原文(英文好的朋友直接看这个,我英语不咋样,翻译的很糟糕):https://medium.com/@AgenceSkoli/how-to-avoid-memory-overloads-using-scikit-learn-f5eb911ae66c
为什么会占用如此多的内存?
当我们使用countvectorizer对语料进行矢量化处理后,得到一个词汇表,这个词汇表由一个字典存储。词汇表中的术语可能是单个的字,也可能是词组。下图是使用
ngram(1,3)得到的数据样本量,这也是词汇表快速壮大的原因。
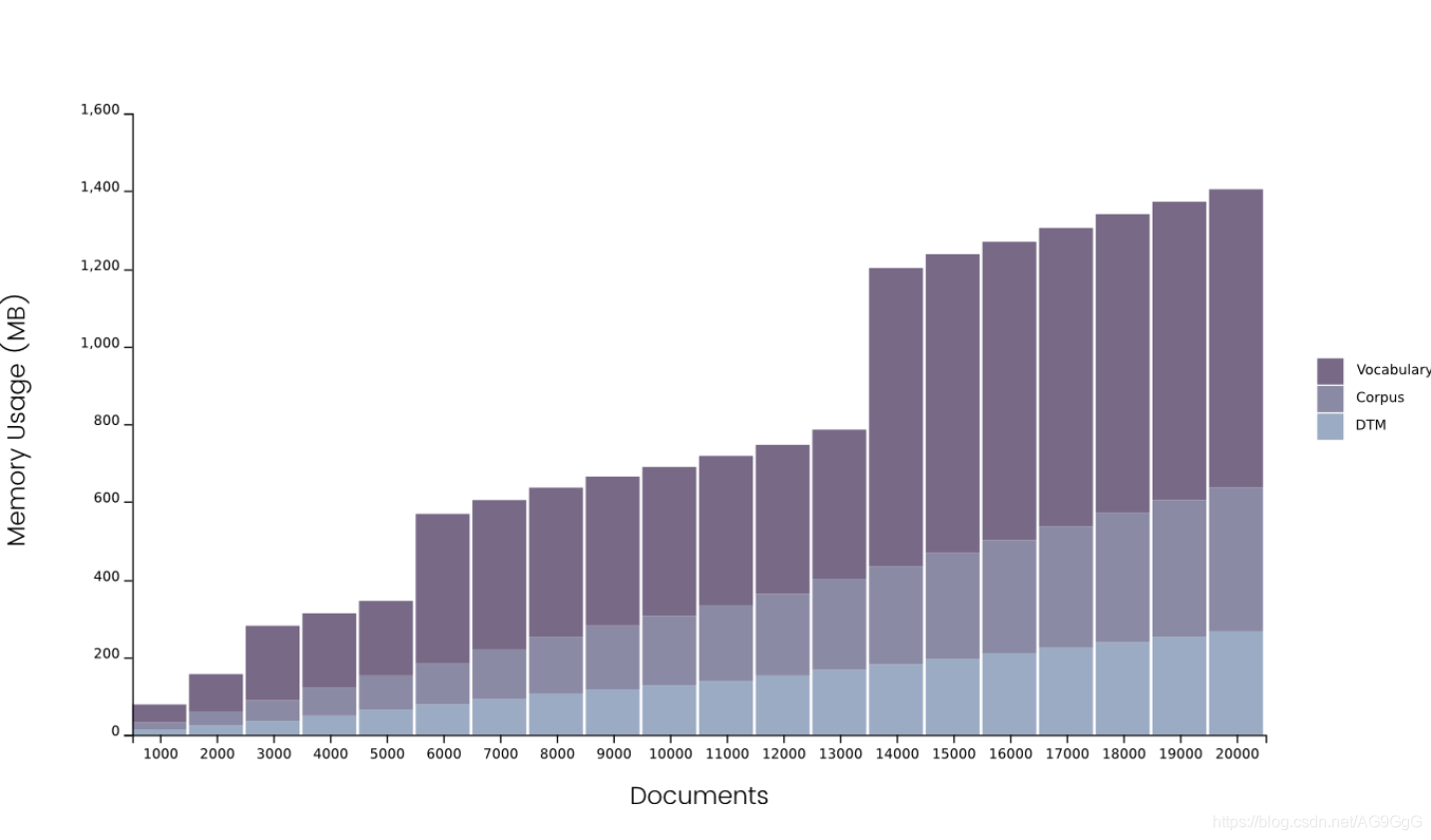
通过这个图表,不难发现,内存问题主要来源于分词后得到的词汇表。当语料库的文档超过14000时,词汇表需要750M的内存来存储,其中语料本身(数据类型为pandas DataFrame)占用了250M,文档-词矩阵(DTM,document-term matrices)大概占用180M。这也展现了python处理字典存储的方式:首先分配一定内存,当内存被全部使用后再分配等量的内存,由此类推。图中我们可以看到文件数量在13000和14000之间有一个巨大的内存差正是这个原因。
于是,当文件的数量增加,countvectorizer不再能够计算DTM,于是只能跑出MemoryError的异常。
如何解决内存溢出的问题?
首先,如果不是必须使用countvectorizer,可以考虑不使用,使用hashingvectorizer作为替代。但是hashingvectorizer将不再允许我们查找具体的词汇(哈希函数无法逆操作)。
如果我们希望获得词汇表中的词,那么我们不得不使用countvectorizer,于是我们希望将这个计算成本高昂的操作分为几个小的操作进行,然后再通过一系列的操作构建DTM。
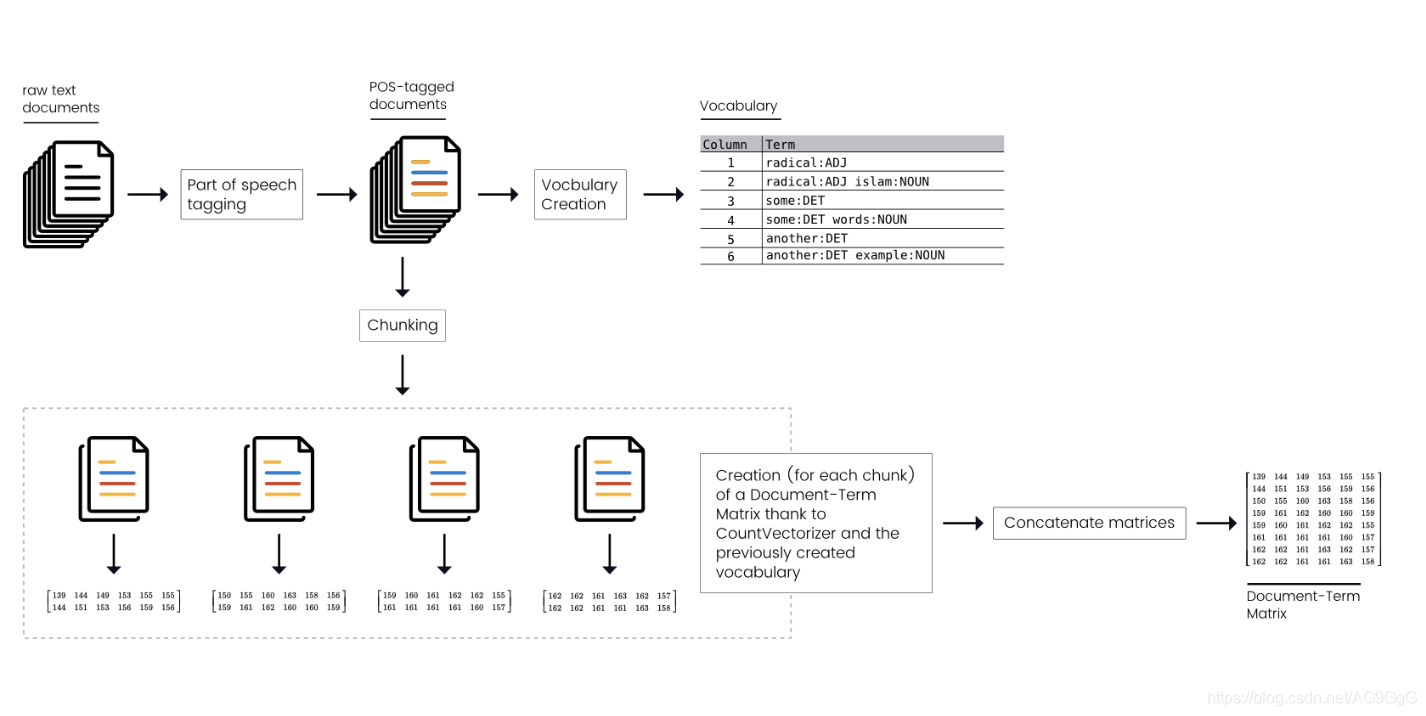
1. 将DTM的创建过程拆分为几个小的部分
这个操作听起来很简单,似乎我们只需要拆分我们的文本数据为几个小的批量(batches/chunks),然后分别对他们使用countvectorizer创建小的DTM,最后将各个小DTM组成最终DTM。但事实上并不是这样,我们会得到一个不完整的矩阵,因为每个小的DTM的列值各代表不同的词汇,但实际上所有的词汇取决于文章本身。
不同的文本分组将得到不同的词汇表,这导致我们不能通过简单拼接矩阵得到全部的词汇表。因此,为了将DTM的建立分成几个小的部分,我们应该:
- 创建一个全局词汇表
- 将语料分成几个部分(块)
- 为每一个语料块建立与全局词汇表相关联的DTM
- 合成各个子DTM
优点
这个方法拥有它的优越性。首先,如果我们在处理语料库时出错了(因为各种个样的原因导致的错误),我们可以返回出错的点重新计算(只要我们有在计算过程中存储部分计算成果的习惯)。这将为我们节省很多不必要的重复工作的时间且有助于我们在工程过程中保持思路清晰。
其次,这个方法可以并行/分布式进行,因为我们是基于共享的词汇表,独立地处理各个小的语料块,这些独立的矩阵各自运行不会对程序产生影响。
最后,这种计算方法通过避免超出首次分配内存后再次分配等量内存而占用过多内存的情况,把计算DTM的内存消耗降低,从而减少了出现Memory Error的概率。
改进
我们(作者们)并没有花太多的时间在这个问题上,但是我们可以对改进的方向、方法展开设想。
如同前文所提到的,内存不足的最大问题是由我们的词汇表产生的,但是我们的方法并没有减少词汇表占用的空间。当语料库越来越大,问题将变得越来越严重。所以我们可以考虑不同的方法来减少训练过程中的内存使用。
-
减少语料库的规模
例如,我们可以删去语料库中出现一次或者非常多次(类似tool words, stop words)的词,但是这并不足以显著改善语料库的存储规模。 -
将词汇表存储在数据库中,通过RAM进行读取
这将会对性能有一个显著的改善。将语料库存储在数据库中,能够节省很多的存储空间,也就意味着其他的分析环节能够获得更多的存储资源。我们并不追求最完美的数据库来完成这项存储任务,能够使用PostgreSQL实现这个任务就足够。 -
使用不同的数据结构
python中的字典数据结构占用了许多的内存空间。寻找一个类似的数据集中型的数据结构,目前看好的数据结构是Trie(marisa-trie)
后续查阅资料发现了代码实现的案例:scikit-learn out-of-core classification