一.推荐系统概述
随着信息技术和互联网的发展,人们逐渐从信息匮乏的时代走入了信息过载的时代。对于信息的消费者来说, 从大量信息中找到自己感兴趣的信息是一件很困难的事情;对于信息生产者来说,让自己的信息从大量的信息中脱颖而出也是一件很困难的事情。
解决这一问题,代表性的思路有如下三种:
1.搜索引擎,根据用户的关键词找到自己需要的信息,当然前提是用户明确知道自己的需求是什么。这一解决方案催生了科技领域很多著名的公司,比如谷歌,百度。
2.分类目录,意思是将著名的网站分门别类,从而方便用户根据类别来查找网站。国内著名的Hao123就是此类网站。但是当互联网规模的不断扩大,分类网站只能覆盖少量的热门网站,根本不能满足用户的需求。
3.推荐系统,前两种解决方案都是用户知道自己的需求是什么,至少是知道自己需要查找信息的类别。但是,当用户没有明确的需求的时候,前两种解决方案就无能为力了。而推荐系统,根据用户的历史行为给用户的兴趣建模,从而主动的给用户推荐明确的需求。
那么推荐系统是怎么工作的呢。
回顾下现实生活中,歌荒的时候,我们都是怎么做的呢?
一般情况下,都是先像朋友咨询,如果你有朋友的话。没有朋友,你也可以取微博或者朋友圈里面问一句,“最近有哪些好听的歌?”,然后等别人给你推荐。这种推荐方式叫做社会化推荐。
二般情况下,我们都有自己喜欢的明星,可以去找找他们早年间发表过的未听过的歌曲来听一听。这种方式其实是在找和自己之前听过的歌曲在旋律或者分割上相似的歌曲,这种推荐方式在推荐系统中叫做基于内容的推荐。
三般情况下呢,我们可能直接打开酷狗音乐,QQ音乐,网易云音乐等等,直接在排行榜上找找,看看比人都在听什么,然后找一个风评不错的歌听一下。如果能找到和自己兴趣相似的一些用户,那结果可能更和我们胃口了,这就是基于协同过滤的推荐。
推荐系统的本质,其实就是将用户和物品联系起来。
二.基于领域的算法 ==》协同过滤
协同过滤技术(collaborative filtering,简称CF)是基于用户对物品的历史偏好(比如点击,加入购物车,购买,评价等),发掘物品之间的相关性,或者是发掘用户间的相关性,根据这些相关性进行推荐。
协同过滤不需要抽取物品的任何特征,它能够适用于任何内容;(若是考虑物品的特征做推荐,就是基于内容的推荐,事实上,在生产环境中,推荐方式可以混合使用)
所推荐的物品,在内容上与之前喜欢的物品可能完全不相关,可以避免了推荐的物品种类的过于简单化。
协同过滤主要有两种:
基于用户的协同过滤 Uesr_CF
基于物品的协同过滤 Item_CF。
区别是:

基于用户的协同过滤:
1.分析各用户User对物品Item的评分(行为记录);
2.根据用户对物品的评分,计算所有用户和目标用户的相似度;
3.选出与当前用户最相似的N个用户;
4.将这N个用户评价最高并且当前用户又没有浏览过的item推荐给当前用户。
基于物品的协同过滤:
1、计算物品之间的相似度;
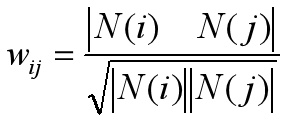
其中 N(i) 表示喜欢物品i的用户数, N(j) 表示喜欢物品j的用户数,
|N(i) N(j)|是同时喜欢物品i和j的用户数.
2、根据物品的相似度和用户的历史行为给用户生成推荐列表。
其中相似度的计算有很多种方式,比如余弦相似度、皮尔逊系数、杰卡德相似系数、欧式距离等等。
下次再聊,相似度的不同以及案例代码。https://blog.csdn.net/xiaozhaoshigedasb/article/details/85810467