)。
TreeSet 排序的Set , 二叉排序树实现。
- TreeSet 是二叉树实现的,Treeset中的数据是自动排好序的,不允许放入null值 。
- HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束 。
2)HashMap的底层实现,之后会问ConcurrentHashMap的底层实现;
HashMap 线程不安全 ,底层实现,哈希桶(Node链表、数组),每个Node的key,即Hash值Key,Value可能是个线性表,也可能是个红黑树,如果产生Hash碰撞,同一Key值下,有多个数据,数据个数小于8个,则Value为线性表,如果大于8个,则转化为红黑二叉树,这样查询、遍历效率高些。
ConcurrentHashMap 线程安全 ,采用锁分段技术,将整个Hash桶分成多个segment,每个segment都上了锁。在同一个上锁的segment部分的多线程并发操作是线程安全的;不同segment上的多线程并发操作不是线程安全的,因为锁不是同一个。
3)如何实现HashMap顺序存储:可以参考LinkedHashMap的底层实现;
继承HashMap,如 SortHashMap extends HashMap ,然后HashMap里面的每个Node都增加指向before、after的变量,即所有节点构成一个具有顺序的链表,每次添加Key/Value时,安装某中顺序插入链表中,这里按顺序存储插入链表,可以每次插入链表尾部;遍历SortHashMap时,每次访问当前节点的Next,直到tail为止,即可。
4)HashTable和ConcurrentHashMap的区别;
HashTable 线程安全,但是性能低下,因为多线程访问时,对整个数据结构上锁,当数据量大时,访问性能急剧下降。
ConcurrentHashMap 线程安全,但是性能较高,当数据量大时,访问性能不会怎么下降,因为ConcurrentHashMap,采用锁分段技术,只是上锁一部分数据,多线程访问其他分段数据不受影响。
5)String,StringBuffer和StringBuilder的区别;
速度 StringBuilder (线程不安全)> StringBuffer (线程安全) > String
6)Object的方法有哪些:比如有wait方法,为什么会有;
wait notify notifyall 方法
wait 用于在同步代码块或上锁的代码块中,释放锁资源,然后线程进入等待状态,notify、notifyall 可以唤醒等待资源的线程
7)wait和sleep的区别,必须理解;
sleep Thread类上方法 ,释放资源 ,但不释放锁
wait Object类上方法,放资源,进入等待区,释放锁,需要notify唤醒
8)JVM的内存结构,JVM的算法;
JVM 栈 堆 程序计数器 本地方法栈 方法区
JVM算法 主要是 GC算法 G1GC ZGC
垃圾回收算法
- 标记-清除算法:首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象。
- 复制-收集算法:将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。
- 标记-压缩算法:标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存
- 分代收集算法:把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记-清理”或“标记-整理”算法来进行回收。
垃圾回收器
Serial串行收集器
- 参数控制:-XX:+UseSerialGC 串行收集器
ParNew收集器
- 参数控制:-XX:+UseParNewGC ParNew收集器 -XX:ParallelGCThreads 限制线程数量
Parallel收集器
- 参数控制:-XX:+UseParallelGC 使用Parallel收集器+ 老年代串行
Parallel Old收集器
- 参数控制: -XX:+UseParallelOldGC 使用Parallel收集器+ 老年代并行
CMS收集器
- 参数控制:-XX:+UseConcMarkSweepGC 使用CMS收集器 -XX:+ UseCMSCompactAtFullCollection Full GC后,进行一次碎片整理;整理过程是独占的,会引起停顿时间变长 -XX:+CMSFullGCsBeforeCompaction 设置进行几次Full GC后,进行一次碎片整理 -XX:ParallelCMSThreads 设定CMS的线程数量(一般情况约等于可用CPU数量)
G1收集器
- 空间整合,G1收集器采用标记整理算法,不会产生内存空间碎片。分配大对象时不会因为无法找到连续空间而提前触发下一次GC。
- 可预测停顿,这是G1的另一大优势,降低停顿时间是G1和CMS的共同关注点,但G1除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为N毫秒的时间片段内,消耗在垃圾收集上的时间不得超过N毫秒,这几乎已经是实时Java(RTSJ)的垃圾收集器的特征了。
ZGC收集器 可伸缩 低延迟 垃圾收集器
- 停顿时间不会超过10ms
- 停顿时间不会随着堆的增大而增大(不管多大的堆都能保持在10ms以下)
- 可支持几百M,甚至几T的堆大小(最大支持4T)
9)强引用,软引用和弱引用的区别;
强引用 new出来的对象的引用
软引用 内存不足时,需要回收的引用
弱引用 GC时,需要回收的引用
虚引用 即将被回收的引用,被回收前虚引用会加入引用队列,程序可以根据引用队列中是否含有引用,来跟着JVM的GC回收活动
类型 回收时间 使用场景
强引用 一直存活,除非GC Roots不可达 所有程序的场景,基本对象,自定义对象等。
软引用 内存不足时会被回收 对内存敏感的资源,缓存,如:网页缓存、图片缓存
弱引用 只能存活到下一次GC前 生命周期很短的对象,例如ThreadLocal中的Key。
虚引用 随时会被回收,创建后很快被回收 业界暂无使用场景, 可能被JVM团队内部用来跟踪JVM的垃圾回收活动
10)数组在内存中如何分配;
参考资料:https://blog.csdn.net/Aria_Miazzy/article/details/87870466
11)用过哪些设计模式,手写一个(除单例);
12)Springmvc的核心是什么,请求的流程是怎么处理的,控制反转怎么实现的;
SpringMVC核心:DispatcherSerlet请求分发
请求流程:
- (1)请求发送至前端控制器DispatcherServlet
- (2)前端控制器收到请求调用HandlerMapping处理器映射器
- (3)处理器映射器根据请求url找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet
- (4)DispatcherServlet通过HandlerAdapter处理器调用处理器
- (5)执行处理器
- (6)Controller执行完返回ModelAndView
- (7)HandlerAdapter将ModelAndView返回给DispatcherServlet
- (8)DispatcherServlet将ModelAndView传给ViewReslover视图解析器
- (9)ViewReslover解析后返回具体的View
- (10)DisaptcherServlet对View进行渲染视图
- (11)DispatcherServlet响应用户
控制反转:
Spring的ApplicationContext 容器或者BeanFactory容器,根据XML配置或者注解,实现依赖注入和自动装配
13)Spring里面的aop的原理是什么;
Spring AOP 利用JAVA的动态代理和静态代理技术实现
14)Mybatis如何处理结果集:反射,建议看看源码;
参考资料:https://blog.csdn.net/wuskzuo/article/details/79186144
15)Java的多态表现在哪里;
Java作为面向对象的语言,同样可以描述一个事物的多种形态。如Student类继承了Person类,一个Student的对象便既是Student,又是Person。一个Student对象既可以赋值给一个Student类型的引用,也可以赋值给一个Person类型的引用。
- 普通类多态定义的格式 子类继承父类 父类 变量名 = new 子类();
- 抽象类多态定义的格式 子类实现&继承抽象类 抽象类 变量名 = new 子类();
- 接口多态定义的格式 实现类 实现 接口 接口 变量名 = new 接口();
16)接口有什么用;
(一)接口是一种规范,而且具体的实现交由具体的特定场景下的实现类实现,以便在以后需求变更后,可以轻松添加新的实现类来满足新的业务需求。
- 软件开发大多是一个协作性的工作:电器和插座分别是不同人完成的,有了接口大家就能分头开干,都按照接口来办事,各自做完就能轻松地整合到一起。各部分的测试也更加方便。
- 软件需要不断演化:今天你用了公牛的插座,过了一年你可能换个西门子的插座,要做没有这套国家接口标准,各自为政,那估计你是换不了插座了。你想想,咱们每次去美国出差,都得带个转接头,否则就跪了,多不方便啊,因为接口规范不同啊!(这些个转接头你是不是闻道一种浓浓的Adapter模式的味道)。
注意:直接写实现的方式在确定性的场景下当然也可以,不涉及到分工协作、变化性、测试方便等因素时,当然用不着接口了。比如一般情况下你犯不着为一个Pojo的getter和setter也弄个接口和实现分离。
(二)接口在开发过程中可以快速分离工作内容。
- 比如调用者在写业务逻辑的时候需要一个功能,可能是数据库访问,或者复杂计算,但是他的工作专注于实现业务逻辑,不想分开精力去做底层实现,那么他只需要先实现一个接口,定义了规范,然后就可以继续他的业务逻辑代码了。而实现者可以根据这个接口规范,做具体的实现。
- 这样通过使用接口就可以快速的分离工作内容,达到团队并行工作的目的。
- 此外,如果规范是通过接口定义的,那么当你这个功能有多个实现时,你只要实现了这个接口,那么可以快速的替换具体实现,做到代码层面的完全可以分离。
总结:接口或者规范可以在开发过程中做到分离。
17)说说HTTP , HTTPS协议;
HTTPS和HTTP的区别主要为以下四点:
- 一、https协议需要到ca申请证书,一般免费证书很少,需要交费。
- 二、http是超文本传输协议,信息是明文传输,https 则是具有安全性的ssl加密传输协议。
- 三、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
- 四、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
18)TCP/IP协议簇;
SLIP协议
SLIP提供在串行通信线路上封装IP分组的简单方法,使远程用户通过电话线和MODEM能方便地接入TCP/IP网络。SLIP是一种简单的组帧方式,但使用时还存在一些问题。首先,SLIP不支持在连接过程中的动态IP地址分配,通信双方必须事先告知对方IP地址,这给没有固定IP地址的个人用户上INTERNET网带来了很大的不便。其次,SLIP帧中无校验字段,因此链路层上无法检测出差错,必须由上层实体或具有纠错能力MODEM来解决传输差错问题。
PPP协议
为了解决SLIP存在的问题,在串行通信应用中又开发了PPP协议。PPP协议是一种有效的点对点通信协议,它由串行通信线路上的组帧方式,用于建立、配制、测试和拆除数据链路的链路控制协议LCP及一组用以支持不同网络层协议的网络控制协议NCPs三部分组成。PPP中的LCP协议提供了通信双方进行参数协商的手段,并且提供了一组NCPs协议,使得PPP可以支持多种网络层协议,如IP,IPX,OSI等。另外,支持IP的NCP提供了在建立链接时动态分配IP地址的功能,解决了个人用户上INTERNET网的问题。
IP协议
即互联网协议(Internet Protocol),它将多个网络连成一个互联网,可以把高层的数据以多个数据包的形式通过互联网分发出去。IP的基本任务是通过互联网传送数据包,各个IP数据包之间是相互独立的。
ICMP协议
即互联网控制报文协议。从IP互联网协议的功能,可以知道IP 提供的是一种不可靠的无连接报文分组传送服务。若路由器或主机发生故障时网络阻塞,就需要通知发送主机采取相应措施。为了使互联网能报告差错,或提供有关意外情况的信息,在IP层加入了一类特殊用途的报文机制,即ICMP。分组接收方利用ICMP来通知IP模块发送方,进行必需的修改。ICMP通常是由发现报文有问题的站产生的,例如可由目的主机或中继路由器来发现问题并产生的ICMP。如果一个分组不能传送,ICMP便可以被用来警告分组源,说明有网络,主机或端口不可达。ICMP也可以用来报告网络阻塞。
ARP协议
即地址转换协议。在TCP/IP网络环境下,每个主机都分配了一个32位的IP地址,这种互联网地址是在网际范围标识主机的一种逻辑地址。为了让报文在物理网上传送,必须知道彼此的物理地址。这样就存在把互联网地址变换成物理地址的转换问题。这就需要在网络层有一组服务将 IP地址转换为相应物理网络地址,这组协议即ARP。
TCP协议
即传输控制协议,它提供的是一种可靠的数据流服务。当传送受差错干扰的数据,或举出网络故障,或网络负荷太重而使网际基本传输系统不能正常工作时,就需要通过其他的协议来保证通信的可靠。TCP就是这样的协议。TCP采用“带重传的肯定确认”技术来实现传输的可靠性。并使用“滑动窗口”的流量控制机制来提高网络的吞吐量。TCP通信建立实现了一种“虚电路”的概念。双方通信之前,先建立一条链接然后双方就可以在其上发送数据流。这种数据交换方式能提高效率,但事先建立连接和事后拆除连接需要开销。
UDP协议
即用户数据包协议,它是对IP协议组的扩充,它增加了一种机制,发送方可以区分一台计算机上的多个接收者。每个UDP报文除了包含数据外还有报文的目的端口的编号和报文源端口的编号,从而使UDP软件可以把报文递送给正确的接收者,然后接收者要发出一个应答。由于UDP的这种扩充,使得在两个用户进程之间递送数据包成为可能。我们频繁使用的OICQ软件正是基于UDP协议和这种机制。
FTP协议
即文件传输协议,它是网际提供的用于访问远程机器的协议,它使用户可以在本地机与远程机之间进行有关文件的操作。FTP工作时建立两条TCP链接,分别用于传送文件和用于传送控制。FTP采用客户/服务器模式?它包含客户FTP和服务器FTP。客户FTP启动传送过程,而服务器FTP对其作出应答。
DNS协议
即域名服务协议,它提供域名到IP地址的转换,允许对域名资源进行分散管理。DNS最初设计的目的是使邮件发送方知道邮件接收主机及邮件发送主机的IP地址,后来发展成可服务于其他许多目标的协议。
SMTP协议
即简单邮件传送协议互联网标准中的电子邮件是一个简单的基于文本的协议,用于可靠、有效地数据传输。SMTP作为应用层的服务,并不关心它下面采用的是何种传输服务,它可通过网络在TXP链接上传送邮件,或者简单地在同一机器的进程之间通过进程通信的通道来传送邮件,这样,邮件传输就独立于传输子系统,可在TCP/IP环境或X.25协议环境中传输邮件。
19)OSI七层网络协议;
一、OSI七层模型
OSI七层协议模型主要是:应用层(Application)、表示层(Presentation)、会话层(Session)、传输层(Transport)、网络层(Network)、数据链路层(Data Link)、物理层(Physical)。
二、TCP/IP四层模型
TCP/IP是一个四层的体系结构,主要包括:应用层、运输层、网际层和网络接口层。从实质上讲,只有上边三层,网络接口层没有什么具体的内容。
三、五层体系结构
五层体系结构包括:应用层、运输层、网络层、数据链路层和物理层。
五层协议只是OSI和TCP/IP的综合,实际应用还是TCP/IP的四层结构。为了方便可以把下两层称为网络接口层。
三种模型结构: 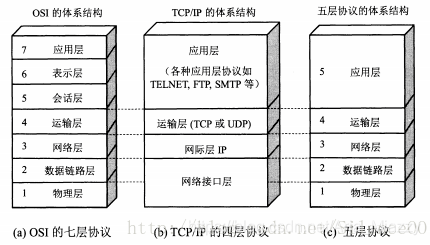

各层的作用
1、物理层:
主要定义物理设备标准,如网线的接口类型、光纤的接口类型、各种传输介质的传输速率等。它的主要作用是传输比特流(就是由1、0转化为电流强弱来进行传输,到达目的地后在转化为1、0,也就是我们常说的数模转换与模数转换)。这一层的数据叫做比特。
2、数据链路层:
定义了如何让格式化数据以进行传输,以及如何让控制对物理介质的访问。这一层通常还提供错误检测和纠正,以确保数据的可靠传输。
3、网络层:
在位于不同地理位置的网络中的两个主机系统之间提供连接和路径选择。Internet的发展使得从世界各站点访问信息的用户数大大增加,而网络层正是管理这种连接的层。
4、运输层:
定义了一些传输数据的协议和端口号(WWW端口80等),如:
TCP(transmission control protocol –传输控制协议,传输效率低,可靠性强,用于传输可靠性要求高,数据量大的数据)
UDP(user datagram protocol–用户数据报协议,与TCP特性恰恰相反,用于传输可靠性要求不高,数据量小的数据,如QQ聊天数据就是通过这种方式传输的)。 主要是将从下层接收的数据进行分段和传输,到达目的地址后再进行重组。常常把这一层数据叫做段。
5、会话层:
通过运输层(端口号:传输端口与接收端口)建立数据传输的通路。主要在你的系统之间发起会话或者接受会话请求(设备之间需要互相认识可以是IP也可以是MAC或者是主机名)
6、表示层:
可确保一个系统的应用层所发送的信息可以被另一个系统的应用层读取。例如,PC程序与另一台计算机进行通信,其中一台计算机使用扩展二一十进制交换码(EBCDIC),而另一台则使用美国信息交换标准码(ASCII)来表示相同的字符。如有必要,表示层会通过使用一种通格式来实现多种数据格式之间的转换。
7、应用层:
是最靠近用户的OSI层。这一层为用户的应用程序(例如电子邮件、文件传输和终端仿真)提供网络服务。
20)TCP,UDP区别;
| TCP | UDP | |
|---|---|---|
| 首字母缩略词 | 传输控制协议 | 用户数据报协议或通用数据报协议 |
| 连接 | TCP是面向连接的协议。 | UDP是一种无连接协议。 |
| 功能 | 作为消息使得它的方式横跨互联网从一台计算机到另一台。这是基于连接的。 | UDP也是用于消息传输或传输的协议。这不是基于连接的,这意味着一个程序可以将一大包数据包发送到另一个程序,这将是关系的结束。 |
| 用法 | TCP适用于要求高可靠性的应用,传输时间相对不太重要。 | UDP适用于需要快速,高效传输的应用程序,例如游戏。UDP的无状态特性对于回答来自大量客户端的小型查询的服务器也很有用。 |
| 使用其他协议 | HTTP,HTTP,FTP,SMTP,Telnet | DNS,DHCP,TFTP,SNMP,RIP,VOIP。 |
| 订购数据包 | TCP 按指定的顺序重新排列数据包。 | UDP没有固有的顺序,因为所有数据包都是相互独立的。如果需要订购,则必须由应用程序层进行管理。 |
| 转移速度 | TCP的速度比UDP慢。 | UDP速度更快,因为未尝试进行错误恢复。这是一个“尽力而为”的协议。 |
| 可靠性 | 绝对保证传输的数据保持不变,并按照发送的顺序到达。 | 无法保证发送的消息或数据包完全无法访问。 |
| 标题大小 | TCP标头大小为20个字节 | UDP标头大小为8个字节。 |
| 常用标题字段 | 源端口,目标端口,校验和 | 源端口,目标端口,校验和 |
| 流式传输数据 | 数据作为字节流读取,没有区别指示被发送到信号消息(段)边界。 | 数据包是单独发送的,只有在到达时才会检查其完整性。数据包具有明确的边界,这些边界在接收时受到尊重,这意味着接收器插槽上的读取操作将产生最初发送的整个消息。 |
| 重量 | TCP很重。在发送任何用户数据之前,TCP需要三个数据包来建立套接字连接。TCP处理可靠性和拥塞控制。 | UDP很轻巧。没有消息排序,没有跟踪连接等。它是在IP之上设计的小型传输层。 |
| 数据流控制 | TCP执行流量控制。在发送任何用户数据之前,TCP需要三个数据包来建立套接字连接。TCP处理可靠性和拥塞控制。 | UDP没有流控制选项 |
| 错误检查 | TCP执行错误检查和错误恢复。错误的数据包从源重新传输到目的地。 | UDP执行错误检查,但只是丢弃错误的数据包。未尝试错误恢复。 |
| 字段 | 1.序列号,2。响应号,3。数据偏移,4。保留,5。控制位,6。窗口,7。紧急指针8.选项,9。填充,10。检查总和,11。源端口, 12.目的港 | 1.长度,2。源端口,3。目标端口,4。检查总和 |
| 承认 | 致谢部分 | 没有确认 |
| 握手 | SYN,SYN-ACK,ACK | 无握手(无连接协议) |
数据传输功能的差异
TCP 确保从用户到服务器的可靠和有序的字节流传递,反之亦然。UDP不专用于端到端连接,并且通信不检查接收器的准备情况。
可靠性
TCP更可靠,因为它在部件丢失的情况下管理消息确认和重传。因此绝对没有丢失的数据。UDP不确保通信已到达接收器,因为不存在确认,超时和重传的概念。
顺序
TCP传输按顺序发送,并以相同的顺序接收。如果数据段以错误的顺序到达,TCP会重新排序并提供应用程序。在UDP的情况下,当到达接收应用程序时可能不保持发送的消息序列。绝对没有办法预测接收消息的顺序。
连接
TCP是一种重量级连接,需要三个数据包用于套接字连接,并处理拥塞控制和可靠性。UDP是在IP上设计的轻量级传输层。没有跟踪连接或消息排序。
转移方法
TCP将数据作为字节流读取,并将消息传输到段边界。UDP消息是单独发送的数据包,并在到达时检查其完整性。数据包没有定义边界的数据包。
错误检测
UDP在“尽力而为”的基础上工作。该协议支持通过校验和进行错误检测,但是当检测到错误时,数据包将被丢弃。不尝试重新传输数据包以从该错误中恢复。这是因为UDP通常用于时间敏感的应用程序,如游戏或语音传输。从错误中恢复将毫无意义,因为在收到重新传输的数据包时,它将没有任何用处。
TCP使用错误检测和错误恢复。通过校验和检测错误,如果数据包是错误的,则接收方不会对其进行确认,这会触发发送方的重传。该操作机制称为具有重传(PAR)的肯定确认。
参考资料:https://blog.csdn.net/Aria_Miazzy/article/details/87887059
21)用过哪些加密算法:对称加密,非对称加密算法;
DES(Data Encryption Standard):对称算法,数据加密标准,速度较快,适用于加密大量数据的场合;
3DES(Triple DES):是基于DES的对称算法,对一块数据用三个不同的密钥进行三次加密,强度更高;
RC2和RC4:对称算法,用变长密钥对大量数据进行加密,比 DES 快;
IDEA(International Data Encryption Algorithm)国际数据加密算法,使用 128 位密钥提供非常强的安全性;
RSA:由 RSA 公司发明,是一个支持变长密钥的公共密钥算法,需要加密的文件块的长度也是可变的,非对称算法;
22)说说TCP三次握手,四次挥手;
TCP三次握手

TCP四次挥手

23)Cookie和Session的区别,分布式环境怎么保存用户状态;
Cookie 浏览器上保存的键值对信息,可以设置超时时间,服务器端在不跨域的情况下可以读/写操作
Session 需要在浏览器上保存一个SessionID的Key/Value键值对Cookie信息,然后其他信息保存在服务器端
24)Git,SVN区别;
Git:分布式代码版本管理工具
SVN:集中式代码版本管理工具
25)请写一段栈溢出、堆溢出的代码;
栈溢出:不停的递归调用
堆溢出:不停的创建新对象
26)ThreadLocal可以用来共享数据吗;
ThreadLocal:解决多线程并发访问,每个线程访问独立的变量副本,因为每个线程访问的变量副本是隔离的,其实不算共享变量,是解决多线程并发访问的一种思路,但各个线程访问的数据是不同的,由于数据副本是独立的,不会出现并发访问,当然就是线程安全的。
1.synchronized 用于同步方法和代码块,执行完后自动释放锁
2.Lock是一个锁的接口,提供获取锁和解锁的方法(lock,trylock,unlock)
3.ReentrantLock 重入锁
Lock有一个实现类:ReentrantLock,它实现了Lock里面的方法,但是使用Lock的时候必须注意它不会像synchronized执行完成之后或者抛出异常之后自动释放锁,而是需要你主动释放锁,所以我们必须在使用Lock的时候加上try{}catch{}finally{}块,并且在finally中释放占用的锁资源。
Lock和synchronized最大的区别就是当使用synchronized,一个线程抢占到锁资源,其他线程必须像SB一样得等待;而使用Lock,一个线程抢占到锁资源,其他的线程可以不等待或者设置等待时间,实在抢不到可以去做其他的业务逻辑。
4.ReadWriteLock 读写锁
它可以实现读写锁,当读取的时候线程会获得read锁,其他线程也可以获得read锁同时并发的去读取,但是写程序运行获取到write锁的时候,其他线程是不能进行操作的,因为write是排它锁,而上面介绍的两种不管你是read还是write没有抢到锁的线程都会被阻塞或者中断,它也是个接口,里面定义了两种方法readLock()和writeLock(),他的一个实现类是ReentrantReadWriteLock。
threadlocal怎么解决线程同步问题?
而ThreadLocal则从另一个角度来解决多线程的并发访问。ThreadLocal会为每一个线程提供一个独立的变量副本,从而隔离了多个线程对数据的访问冲突。因为每一个线程都拥有自己的变量副本,从而也就没有必要对该变量进行同步了。ThreadLocal提供了线程安全的共享对象,在编写多线程代码时,可以把不安全的变量封装进ThreadLocal。
27)什么是Java的内存泄漏;
参考资料:https://blog.csdn.net/Aria_Miazzy/article/details/87870537
二.IO:
1)bio,nio,aio的区别;
2)nio框架:dubbo的实现原理;
3)京东内部的jsf是使用的什么协议通讯:可参见dubbo的协议;
三.算法:
1)java中常说的堆和栈,分别是什么数据结构;另外,为什么要分为堆和栈来存储数据。
2)TreeMap如何插入数据:二叉树的左旋,右旋,双旋;
3)一个排序之后的数组,插入数据,可以使用什么方法?答:二分法;问:时间复杂度是多少?
4)平衡二叉树的时间复杂度;
5)Hash算法和二叉树算法分别什么时候用;
6)图的广度优先算法和深度优先算法:详见jvm中垃圾回收实现;
三.多线程相关:
1)说说阻塞队列的实现:可以参考ArrayBlockingQueue的底层实现(锁和同步都行);
2)进程通讯的方式:消息队列,共享内存,信号量,socket通讯等;
3)用过并发包的哪些类;
4)什么地方用了多线程;
5)Excutors可以产生哪些线程池;
6)为什么要用线程池;
7)volatile关键字的用法:使多线程中的变量可见;
四.数据库相关(mysql):
1)msyql优化经验:
2)mysql的语句优化,使用什么工具;
3)mysql的索引分类:B+,hash;什么情况用什么索引;
4)mysql的存储引擎有哪些,区别是什么;
5)说说事务的特性和隔离级别;
6)悲观锁和乐观锁的区别,怎么实现;
五.消息队列:
1)mq的原理是什么:有点大。。都可以说;
2)mq如何保证实时性;
3)mq的持久化是怎么做的;
六.nosql相关(主要是redis):
1)redis和memcache的区别;
2)用redis做过什么;
3)redis是如何持久化的:rdb和aof;
4)redis集群如何同步;
5)redis的数据添加过程是怎样的:哈希槽;
6)redis的淘汰策略有哪些;
7)redis有哪些数据结构;
七.zookeeper:
1)zookeeper是什么;
2)zookeeper哪里用到;
3)zookeeper的选主过程;
4)zookeeper集群之间如何通讯;
5)你们的zookeeper的节点加密是用的什么方式;
6)分布式锁的实现过程;
八.linux相关:
1)linux常用的命令有哪些;
2)如何获取java进程的pid;
3)如何获取某个进程的网络端口号;
4)如何实时打印日志;
5)如何统计某个字符串行数;
九.设计与思想:
1)重构过代码没有?说说经验;
2)一千万的用户实时排名如何实现;
3)五万人并发抢票怎么实现;