1)防火墙没关闭、或者没有启动 yarn
INFO client.RMProxy: Connecting to ResourceManager at hadoop108/192.168.10.108:8032
2)主机名称配置错误
3)ip 地址配置错误
4)ssh 没有配置好
5)root 用户和 hadoop 两个用户启动集群不统一
6)配置文件修改不细心
7)未编译源码
Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 17/05/22 15:38:58 INFO client.RMProxy: Connecting to ResourceManager at hadoop108/192.168.10.108:8032
8)datanode 不被 namenode 识别问题
Namenode 在 format 初始化的时候会形成两个标识,blockPoolId 和 clusterId。新的datanode 加入时,会获取这两个标识作为自己工作目录中的标识。一旦 namenode 重新 format 后,namenode 的身份标识已变,而 datanode 如果依然持有原来的 id,就不会被 namenode 识别。
解决办法,删除 datanode 节点中的数据后,再次重新格式化 namenode。
9)不识别主机名称
java.net.UnknownHostException: node1: node1
at java.net.InetAddress.getLocalHost(InetAddress.java:1475)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:146)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
解决办法:
(1)在/etc/hosts 文件中添加 192.168.0.241 node1
(2)主机名称不要起 hadoop hadoop000 等特殊名称
10)datanode 和 namenode 进程同时只能工作一个。
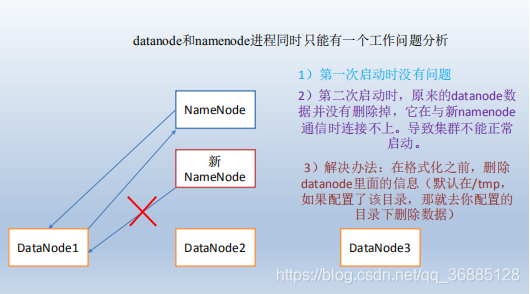
11)执行命令不生效,粘贴 word 中命令时,遇到-和长–没区分开,导致命令失效
解决办法:尽量不要粘贴 word 中代码,可以先粘贴到记事本中再复制粘贴。
12)jps 发现进程已经没有,但是重新启动集群,提示进程已经开启。原因是在 linux 的根目录下/tmp 目录中存在启动的进程临时文件,将集群相关进程删除掉,再重新启动集群。