自己做量化交易软件(15)通通量化AI框架的选股器设计
前面我们学会了单只股票的分析,回测功能。下面我们开始设计选股器和量化分析的功能。
在设计选股器之前,我们先要学习一些python基本操作技巧。
一、股票代码处理技巧
1、数字类型转换
我们获取的数据格式都不相同,特别是股票代码,有些是数字1,有些是字符1,有些股票代码带后缀,例如’60000.SH’,‘000001.SZ’,‘000001.XSHE’,'000300.XSHG’等等。无论什么方式,我们都做一些简单的转化为通通标准股票代码格式。
深圳股票代码: ‘000001.SZ’
上海股票代码: ‘600000.SH’
指数代码:‘000300.ZS’
各种数据转化函数命令如下:
#数字int转换为字串str
s_code=str(n_code)
#字串str转换为数字int
n_code=int(s_code)
代码演示:
n_code=10
#数字int转换为字串str
s_code=str(n_code)
print(s_code,type(s_code))
#字串str转换为数字int
n_code=int(s_code)
print(n_code,type(n_code))
输出结果:
10 <class ‘str’>
10 <class ‘int’>
2、字符串处理
我们看到字串’10’ ,不够长度6,需要在前面补’0’。
字串数值前面补0,用函数zfill(),看下面演示代码和结果:
s_code='10'
#字串数字前补够0
s_code= s_code.zfill(6)
输出结果:
000010 <class ‘str’>
3、补上股票后缀
看下面股票代码演示:
#通通股票代码转换
def ttsn(s):
s=s.strip()
if (len(s)<6 and len(s)>0):
s=s.zfill(6)+'.SZ'
if len(s)==6:
if s[0:1]=='0':
s=s+'.SZ'
else:
s=s+'.SH'
return s
#聚宽股票代码转换
def jqsn(s):
s=s.strip()
if (len(s)<6 and len(s)>0):
s=s.zfill(6)+'.XSHE'
if len(s)==6:
if s[0:1]=='0':
s=s+'.XSHE'
else:
s=s+'.XSHG'
return s
二、股票数据中的股票代码处理技巧
pandas是基于numpy构建的,为时间序列分析提供了很好的支持。pandas中有两个主要的数据结构,一个是Series,另一个是DataFrame。
Series 类似于一维数组与字典(map)数据结构的结合。它由一组数据和一组与数据相对应的数据标签(索引index)组成。这组数据和索引标签的基础都是一个一维ndarray数组。可将index索引理解为行索引。 Series的表现形式为:索引在左,数据在右。
DataFrame是一个类似表格的数据结构,索引包括列索引和行索引,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame的每一行和每一列都是一个Series,这个Series的name属性为当前的行索引名/列索引名。
股票数据一般用pandas包的 DataFrame 来存放。
上述的方法无法对 DataFrame整列数据处理。用循环操作又充分发挥了Python的速度慢的弱点,因此可以用一些Python的技巧来提高速度。
DataFrame序列中的股票格式转换可以用类似下面的命令来瞬间完成。
#短字串补全快速运算
base.code=['0'*(6-len(x)) + x for x in base.code.astype(str)]
三、股票代码的运算
我们通过若干算法,例如财务数据或者技术指标等策略, 筛选了一批数据。怎样通过这些数据建立我们的目标备选股票池。并且完成股票池之间的逻辑运算。
例如 股票池的合并、黑名单的过滤等等运算。我们可以充分利用Python的特征和优势,来快速完成股票池运算。
我们可以充分利用这些不同数据特性,快速完成所需工作。
1、pandas和numpy数据相互转换
下面给出DataFrame中的股票代码转列表例子,重点要看说明和记住例子,演示代码如下:
import pandas as pd
import numpy as np
import HP_data as hp
#获取业绩报告数据
'''
report_data返回数据格式 如下:
code,代码
name,名称
esp,每股收益
eps_yoy,每股收益同比(%)
bvps,每股净资产
roe,净资产收益率(%)
epcf,每股现金流量(元)
net_profits,净利润(万元)
profits_yoy,净利润同比(%)
distrib,分配方案
report_date,发布日期
'''
#获取获取2015年第4季度的业绩报告数据
t2015=hp.get_report_data(2015,4)
#选取eps_yoy,每股收益同比(%)的排名前20位股票数据。
top20=t2015.sort_values(by='eps_yoy',ascending=False).head(20)
#获取股票代码的Series序列,带原始数据索引
S_code=top20.code
#dataframe重建索引,从0开始顺序
S_code2 = S_code.reset_index(drop=True)
#将股票代码Series序列转为列表list数据
l_code=S_code.tolist()
#将列表list转为array序列数据,与Series序列区别是无索引。
a_code=np.array( l_code)
#将array序列数据转为 Series序列,增加了从0开始顺序自然索引。
S_code3= pd.Series(a_code, name = 'code')
#部分数据内容输出结果
print('\n----S_code-----获取股票代码的Series序列,带原始数据索引')
print(S_code)
print('\n----S_code2-----重建索引,从0开始顺序')
print(S_code2)
print('\n----l_code-----将股票代码Series序列转为列表list数据')
print(l_code)
print('\n----a_code-----将列表list转为array序列数据,与Series序列区别是无索引。')
print(a_code)
print('\n----S_code3-----将array序列数据转为 Series序列,增加了从0开始顺序自然索引。')
print(S_code3)
程序运行结果如下图:

2、列表(list)和集合(set)相互转换
Python数据格式有列表(list)和集合(set)。
列表有重复数据,并且 有序。
集合无重复数据,并且无序。
我们可以利用集合(set)的无重复特性,将股票代码转化为集合(set),能够快速完成股票代码去掉重复,股票代码池的合并,剔除股票黑名单等运算。
(1) 列表运算
#假定我们通过策略1筛选出股票池列表bk1
bk1=['600000', '600001', '600002', '600003', '600004', '000001', '000010']
#我们通过策略2筛选出股票池列表bk2,我们可以看到前面3个数据重复。
bk2=['600000', '600001', '600002','600981', '600080', '600191']
#给bk1查入数据数据,list.insert(i, 数据)
bk1=bk1.insert(1, '300751') #在指定位置插入元素
#给bk2增加数据
bk2=bk2.append('600390')
#删除bk2最后一个数据
bk2=bk2.pop() #将最后一位的元素删除
#删除bk1中间第3个数据。
bk1=bk1.pop(3) #删除指定位置的元素
(2) 集合运算
python的set和其他语言类似, 是一个无序不重复元素集, 基本功能包括关系测试和消除重复元素. 集合对象还支持union(联合), intersection(交), difference(差)和sysmmetric difference(对称差集)等数学运算。
sets 支持 x in set, len(set),和 for x in set。作为一个无序的集合,sets不记录元素位置或者插入点。因此,sets不支持 indexing, slicing, 或其它类序列(sequence-like)的操作。
集合t,s支持一系列标准操作,包括并集、交集、差集和对称差集,例如:
a = t | s # t 和 s的并集
b = t & s # t 和 s的交集
c = t – s # 求差集(项在t中,但不在s中)
d = t ^ s # 对称差集(项在t或s中,但不会同时出现在二者中)
下面给出集合运算的演示。
#建立集合st1,st2
print('\n----st1----')
st1=set(['002027', '600061', '600080','600659'])
print(st1)
print('\n----st2----')
st2=set(['000001', '600061', '600088','000002'])
print(st2)
#集合中增加可以通过列表list增加,再转换为集合set。
#也可以通过集合并集运算来增加元素。
print('\n----st1---- st1中增加600090')
st1=st1.union(set(['600090']))
print(st1)
print('\n----a = st1 | st2-----')
#集合运算
a = st1 | st2 # st1 和 st2的并集
print(a)
print('\n----b = st1 & st2 -----')
b = st1 & st2 # st1和 st2的交集
print(b)
print('\n----c = st1 - st2 -----')
c = st1 - st2 # 求差集(项在st1中,但不在st2中)
print(c)
print('\n----d = st1 ^ st2-----')
d = st1 ^ st2 # 对称差集(项在st1或st2中,但不会同时出现在二者中)
print(d)
print('\n----st2 remove 600088-----')
#集合元素删除
st2=st2.difference(set(['600088']))
print(st2)
print(type(st1),type(st2))
程序运行结果如下图:

(3)列表和集合转换
我们根据算法需要,利用列表和集合的特性,来实现我们的要求
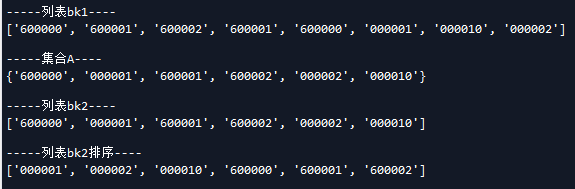
#假定我们通过策略1筛选出股票池列表bk1,但又股票重复
bk1=['600000', '600001', '600002', '600001', '600000', '000001', '000010','000002']
print('\n-----列表bk1----')
print(bk1)
print('\n-----集合A----')
#转换为集合A来去掉重复
A=set(bk1)
print(A)
print('\n-----列表bk2----')
#将结果转为列表bk2
bk2=list(A)
print(bk2)
print('\n-----列表bk2排序----')
#对bk2进行排序
bk3=bk2.sort()
print(bk2)
程序运行结果如下图:
今天我给大家介绍了关于股票代码和股票板块运算的基本知识。下次开始设计有关选股器画面的设计。