1.选一个自己感兴趣的主题或网站。(所有同学不能雷同)
主题:“互联网+”时代共享经济在我国的兴起及其发展趋势
网站:http://theory.people.com.cn/n1/2016/0511/c40531-28341574.html
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
import urllib.request as ur from urllib.request import Request from bs4 import BeautifulSoup as bs from urllib import parse import os import re def gethtml(url): header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'} req = Request(url, headers=header) html = ur.urlopen(req).read().decode('GB2312') return html def getinfo(html): soup = bs(html,'html.parser') info = soup.select('div[class="text_c clearfix"]') return info if __name__=="__main__": url = "http://theory.people.com.cn/n1/2016/0511/c40531-28341574.html" html1 = gethtml(url) info = getinfo(html1) for i in info: f = open('info2.txt', 'a+', encoding='utf-8') f.write(re.sub('\s+', '', i.get_text())) f.close()
3.对爬了的数据进行文本分析,生成词云。
4.对文本分析结果进行解释说明。
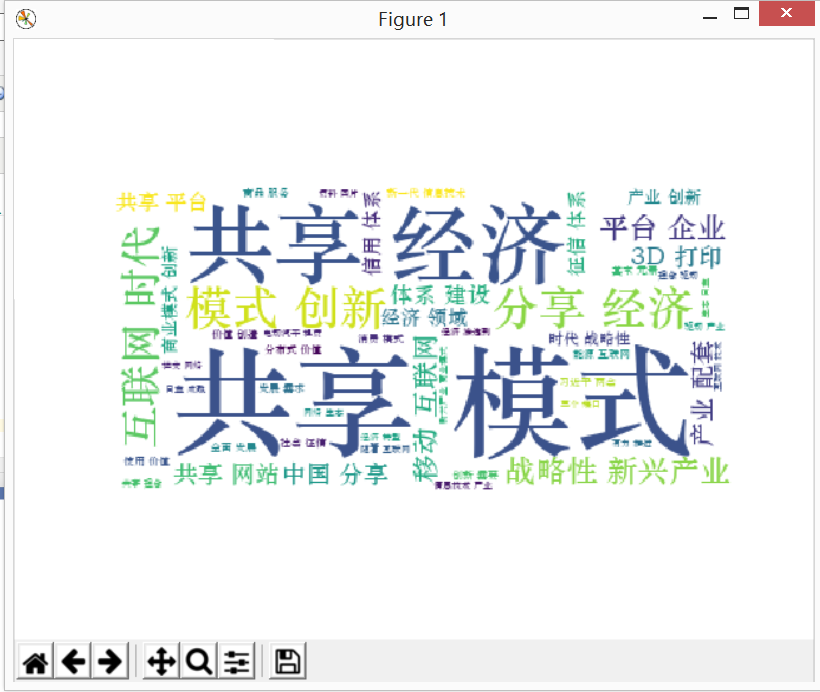
5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
实现过程:从构思→回顾→取材→设计→编译→卡断→解决→实现→总结
遇到的困难:(1)对以前的爬虫基础只是课堂及课后作业的操作,没有进一步的去掌握,导致操作编译的模块比较生疏,工作效率大大降低;
(2)运行时有时卡断,终止,原因是没有设置运行路径;
(3)生成词云的最终结果图形,不会改变。
解决办法:(1)回顾学过的操作,把需要的模块结合起来,多加尝试;
(2)通过同学的协助,掌握配置路径的操作;
(3)通过网络查询,及请教同学,来更改。
思想:可以爬虫技术获取目标用户想要的特定数据,方便快捷且高效
结论:不学不做肯定不会,多学勤做不会都难。
6.最后提交爬取的全部数据、爬虫及数据分析源代码。

import jieba import PIL from wordcloud import WordCloud import matplotlib.pyplot as p import os path = "C:\\Users\\guoyaowen\\Desktop" info = open(path+'\\info2.txt','r',encoding='utf-8').read() text = '' text += ' '.join(jieba.lcut(info)) wc = WordCloud(font_path='C:\Windows\Fonts\STZHONGS.TTF',background_color='White',max_words=50) wc.generate_from_text(text) p.imshow(wc) # p.imshow(wc.recolor(color_func=00ff00)) p.axis("off") p.show() wc.to_file('ljs.jpg')