学生身高体重统计分析案例
需求1:
获取所有男生的身高, 求平均值;获取所有女生的身高, 求平均值;并绘制柱状图显示
import numpy as np
from pyecharts import Bar
fname = "doc/eg6-a-student-data.txt"
dtype = np.dtype([('gender', '|S1'), ('height', 'f2')])
data = np.loadtxt(fname=fname, dtype=dtype, skiprows=9,
usecols=(1, 3))
# print(data)
# print(data['gender'])
# print(data['height'])
# print(data['height'][data['gender'] == b'M'].mean())
# print(data['height'][data['gender'] == b'F'].mean())
#
# 判断是否性别为男的表达式
isMale = data['gender'] == b'M'
male_avg_height = data['height'][isMale].mean()
female_avg_height = data['height'][~isMale].mean()
print(male_avg_height, female_avg_height)
bar = Bar(title="不同性别身高的平均值")
bar.add("", ["男", '女'], [male_avg_height, female_avg_height])
bar.render()
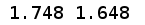

需求2:
获取所有男生的体重, 求平均值;获取所有女生的体重, 求平均值;并绘制柱状图显示
def parser_weight(weight):
# 对于体重数据的处理, 如果不能转换为浮点数据类型, 则返回缺失值;
try:
return float(weight)
except ValueError as e:
return -99
fname = "doc/eg6-a-student-data.txt"
dtype = np.dtype([('gender', '|S1'), ('height', 'f2'), ('weight', 'f2')])
data = np.loadtxt(fname=fname, dtype=dtype, skiprows=9,
usecols=(1, 3, 4), converters={4:parser_weight})
# 判断是否性别为男的平均身高
isMale = data['gender'] == b'M'
male_avg_height = data['height'][isMale].mean()
female_avg_height = data['height'][~isMale].mean()
print(male_avg_height, female_avg_height)
# 判断是否性别为男的平均体重
is_weight_vaild = data['weight'] > 0
male_avg_weight = data['weight'][isMale & is_weight_vaild].mean()
female_avg_weight = data['weight'][~isMale & is_weight_vaild].mean()
print(male_avg_weight, female_avg_weight)
bar = Bar(title="不同性别身高的平均值")
bar.add("身高", ["男", '女'], [male_avg_height, female_avg_height])
bar.add("体重", ["男", '女'], [male_avg_weight, female_avg_weight])
bar.render()
import numpy as np
from pyecharts import Bar
#
# def parser_bps(bps):
# # 对于体重数据的处理, 如果不能转换为浮点数据类型, 则返回缺失值;
# try:
#
# bps = bps.decode('utf-8').split('/')
# print(bps, type(bps))
# first_bps = float(bps[0])
# second_bps = float(bps[1])
# return first_bps, second_bps
# except ValueError as e:
# return -99
def parser_bpd(bpd):
# 对于体重数据的处理, 如果不能转换为浮点数据类型, 则返回缺失值;
try:
return float(bpd)
except ValueError as e:
return -99
fname = "doc/eg6-a-student-data.txt"
dtype = np.dtype([('gender', '|S1'), ('bpd', 'f2')])
data = np.loadtxt(fname=fname, dtype=dtype, skiprows=9,
usecols=(1, 6), converters={ 6:parser_bpd})
print(data)


基于numpy的股价统计分析应用
题目要求:
-
- 数据格式介绍:
第4-8列,分别为股票的开盘价,最高价,最低价,收盘价,成交量。
- 数据格式介绍:
-
- 计算成交量加权平均价格
概念:成交量加权平均价格,英文名VWAP(Volume-Weighted Average Price,
成交量加权平均价格)是一个非常重要的经济学量,代表着金融资产的“平均”价格。
某个价格的成交量越大,该价格所占的权重就越大。VWAP就是以成交量为权重计算出来的加权平均值。np.average(endprice, weights=“成交量”)
- 计算成交量加权平均价格
-
- 计算股票收益率、年波动率及月波动率
在投资学中,波动率是对价格变动的一种度量,历史波动率可以根据历史价格数据计算得出。
计算历史波动率时,需要用到对数收益率。
对数收益率???
年波动率等于对数收益率的标准差除以其均值,再乘以交易日的平方根,通常交易日取252天。
月波动率等于对数收益率的标准差除以其均值,再乘以交易月的平方根。通常交易月取12月。
- 计算股票收益率、年波动率及月波动率
import numpy as np
import math
params1 = dict(
fname= "doc/data.csv",
delimiter=',', #内容以‘,’进行分隔
usecols = (6,7), #读取第几列
unpack = True #对提取的内容进行转置
)
# **从字典中解包
print(np.loadtxt(**params1)) #读取的内容以近似字典的形式
endPrice,countNumber = np.loadtxt(**params1)
WAP = np.average(endPrice,weights = countNumber)
print("1.计算成交量加权平均价格:",WAP)
print("***********************************")
params2 = dict(
fname= "doc/data.csv",
delimiter=',',
usecols = (4,5),
unpack = True
)
highPrice,lowPrice = np.loadtxt(**params2)
print("2.最高价的最大值:",highPrice.max())
print("2.最低价的最小值:",lowPrice.min())
print("***********************************")
# 近期最高最低价格的极差
print("3.近期最高价格的极差",np.ptp(highPrice))
print("3.近期最低价格的极差",np.ptp(lowPrice))
# 4.计算收盘价的中位数
print("4.计算收盘价的中位数:",np.median(countNumber))
# 5.计算收盘价格的方差
print("5.计算收盘价格的方差:",np.var(countNumber))
# 7.星期?的平均收盘价格
def get_week(date):
from datetime import datetime
date = date.decode('utf-8')
return datetime.strptime(date,"%d-%m-%Y").weekday()
params3 = dict(
fname= "doc/data.csv",
delimiter=',',
usecols = (1,6),
converters= {1:get_week},
unpack = True
)
week,endPrice=np.loadtxt(**params3)
allAvg=[]
for weekday in range(5):
average = endPrice[week==weekday].mean()
allAvg.append(average)
print("7.星期%s的平均收盘价格:%s"%(weekday+1,average))
# 8.平均收盘价的最低是星期
print("8.平均收盘价的最低是星期:",np.argmin(allAvg)+1)
print("8.平均收盘价的最高是星期:",np.argmax(allAvg)+1)
# 6.计算简单收益率,对数收益率,年波动率,月波动率
simpleReturn = np.diff(endPrice)
print("计算简单收益率:",simpleReturn)
logReturn = np.diff(np.log(endPrice))
print("计算对数收益率:",logReturn)
annual_vol = logReturn.std()/logReturn.mean()*np.sqrt(252)
print("年波动率:",annual_vol)
month_vol = logReturn.std()/logReturn.mean()*np.sqrt(12)
print("月波动率:",month_vol)
