如何进行MySQL优化
- 慢查询的开启并捕获
- explain+慢SQL分析
- show profile查询SQL在SQL在MySQL服务器里面的执行细节和生命周期情况
- SQL数据库服务器的参数调优
查询优化
- 永远小表驱动大表(类似嵌套循环NestedLoop)
- order by关键字优化
- group by关键字优化
小表驱动大表
for(int i=5...)//1
{
for(int j=1000)
}
for(int i=1000...)//1
{
for(int j=5)
}
上面这两个for循环的循环总次数是相同的,但是在MySQL中是不等效的。数据库中开销最大的就是连接和释放,第一种情况是建立了5次连接,每次做1000次查询;第二种情况是连接1000次,每次做5次查询。"永远小表驱动大表"
继续看下面的栗子:

#EXISTS
SELECT ... FROM table WHERE EXISTS (subquery)
将主查询的数据,放到子查询中做条件验证,根据验证结果(TRUE OR FALSE)来决定主查询的结果是否得以保留
为排序使用索引(Order By优化)
MySQL支持两种方式的排序,FileSort和Index,Index效率高。
MySQL能为排序和查询使用相同的索引
ORDER BY子句,尽量使用Index方式排序,避免使用FileSort方式排序。
ORDER BY满足两种情况会使用Index排序
- Ordey By使用索引最左前列(最佳左前缀法则)
- 使用Where子句与Order By子句条件列组合满足索引最左前列
看下面的栗子:
创建索引
create index idx_ageBirth on tbla(age,birth);//注意看索引的顺序
Ordey By按照索引顺序查找
explain select * from tbla where age > 20 order by age,birth;
Explain:

Ordey By不按照索引顺序查找
explain select * from tbla where age > 20 order by birth;
Explain:

如果WHERE使用索引的最左前缀为常量,则order by能使用索引
#WHERE a=const ORDER BY b,c//order by可以使用索引
#WHERE a=const AND b=const ORDER BY c//order by可以使用索引
#WHERE a=const AND b>const ORDER BY b c//order 可以使用索引
不能使用索引的情况:
#ORDER BY a ASC, b DESC,c DESC //排序不一致
#WHERE g=const ORDER BY b,c//丢失a索引
#WHERE a=const ORDER BY c//丢失b索引
#WHERE a=const ORDER BY b,d//d不是索引的一部分
#WHERE a>const ORDER BY b,c//范围不可以
尽可能索引列上完成排序操作,遵照索引建的最佳左前缀
如果不在索引列上,filesort有两种算法:mysql就要启动双路排序和单路排序
双路排序:
MySQL4.1之前是使用双路排序,字面意思就是扫描两次磁盘,最终得到数据。读取行指针和orderby列,对他们进行排序,然后扫描已经排序好的列表,按照列表中的值重新从列表中读取对应的数据输出。取一次数据,要对磁盘进行两次扫描,I\O很耗时,所以出现了改进的算法-单路排序。
单路排序:从磁盘读取查询需要的所有列,按照orderby列在buffer对它们进行排序,然后扫描排序后的列表进行输出,它的效率更快一些,避免了第二次读取数据。并且把随机IO变成了顺序IO,但是它会使用更多的空间,因为它把每一行都保存在了内存中。如果内存不足,就会取多次,使单路排序变成多路排序,造成性能低于双路排序。
优化策略:
- 增大sort_buffer_size参数的设置
- 增大max_length_for_sort_data参数的设置(Query字段大小总和小于这个值,就会使用单路算法)
为排序使用索引(Group By优化)
group by实质是先排序后进行分组,遵照索引的最左前缀法则
- 当无法使用索引列时,增大max_length_for_sort_data参数的设置+增大sort_buffer_size参数的设置
- where高于having,能写在where限定的条件就不要写在having
慢查询日志
MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阈值的语句,具体指运行时间超过long_query_time的SQL,则会被记录到慢查询日志
默认情况下,MySQL数据库没有开启慢查询日志,需要我们手动设置这个参数如果不是调优需要,不建议开启慢查询日志。
开启慢查询日志
set global slow_query_log=1;
show VARIABLES like '%slow_query_log';

使用#set global slow_query_log=1开启慢查询日志,只对当前数据库生效,MySQL重启后则失效。若要久生效需要修改my.cnf配置文件。
设置long_query_time
默认情况下long_query_time的值为10秒
命令:
SHOW VARIABLES LIKE ‘long_query_time%’;
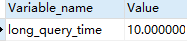
假如运行时间正好等于long_query_time的情况,并不会被记录下来。也就是说,在mysql源码里是判断大于long_query_time,而非大于等于。
手动设置慢的阈值时间
set global long_query_time=3;
之后重新连接或者开启新会话,才能看到新的修改值。
Show Profile
Show Profile是mysql提供可以用来分析当前会话中语句执行的资源消耗情况,可以用于SQL的调优的测量。
默认情况下,参数处于关闭状态,并保存最近15次的运行结果。
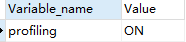
设置并查询Profiling
set profiling=on;
show VARIABLES like 'profiling';
查看profile
show profiles;

诊断SQL
show profile cpu,block io for query 135(Query_ID)

Status中不好的情况
- converting HEAP to MyISAM :查询结果太大,内存都不够用了往磁盘上搬
- Create tmp table:创建临时表
- Copying to tmp table on disk 把内存中临时表复制到磁盘
- locked