一.redis持久化
1.RDB快照(snapshot)
在默认情况下, Redis 将内存数据库快照保存在名字为 dump.rdb 的二进制文件中。
你可以对 Redis 进行设置, 让它在“ N 秒内数据集至少有 M 个改动”这一条件被满足时, 自动保存一次数据集。
比如说, 以下设置会让 Redis 在满足“ 60 秒内有至少有 1000 个键被改动”这一条件时, 自动保存一次数据集:

2.AOF(append-only file)
快照功能并不是非常耐久(durable): 如果 Redis 因为某些原因而造成故障停机, 那么服务器将丢失最近写入、且仍未保存到快照中的那些数据。从 1.1 版本开始, Redis 增加了一种完全耐久的持久化方式: AOF 持久化,将修改的每一条指令记录进文件


| No | 从不 fsync :将数据交给操作系统来处理。更快,也更不安全的选择。 |
| always | 每次有新命令追加到 AOF 文件时就执行一次 fsync :非常慢,也非常安全 |
| everysec | 每秒 fsync 一次:足够快(和使用 RDB 持久化差不多),并且在故障时只会丢失 1 秒钟的数据。 |
3.RDB 和 AOF ,我应该用哪一个?
如果你非常关心你的数据, 但仍然可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久化。
有很多用户都只使用 AOF 持久化, 但我们并不推荐这种方式: 因为定时生成 RDB 快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快。
4.Redis 4.0 混合持久化
重启 Redis 时,我们很少使用 rdb 来恢复内存状态,因为会丢失大量数据。我们通常使用 AOF 日志重放,但是重放 AOF 日志性能相对 rdb 来说要慢很多,这样在 Redis 实例很大的情况下,启动需要花费很长的时间。 Redis 4.0 为了解决这个问题,带来了一个新的持久化选项——混合持久化。AOF在重写(aof文件里可能有太多没用指令,所以aof会定期根据内存的最新数据生成aof文件)时将重写这一刻之前的内存rdb快照文件的内容和增量的 AOF修改内存数据的命令日志文件存在一起,都写入新的aof文件,新的文件一开始不叫appendonly.aof,等到重写完新的AOF文件才会进行改名,原子的覆盖原有的AOF文件,完成新旧两个AOF文件的替换;
AOF根据配置规则在后台自动重写,也可以人为执行命令bgrewriteaof重写AOF。 于是在 Redis 重启的时候,可以先加载 rdb 的内容,然后再重放增量 AOF 日志就可以完全替代之前的 AOF 全量文件重放,重启效率因此大幅得到提升。

5.缓存淘汰策略
当 Redis 内存超出物理内存限制时,内存的数据会开始和磁盘产生频繁的交换 (swap)。交换会让 Redis 的性能急剧下降,对于访问量比较频繁的 Redis 来说,这样龟速的存取效率基本上等于不可用。
在生产环境中我们是不允许 Redis 出现交换行为的,为了限制最大使用内存,Redis 提供了配置参数 maxmemory 来限制内存超出期望大小。

当实际内存超出 maxmemory 时,Redis 提供了几种可选策略 (maxmemory-policy) 来让用户自己决定该如何腾出新的空间以继续提供读写服务。
缓存淘汰策略:

解释:

noeviction 不会继续服务写请求 (DEL 请求可以继续服务),读请求可以继续进行。这样可以保证不会丢失数据,但是会让线上的业务不能持续进行。这是默认的淘汰策略。
volatile-lru 尝试淘汰设置了过期时间的 key,最少使用的 key 优先被淘汰。没有设置过期时间的 key 不会被淘汰,这样可以保证需要持久化的数据不会突然丢失。
volatile-ttl 跟上面一样,除了淘汰的策略不是 LRU,而是 key 的剩余寿命 ttl 的值,ttl 越小越优先被淘汰。
volatile-random 跟上面一样,不过淘汰的 key 是过期 key 集合中随机的 key。
allkeys-lru 区别于 volatile-lru,这个策略要淘汰的 key 对象是全体的 key 集合,而不只是过期的 key 集合。这意味着没有设置过期时间的 key 也会被淘汰。
allkeys-random 跟上面一样,不过淘汰的策略是随机的 key。volatile-xxx 策略只会针对带过期时间的 key 进行淘汰,allkeys-xxx 策略会对所有的 key 进行淘汰。如果你只是拿 Redis 做缓存,那应该使用 allkeys-xxx,客户端写缓存时不必携带过期时间。如果你还想同时使用 Redis 的持久化功能,那就使用 volatile-xxx 策略,这样可以保留没有设置过期时间的 key,它们是永久的 key 不会被 LRU 算法淘汰。
二.集群增减节点
1.在原集群中增加两个节点,8007(主) 8008(从)
2.在/usr/local/rediscluster/ 新建两个文件夹 8007 8008
![]()
3.cp /usr/local/redis-5.0.2/src/redis.conf /usr/local/rediscluster/8007 8008文件夹中
4.修改配置文件 具体修改东西在我上一篇文章中 https://blog.csdn.net/qq_36260963/article/details/84919796
5.文件修改后启动redis 
6.查看redis集群帮助

7.配置8007位集群主节点
使用add-node命令新增一个主节点8007(master),绿色为新增节点,红色为已知存在节点,看到日志最后有"[OK] New node added correctly"提示代表新节点加入成功
/usr/local/redis-5.0.2/src/redis-cli -a liuqiang --cluster add-node 172.30.50.214:8007 172.30.50.211:8001

8.查看集群状态

注意:当添加节点成功以后,新增的节点不会有任何数据,因为它还没有分配任何的slot(hash槽),我们需要为新节点手工分配hash槽
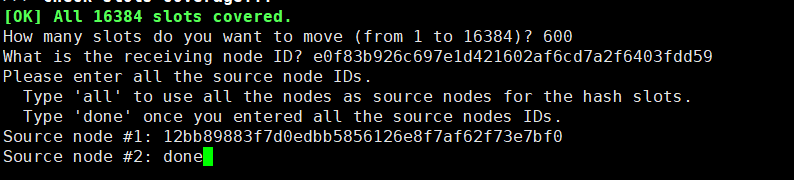
9.使用redis-cli命令为8007分配hash槽,找到集群中的任意一个主节点(红色位置表示集群中的任意一个主节点),对其进行重新分片工作。/usr/local/redis-5.0.2/src/redis-cli --cluster reshard 172.30.50.211:8001

How many slots do you want to move (from 1 to 16384)? 600
(ps:需要多少个槽移动到新的节点上,自己设置,比如600个hash槽)
What is the receiving node ID?
(ps:把这600个hash槽移动到哪个节点上去,需要指定节点id)
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
(ps:输入all为从所有主节点(8001,8002,8003)中分别抽取相应的槽数指定到新节点中,抽取的总槽数为600个)
Do you want to proceed with the proposed reshard plan (yes/no)? yes
10.查看最新集群状态 
可以看出分别从三台机器上平均取了200个槽位到214的机器了,并且是主节点。
11.配置从节点,配置8008为8007的从节点
/usr/local/redis-5.0.2/src/redis-cli -a liuqiang --cluster add-node 172.30.50.214:8008 172.30.50.211:8001

12.查看节点 
如图所示,还是一个master节点,没有被分配任何的hash槽。
13.将8008变为8007的从节点
我们需要执行replicate命令来指定当前节点(从节点)的主节点id为哪个,首先需要连接新加的8008节点的客户端,然后使用集群命令进行操作,把当前的8008(slave)节点指定到一个主节点下(这里使用之前创建的8007主节点,红色表示节点id)
/usr/local/redis-5.0.2/src/redis-cli -c -h 172.30.50.214 -p 8008


14.查看集群状态

可以看到node.config文件同事也更新了
三.缩容 删除8007和8008的节点
1. 用del-node删除从节点8008,指定删除节点ip和端口,以及节点id

2.查看集群状态 (发现8008节点已经不存在了,并且该节点的redis服务也已被停止)

3.删除8007主节点:
注意:我们尝试删除之前加入的主节点8007,这个步骤相对比较麻烦一些,因为主节点的里面是有分配了hash槽的,所以我们这里必须先把8007里的hash槽放入到其他的可用主节点中去,然后再进行移除节点操作,不然会出现数据丢失问题(目前只能把master的数据迁移到一个节点上,暂时做不了平均分配功能)


至此,我们已经成功的把8007主节点的数据迁移到8001上去了,我们可以看一下现在的集群状态如下图,你会发现8007下面已经没有任何hash槽了,证明迁移成功!

4.开始删除主节点

5.查看集群状态

四.主从切换



停完后等待5秒开始查看 是不是 8003挂了后8005变为主节点了。

五.集群选举
当slave发现自己的master变为FAIL状态时,便尝试进行Failover,以期成为新的master。由于挂掉的master可能会有多个slave,从而存在多个slave竞争成为master节点的过程, 其过程如下:
2.将自己记录的集群currentEpoch加1,并广播FAILOVER_AUTH_REQUEST 信息
3.其他节点收到该信息,只有master响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个epoch只发送一次ack
4.尝试failover的slave收集FAILOVER_AUTH_ACK
从节点并不是在主节点一进入 FAIL 状态就马上尝试发起选举,而是有一定延迟,一定的延迟确保我们等待FAIL状态在集群中传播,slave如果立即尝试选举,其它masters或许尚未意识到FAIL状态,可能会拒绝投票
DELAY = 500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000ms
•SLAVE_RANK表示此slave已经从master复制数据的总量的rank。Rank越小代表已复制的数据越新。这种方式下,持有最新数据的slave将会首先发起选举(理论上)。
所以集群最少是三台机器以上才可搭建,选举 必须 >集群机器的一般才能选举。