版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_28766327/article/details/79106253
【补充一下】经过 KimZing 同学提醒,mysql5.7不会默认给一个id,但我们可以在查询条件种加上 min(id)
今天遇到一个问题。相同的数据在同一张表里出现了多次。我的需求是删除多余的数据,但要保留其中一条。
定义 表名 table_a ,判断唯一的两个字段 c_1,c_2,无关字段data
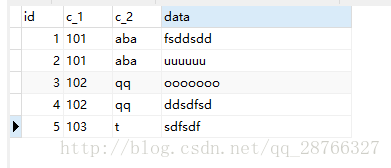
表中原始数据如下
首先我们要查看数据库中那些数据重复了,执行如下SQL
SELECT * FROM
(SELECT COUNT(*) as num,c_1,c_2,min(id) as id FROM table_a GROUP BY c_1,c_2)e
WHERE e.num>1;
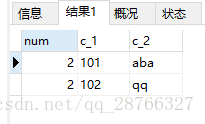
结果如下
其中num字段为 数据出现的次数,可以发现我们已经找出了出现重复的数据,那么我们该怎么去除其中多余的数据呢。
我的思路是:再查询一个id 字段 ,我们group by 的时候 id 字段只能查询到重复数据中的一条。然后我们把这些id的数据删除,就达到了去重的效果。SQL 如下
DELETE FROM table_a
WHERE id IN
(SELECT e.id FROM (SELECT COUNT(*) as num,c_1,c_2,min(id) as id FROM table_a GROUP BY c_1,c_2)e WHERE e.num>1);
2018-01-20 更新:
突然想到一个更好的方法,SQL如下:
DELETE FROM table_a
WHERE id IN
(SELECT id FROM (SELECT id FROM table_a GROUP BY c_1,c_2 HAVING count(*) > 1)e);
执行:
可以看到有两行被删除了。这时再看看数据表,数据已经变成了:

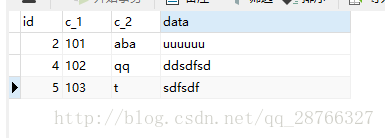
成功将重复的数据删除。
如果重复数据是三条或者更多怎么办呢?很简单,再多执行几次这个SQL 就好了。
最后,别忘了给字段加个唯一索引,避免数据再出问题