范涛
发表于2017-04-05
quora duplicate questions:Semantic Question Matching with Deep Learning
本文参考了quora duplicate questions 技术文档:
Quora 提供了一个公开数据集(
https://data.quora.com/First-Quora-Dataset-Release-Question-Pairs
),用来检测两个候选问题是否重复。上面参考文献中,quora工程师也给了他们采用DNN模型的一些思路和效果。
重复问题检测是一个常见的文本挖掘任务,在很多实际问答社区如quora,stackflow应该都是必须的应用。重复问题检测可以方便进行问题的答案聚合,以及问题答案推荐,自动QA等。
其中文中提到的公开的quora数据格式如下:

这是典型"1 to 1"匹配问题。
自己根据文中思路,基于keras开源框架实现了整个“
重复问题检测”任务,代码放在github上。
备注:
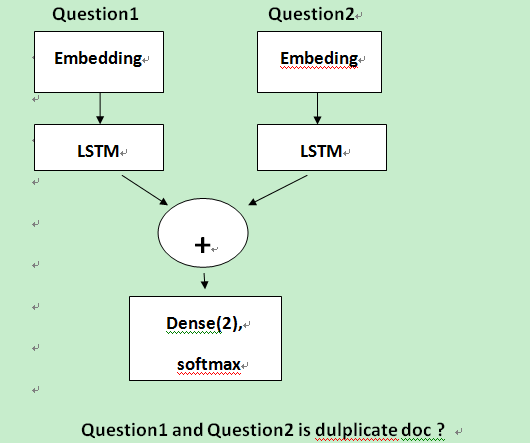
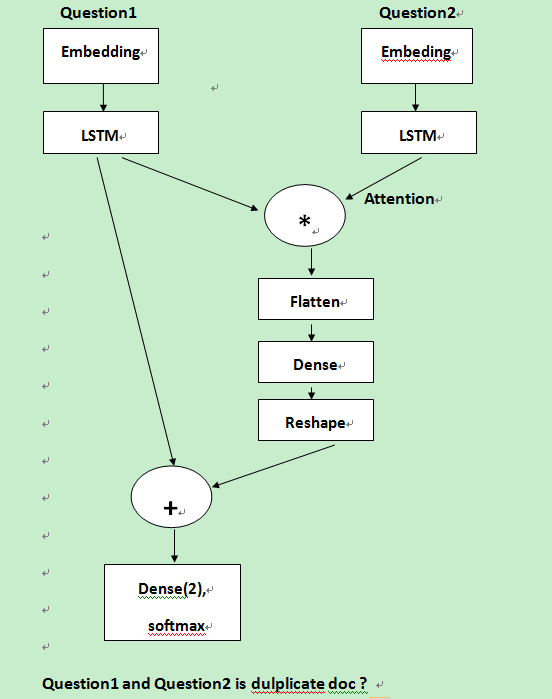
其中包含了LSTM模型,BILSTM模型, LSTM+Attention模型。
附录模型网络结构图如下:
LSTM 模型
LSTM+Attention 模型
其实值得说的是,真实场景中,如果我们需要进行问题重复检测,第一步其实先粗选找出重复问题的候选(candidate pairs),然后才是建立本文描述的“pair dnn 模型“。第一步粗选是十分重要的,需要考虑如何在海量样本中如何找出两两候选,这里不仅仅要考虑算法精度,还要考虑算法耗时和可扩展。这个问题不在本文讨论范畴,后面有机会专门讨论下这个问题。