果然词云是了解之前觉得很高大上,了解之后就觉得还好啦~
wordcloud各参数含义:
font_path : string #字体路径,需要展现什么字体就把该字体路径+后缀名写上,如:font_path = '黑体.ttf'
width : int (default=400) #输出的画布宽度,默认为400像素
height : int (default=200) #输出的画布高度,默认为200像素
prefer_horizontal : float (default=0.90) #词语水平方向排版出现的频率,默认 0.9 (所以词语垂直方向排版出现频率为 0.1 )
mask : nd-array or None (default=None) #如果参数为空,则使用二维遮罩绘制词云。如果 mask 非空,设置的宽高值将被忽略,遮罩形状被 mask 取代。除全白(#FFFFFF)的部分将不会绘制,其余部分会用于绘制词云。如:bg_pic = imread('读取一张图片.png'),背景图片的画布一定要设置为白色(#FFFFFF),然后显示的形状为不是白色的其他颜色。可以用ps工具将自己要显示的形状复制到一个纯白色的画布上再保存,就ok了。
scale : float (default=1) #按照比例进行放大画布,如设置为1.5,则长和宽都是原来画布的1.5倍
min_font_size : int (default=4) #显示的最小的字体大小
font_step : int (default=1) #字体步长,如果步长大于1,会加快运算但是可能导致结果出现较大的误差
max_words : number (default=200) #要显示的词的最大个数
stopwords : set of strings or None #设置需要屏蔽的词,如果为空,则使用内置的STOPWORDS
background_color : color value (default=”black”) #背景颜色,如background_color='white',背景颜色为白色
max_font_size : int or None (default=None) #显示的最大的字体大小
mode : string (default=”RGB”) #当参数为“RGBA”并且background_color不为空时,背景为透明
relative_scaling : float (default=.5) #词频和字体大小的关联性
color_func : callable, default=None #生成新颜色的函数,如果为空,则使用 self.color_func
regexp : string or None (optional) #使用正则表达式分隔输入的文本
collocations : bool, default=True #是否包括两个词的搭配
colormap : string or matplotlib colormap, default=”viridis” #给每个单词随机分配颜色,若指定color_func,则忽略该方法
random_state : int or None #为每个单词返回一个PIL颜色
fit_words(frequencies) #根据词频生成词云
generate(text) #根据文本生成词云
generate_from_frequencies(frequencies[, ...]) #根据词频生成词云
generate_from_text(text) #根据文本生成词云
process_text(text) #将长文本分词并去除屏蔽词(此处指英语,中文分词还是需要自己用别的库先行实现,使用上面的 fit_words(frequencies) )
recolor([random_state, color_func, colormap]) #对现有输出重新着色。重新上色会比重新生成整个词云快很多
to_array() #转化为 numpy array
to_file(filename) #输出到文件jieba分词:
如果根据中文文本生成词云的话,需要先用jieba分词将句子分成一个一个的词语,然后再生成词云。
jieba.cut():第一个参数为需要分词的字符串,第二个cut_all控制是否为全模式。
jieba.cut_for_search():仅一个参数,为分词的字符串,该方法适合用于搜索引擎构造倒排索引的分词,粒度比较细。
在构建VSM向量空间模型过程或者把文本转换成数学形式计算中,你需要运用到关键词提取的技术,这里就再补充该内容,而其他的如词性标注、并行分词、获取词位置和搜索引擎就不再叙述了。
基本方法:jieba.analyse.extract_tags(sentence, topK)
需要先import jieba.analyse,其中sentence为待提取的文本,topK为返回几个TF/IDF权重最大的关键词,默认值为20。
生成词云:
# -*- coding: utf-8 -*-
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
import numpy as np
import jieba
import jieba.analyse
from PIL import Image
text = open('rabbit.txt').read()
#加载模板
mask = np.array(Image.open('color_mask.png'))
#jieba分词
text = ' '.join(jieba.cut(text))
freq = jieba.analyse.extract_tags(text, topK=200, withWeight=True)
#保存为字典形式
freq = {i[0]: i[1] for i in freq}
print(freq)
#生成词云
wc = WordCloud(mask=mask, font_path='Hiragino.ttf', width=800, height=600, mode='RGBA',
background_color=None).generate_from_frequencies(freq)
#词云色调设置成从模板提取
color = ImageColorGenerator(mask)
wc.recolor(color_func=color)
#plt.imshow(wc)
plt.imshow(wc, interpolation='bilinear')
plt.show()
wc.to_file('rabbit_color.png') 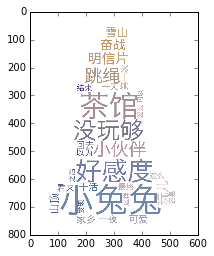
{'好感度': 0.44840895651612905, '干活': 0.2509091884664516, '怎么': 0.14256849534774194, '这么': 0.15199242669064517, '小伙伴': 0.3589706106354839, '山顶': 0.2516244741922581, '一夜': 0.22406576732548386, '看来': 0.17902500646064518, '还是': 0.12852974065032258, '明信片': 0.3534270539612903, '可爱': 0.2457551904864516, '没玩够': 0.38563766138387096, '回去': 0.1917484146432258, '一天': 0.17357702692612903, '最终': 0.1721545720183871, '家乡': 0.24200266830451614, '发现': 0.14106606009032258, '第一次': 0.1841950313248387, '之后': 0.14118842815000002, '结束': 0.17217921060225808, '跳绳': 0.35701497767419355, '奋战': 0.3032538058596774, '小兔兔': 0.7712753227677419, '茶馆': 0.5726965891051612, '可以': 0.11306836297290322, '玩儿': 0.3011719180809677, '以为': 0.17902500646064518, '这样': 0.1236065415383871, '雪山': 0.2736960403151613}