【依旧是考研er的分享~】双非的渣渣,虽然以前学过数据结构,但是学的都是皮毛,现在看王道的算法题实在太头疼了。只能好好花时间把二叉树的遍历弄熟悉。
正文:
首先我们来看看二叉树的遍历——递归算法。
递归是我非常头疼的东西,因为需要保持大脑高度清醒,我才不会乱...
其实二叉树的递归是比较好理解的,重点在于什么时候打印根节点!



观察这三个遍历的代码,你发现了什么?
答案就是——只改变了 printf(" %d " , BT -> Data) 的位置。
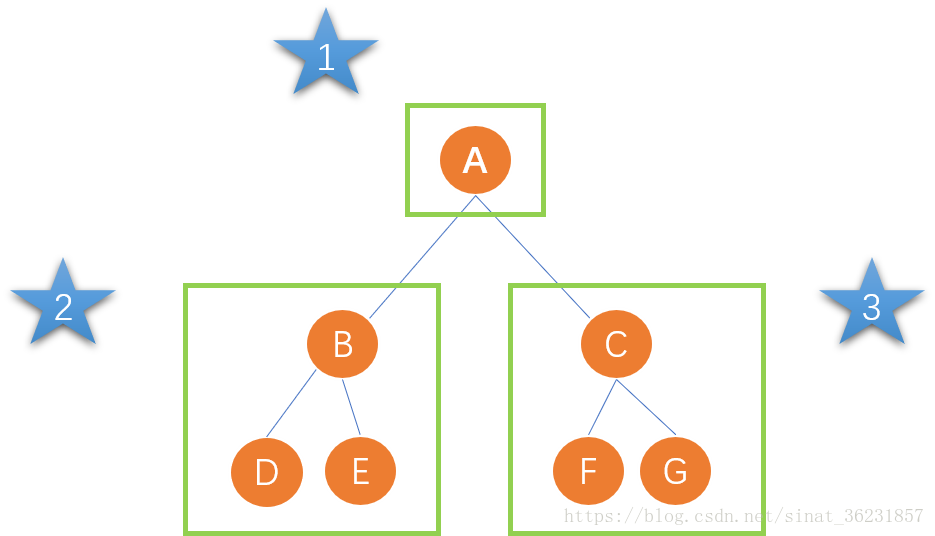
那么这一系列的递归原理是什么呢?看着我的第一张图,结合图理解!
比如说,先序遍历中,首先访问根结点,访问到了就立马打印出来,然后去遍历它的左子树,就是我第一张图的第二块,
相当于开启了一段新旅程,我们单独来看这个新旅程,又是先把B打印出来了,再去遍历B的左子树......以此类推。
再举个例子:中序遍历中,首先访问根结点的左子树,BDE这棵树,在这段旅程中,先访问B的左孩子D,访问完了,D是叶子结点,那么这段旅程的一半就是走完了,再退回去打印B,然后访问B的右子树......
后序遍历原理相同,大家可以自己推敲一下。
那么我们再来说说二叉树的遍历——非递归。
如果在二叉树之前有好好学堆栈的同学应该知道,栈的一个常见应用就是递归。
所以我们可以想到用堆栈的方法把递归遍历转换为非递归遍历。
那么应用堆栈去遍历的时候我们要注意什么呢?——什么时候Push!什么时候Pop!
嗯,可以想到,当你不需要立即打印这个元素的时候,就把它压栈。等需要它的时候再把它从栈里拿出来。
下面以中序遍历为例讲一下非递归。
看我的第一张图!如果要中序遍历那棵树,应该是怎样的?
首先碰到A,然后A邂逅了B,还不能停,B要去邂逅D,D发现没人了,就把自己弹出来了。
D弹出了之后,B的左边也没人了,所以B也弹出来了,再把B的右孩子E压栈......以此类推。
所以算法思想是这样的:
1、遇到一个结点,就把它压栈,并去遍历它的左子树。
2、当左子树遍历结束后,从栈顶弹出结点并访问它。
3、然后按其右指针再去中序遍历该结点的右子树。

这就是中序遍历的非递归遍历啦。我们不禁会疑问,先序的非递归遍历是怎样的呢?
你还记得递归遍历时有什么特点么。嗯!根节点的访问顺序不同。
所以不难想到,那句printf在中序遍历时,是第二次碰到A,即第一次碰到A的时候没管它,先去管它的左子树了,等左子树都管完了,就是第二次碰到A了,这个时候把它输出来。所以,先序遍历就是在中序遍历的基础上把printf那句调到Push前。
后序遍历就留给大家思考啦。难点在于,你怎么去写第三次碰到A呢?
提醒大家一下,GetTop(s,p)是获得栈顶元素,这可以当做第二次访问根节点,因为后序遍历的顺序是左右根,所以你不能把根立即弹出,得访问完右子树之后再弹出来。
1、对根节点,一直p = p -> lchild 压栈直到最左边的叶子结点
2、GetTop(s,p),检查结点有没有右孩子,没有的话就可以把这个结点弹出,有的话还得继续p = p -> rchild
3、再继续检查 rchild 的左孩子、右孩子
......
综上,希望我的总结有帮助到大家。我觉得这里好难啊,之前的学习中只是清楚基本的概念,对算法、代码完全没有研究,一点都不熟悉,所以这部分看得特别慢。特别揪心...唉...继续学习去了,如果有错误要和我说哦~~我个人是觉得这部分的学习只有把基础的遍历吃透,你有运用它的能力了,才能好好做相关的算法题,然后还要结合图去理解。
要耐心,我们菜鸟当然要有耐心啊。
笔芯 :)