一、修改pascalvoc_2007.py
生成自己的tfrecord文件后,修改训练数据shape——打开datasets文件夹中的pascalvoc_2007.py文件,
根据自己训练数据修改:NUM_CLASSES = 类别数(不包含背景);
# TRAIN_STATISTICS = { # 'none': (0, 0), # 'aeroplane': (238, 306), # 'bicycle': (243, 353), # 'bird': (330, 486), # 'boat': (181, 290), # 'bottle': (244, 505), # 'bus': (186, 229), # 'car': (713, 1250), # 'cat': (337, 376), # 'chair': (445, 798), # 'cow': (141, 259), # 'diningtable': (200, 215), # 'dog': (421, 510), # 'horse': (287, 362), # 'motorbike': (245, 339), # 'person': (2008, 4690), # 'pottedplant': (245, 514), # 'sheep': (96, 257), # 'sofa': (229, 248), # 'train': (261, 297), # 'tvmonitor': (256, 324), # 'total': (5011, 12608), # } # TEST_STATISTICS = { # 'none': (0, 0), # 'aeroplane': (1, 1), # 'bicycle': (1, 1), # 'bird': (1, 1), # 'boat': (1, 1), # 'bottle': (1, 1), # 'bus': (1, 1), # 'car': (1, 1), # 'cat': (1, 1), # 'chair': (1, 1), # 'cow': (1, 1), # 'diningtable': (1, 1), # 'dog': (1, 1), # 'horse': (1, 1), # 'motorbike': (1, 1), # 'person': (1, 1), # 'pottedplant': (1, 1), # 'sheep': (1, 1), # 'sofa': (1, 1), # 'train': (1, 1), # 'tvmonitor': (1, 1), # 'total': (20, 20), # } # SPLITS_TO_SIZES = { # 'train': 5011, # 'test': 4952, # } # SPLITS_TO_STATISTICS = { # 'train': TRAIN_STATISTICS, # 'test': TEST_STATISTICS, # } # NUM_CLASSES = 20 TRAIN_STATISTICS = { 'none': (0, 0), 'flower': (35,35), 'total': (35, 35), } TEST_STATISTICS = { 'none': (0, 0), 'flower': (15,15) } SPLITS_TO_SIZES = { 'train': 35, 'test': 15 } SPLITS_TO_STATISTICS = { 'train': TRAIN_STATISTICS, 'test': TEST_STATISTICS, } NUM_CLASSES = 1 #类别,不包含背景
二、修改ssd_vgg_300.py
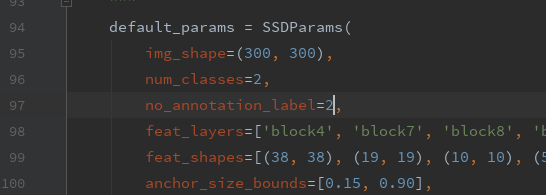
根据自己训练类别数修改96 和97行:等于类别数+1
三、修改eval_ssd_network.py
修改类别数和batchsize

四、修改train_ssd_network.py
数据格式改为 NHWC:

numclasses改为类别数加1:

batch_size该为自己设置的:

修改训练步数(None代表无限训练下去):

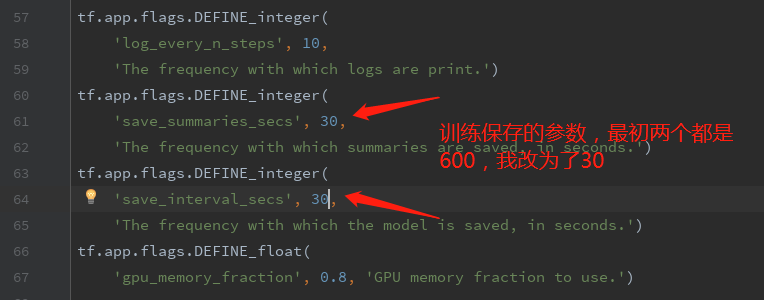
可以更改模型保存的参数:
五:加载VGG_16,重新训练模型
将VGG_16放在checkpoint文件夹下面:
