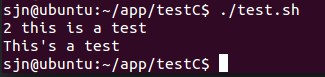
首先创建一个log.txt文件,内容如下,供测试使用
2 this is a test
3 Are you like awk
This's a test
10 There are orange,apple,mongo1.找出该文件每行的第一个字符串和第三个字符串,并输出
awk '{print $1,$3}' log.txt
$1和$3代表每行的第一个字符串和第三个字符串,互相要用“,”隔开,默认是按照空格来确定是第几个字符串
2.查找按照逗号隔开的第一个和第三个字符串
awk -F, '{print $1,$3}' log.txt
-F可设置区分是第几个字符串的规则,本例设置成按照逗号区分
3.修改字符串的值后输出
awk -v a=1 '{print $1,$1+a}' log.txt
awk -v a=1 -v b=sjn '{print $1,$1+a,$1b}' log.txt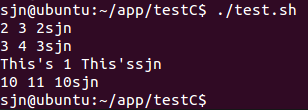
-v设置变量值
4.查找第一个字符串小于3的行,并输出
查找第一个字符等于2的行,并输出
查找第一个字符串大于2且第二个字符串等于Are的行,并输出
awk '$1<3' log.txt
awk '$1==2 {print $1,$2}' log.txt
awk '$1>2 && $2=="Are" {print $3,$4}' log.txt


5.查找带有字符串“re”的行,并输出(区分大小写)
查找不含有字符串“th”的行,并输出(区分大小写)
查找含有字符串“this”的行,并输出(不区分大小写)
awk '/re/' log.txt
awk '!/th/' log.txt
awk 'BEGIN{IGNORECASE=1} /this/' log.txt