工作原理概述
简单的说一下zookeeper工作的过程,如果对这个过程还不太清楚,或者说对它如何使用等不太清楚的,可以参考一下其他的文章,比如这篇,这一系列的文章将不讲解它如何使用(实际上我也没有在具体项目中使用过,只是简单的配置运行起来大概晓得如何工作而已).
zookeeper有两种工作的模式,一种是单机方式,另一种是集群方式。单机方式不属于这里分析的范畴,因为研究zookeeper的目的就在于研究一个zookeeper集群的机器如何协调起来工作的。
要配置几台zookeeper一起工作,大家在开始必须使用相同的配置文件,配置文件中有一些配置项,但是与集群相关的是这一项:
server.1=192.168.211.1:2888:3888
server.2=192.168.211.2:2888:3888
这里定义了两台服务器的配置,格式为:
server.serverid=serverhost:leader_listent_port:quorum_port
顾名思义,serverid是本服务器的id,leader_listen_port是该服务器一旦成为leader之后需要监听的端口,用于接收来自follower的请求,quorum_port是集群中的每一个服务器在最开始选举leader时监听的端口,用于服务器互相之间通信选举leader。
需要注意的是,server id并没有写在这个配置文件中,而是在datadir中的myid文件中指定,我理解这么做的目的是:所有的服务器统一使用一个配置文件,该配置文件里面没有任何与特定服务器相关的信息,这样便于发布服务的时候不会出错,而独立出来一个文件专门存放这个server id值。
zookeeper集群工作的过程包括如下几步:
1) 、recovery,这个过程泛指集群服务器的启动和恢复,因为恢复也可以理解为另一种层面上的”启动”–需要恢复历史数据的启动,后面会详细讲解。
2) 、broadcast,这是启动完毕之后,集群中的服务器开始接收客户端的连接一起工作的过程,如果客户端有修改数据的改动,那么一定会由leader广播给follower,所以称为”broadcast”。
展开来说,zookeeper集群大概是这样工作的:
1) 首先每个服务器读取配置文件和数据文件,根据serverid知道本机对应的配置(就是前面那些地址和端口),并且将历史数据加载进内存中。
2) 集群中的服务器开始根据前面给出的quorum port监听集群中其他服务器的请求,并且把自己选举的leader也通知其他服务器,来来往往几回,选举出集群的一个leader。
3) 选举完leader其实还不算是真正意义上的”leader”,因为到了这里leader还需要与集群中的其他服务器同步数据,如果这一步出错,将返回2)中重新选举leader。在leader选举完毕之后,集群中的其他服务器称为”follower”,也就是都要听从leader的指令。
4) 到了这里,集群中的所有服务器,不论是leader还是follower,大家的数据都是一致的了,可以开始接收客户端的连接了。如果是读类型的请求,那么直接返回就是了,因为并不改变数据;否则,都要向leader汇报,如何通知leader呢?就是通过前面讲到的leader_listen_port。leader收到这个修改数据的请求之后,将会广播给集群中其他follower,当超过一半数量的follower有了回复,那么就相当于这个修改操作哦了,这时leader可以告诉之前的那台服务器可以给客户端一个回应了.
可以看到,上面1),2),3)对应的recovery过程,而4)对应的broadcast过程。
FastLeader选举算法
如何在zookeeper集群中选举出一个leader,zookeeper使用了三种算法,具体使用哪种算法,在配置文件中是可以配置的,对应的配置项是:“electionAlg”,其中1对应的是LeaderElection算法、2对应的是AuthFastLeaderElection算法、3对应的是FastLeaderElection算法。默认使用FastLeaderElection算法。其他两种算法我没有研究过,就不多说了。
要理解这个算法,最好需要一些paxos算法的理论基础。
1)、 数据恢复阶段
首先,每个在zookeeper服务器先读取当前保存在磁盘的数据,zookeeper中的每份数据,都有一个对应的id值,这个值是依次递增的,换言之,越新的数据,对应的ID值就越大。
2) 首次发送自己的投票值
在读取数据完毕之后,每个zookeeper服务器发送自己选举的leader。这个协议中包含了以下几部分的数据:
1)、所选举leader的id(就是配置文件中写好的每个服务器的id) ,在初始阶段。每台服务器的这个值都是自己服务器的id,也就是它们都选举自己为leader.
2) 服务器最大数据的id,这个值大的服务器,说明存放了更新的数据。
3)逻辑时钟的值,这个值从0开始递增,每次选举对应一个值,也就是说:如果在同一次选举中,那么这个值应该是一致的 ,逻辑时钟值越大,说明这一次选举leader的进程更新。
4) 本机在当前选举过程中的状态,有以下几种:LOOKING、FOLLOWING、OBSERVING、LEADING、顾名思义不必解释了吧.
每台服务器将自己服务器的以上数据发送到集群中的其他服务器之后,同样的也需要接收来自其他服务器的数据,它将做以下的处理:
1) 如果所接收数据服务器的状态还是在选举阶段(LOOKING 状态),那么首先判断逻辑时钟值,又分为以下三种情况:
a) 如果发送过来的逻辑时钟大于目前的逻辑时钟,那么说明这是更新的一次选举,此时需要更新一下本机的逻辑时钟值,同时将之前收集到的来自其他服务器的选举清空,因为这些数据已经不再有效了。然后判断是否需要更新当前自己的选举情况。在这里是根据选举leader id,保存的最大数据id来进行判断的,这两种数据之间对这个选举结果的影响的权重关系是:首先看数据id,数据id大者胜出;其次再判断leader id,leader id大者胜出。然后再将自身最新的选举结果(也就是上面提到的三种数据广播给其他服务器)。代码如下:
if (n.epoch > logicalclock) {
logicalclock = n.epoch;
recvset.clear();
if(totalOrderPredicate(n.leader, n.zxid,getInitId(), getInitLastLoggedZxid()))
updateProposal(n.leader, n.zxid);
else
updateProposal(getInitId(),getInitLastLoggedZxid());
sendNotifications();
其中的totalOrderPredicate函数就是根据发送过来的封包中的leader id,数据id来与本机保存的相应数据进行判断的函数,返回true说明需要更新数据,于是调用updateProposal函数更新数据
b) 发送过来数据的逻辑时钟小于本机的逻辑时钟
说明对方在一个相对较早的选举进程中,这里只需要将本机的数据发送过去就是了
c) 两边的逻辑时钟相同,此时也只是调用totalOrderPredicate函数判断是否需要更新本机的数据,如果更新了再将自己最新的选举结果广播出去就是了。
实际上,在处理选票之前,还有一个预处理的动作,它发生在刚刚接收到关于vote的message的时候,具体过程如下:
1.判断message的来源是不是observer,如果是,则告诉该observer我当前认为的Leader的信息,否则进入2
2.判断message是不是vote信息,是则进入3
3.根据message创建一张vote
4.如果当前server处理LOOKING状态,将vote放入自己的投票箱,而且如果vote源server处于LOOKING状态同时vote源server的选举时旧的,则当前server通知它新的一轮投票;
5.如果当前server不处于LOOKING状态而vote源server处理LOOKING状态,则当前server告诉它当前的Leader信息。
三种情况的处理完毕之后,再处理两种情况:
1)服务器判断是不是已经收集到了所有服务器的选举状态,如果是那么根据选举结果设置自己的角色(FOLLOWING还是LEADER),然后退出选举过程就是了。
2)即使没有收集到所有服务器的选举状态,也可以判断一下根据以上过程之后最新的选举leader是不是得到了超过半数以上服务器的支持,如果是,那么尝试在200ms内接收一下数据,如果没有新的数据到来,说明大家都已经默认了这个结果,同样也设置角色退出选举过程。
代码如下:
/*
* Only proceed if the vote comes from a replica in the
* voting view.
*/
if(self.getVotingView().containsKey(n.sid)){
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.epoch));
//If have received from all nodes, then terminate
if((self.getVotingView().size() == recvset.size()) && (self.getQuorumVerifier().getWeight(proposedLeader) != 0)){
self.setPeerState((proposedLeader == self.getId()) ? ServerState.LEADING: learningState());
leaveInstance();
return new Vote(proposedLeader, proposedZxid);
} else if (termPredicate(recvset,new Vote(proposedLeader, proposedZxid,logicalclock))) {
// Verify if there is any change in the proposed leader
while((n = recvqueue.poll(finalizeWait,TimeUnit.MILLISECONDS)) != null){
if(totalOrderPredicate(n.leader, n.zxid,proposedLeader, proposedZxid)){
recvqueue.put(n);
break;
}
}
/*
* This predicate is true once we don't read any new
* relevant message from the reception queue
*/
if (n == null) {
self.setPeerState((proposedLeader == self.getId()) ? ServerState.LEADING: learningState());
if(LOG.isDebugEnabled()){
LOG.debug("About to leave FLE instance: Leader= " + proposedLeader + ", Zxid = " + proposedZxid + ", My id = " + self.getId() + ", My state = " + self.getPeerState());
}
leaveInstance();
return new Vote(proposedLeader,proposedZxid);
}
}
} 2) 如果所接收服务器不在选举状态,也就是在FOLLOWING或者LEADING状态
做以下两个判断:
a) 如果逻辑时钟相同,将该数据保存到recvset,如果所接收服务器宣称自己是leader,那么将判断是不是有半数以上的服务器选举它,如果是则设置选举状态退出选举过程
b) 否则这是一条与当前逻辑时钟不符合的消息,那么说明在另一个选举过程中已经有了选举结果,于是将该选举结果加入到outofelection集合中,再根据outofelection来判断是否可以结束选举,如果可以也是保存逻辑时钟,设置选举状态,退出选举过程。
代码如下:
if(n.epoch == logicalclock){
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.epoch));
if((n.state == ServerState.LEADING) || (termPredicate(recvset, new Vote(n.leader,n.zxid, n.epoch, n.state))&& checkLeader(outofelection, n.leader, n.epoch)) ){
self.setPeerState((n.leader == self.getId()) ?ServerState.LEADING: learningState());
leaveInstance();
return new Vote(n.leader, n.zxid);
}
}
outofelection.put(n.sid, new Vote(n.leader, n.zxid, n.epoch, n.state));
if(termPredicate(outofelection, new Vote(n.leader,n.zxid, n.epoch, n.state))&& checkLeader(outofelection, n.leader, n.epoch)) {
synchronized(this){
logicalclock = n.epoch;
self.setPeerState((n.leader == self.getId()) ? ServerState.LEADING: learningState());
}
leaveInstance();
return new Vote(n.leader, n.zxid);
}
break;
}
} 以一个简单的例子来说明整个选举的过程。
假设有五台服务器组成的zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动,来看看会发生什么。
1) 服务器1启动,此时只有它一台服务器启动了,它发出去的报没有任何响应,所以它的选举状态一直是LOOKING状态 ;
2) 服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1,2还是继续保持LOOKING状态;
3) 服务器3启动,根据前面的理论分析,服务器3成为服务器1,2,3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的leader。
4) 服务器4启动,根据前面的分析,理论上服务器4应该是服务器1,2,3,4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了。
5) 服务器5启动,同4一样,当小弟。
写操作
ZooKeeper是专门为分布式系统提供高可用的、高性能的协作服务的,因此为了保证它的写操作,ZooKeeper采用的经典的两阶段提交协议,把写操作当作一个事务来处理。本文主要讨论该协议中的第一阶段,即事务的准备阶段。ZooKeeper的准备阶段主要就是判断该操作在当前环境下能否执行。显然,这一操作只能由当前的Leader来处理,应为Leader握有整个系统最有最全的数据。那么就让我们来研究一下Leader是如何判断各种写操作的可信性吧!
1.创建节点操作(OpCode.create)
a.根据sessionId判断创建者当前是否还有效
b.判断新节点路径是否在有效(语义)
c.根据创建者的权限来更改爱新节点的权限列表
d.根据新节点的父节点的权限列表来判断创建者是否有权创建该节点
e.如果新节点是sequential,则更新新节点的path
f.验证新节点的path
g.判断节点path是否存在,如果已存在则创建失败
h.如果父节点是ephemeral的话,则它不能有子节点,即不能创建新节点
f.更新父节点的状态信息(子节点数、版本号等)
2.删除节点操作(OpCode.delete)
a.根据sessionId判断创建者当前是否还有效
b.判断新节点路径是否在有效(语义)
c.判断节点是否存在
d.根据节点的父节点的权限列表来判断操作者是否有权删除该节点
e.判断操作者拥有该节点的信息是否是最新的,否则不能删除该节点
f.如果该节点还有子节点,则不能删除该节点
g.更新父节点的状态信息(子节点数、版本号等)
3.更新节点值操作(OpCode.setData)
a.根据sessionId判断创建者当前是否还有效
b.判断节点是否存在
c.根据节点的权限列表来判断操作者是否有权修改该节点的值
d.判断操作者拥有该节点的信息是否是最新的,否则不能修改该节点的值
e.更新父节点的状态信息(子节点数、版本号等)
4.更新节点ACL操作(OpCode.setACL)
a.根据sessionId判断创建者当前是否还有效
b.根据创建者的权限来更改新设置的节点的权限列表
c.判断节点是否存在
d.根据节点的权限列表来判断创建者是否有权更新该节点ACL
e.判断操作者拥有该节点的信息是否是最新的,否则不能更新该节点ACL
f.更新父节点的状态信息(子节点数、版本号等)
5.创建session操作(OpCode.createSeesion)
6.关闭session操作(OpCode.closeSeesion)
在修改已存在节点信息的时候,我们发现验证中会有这样一步:判断操作者拥有该节点的信息是否是最新的,否则不能更新该节点ACL,这是为什么呢?这是因为客户之所以修改节点的信息,是由于它不能“容忍”节点处于该状态,也就要千方百计的修改节点状态,如果该节点已经不再这个状态的话,再修改是没有意义的。
常用接口的使用
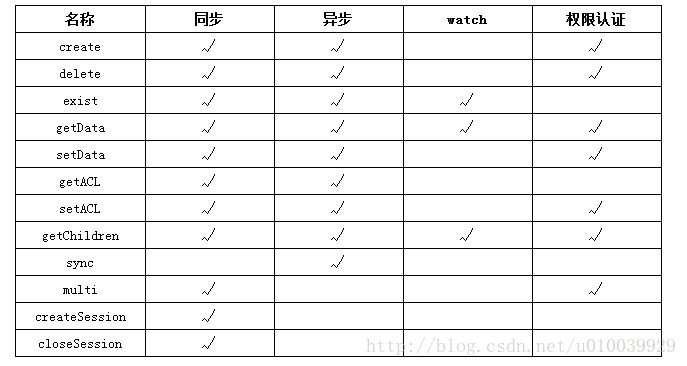
客户端要连接 Zookeeper 服务器可以通过创建 org.apache.zookeeper. ZooKeeper 的一个实例对象,然后调用这个类提供的接口来和服务器交互。
前面说了 ZooKeeper 主要是用来维护和监控一个目录节点树中存储的数据的状态,所有我们能够操作 ZooKeeper 的也和操作目录节点树大体一样,如创建一个目录节点,给某个目录节点设置数据,获取某个目录节点的所有子目录节点,给某个目录节点设置权限和监控这个目录节点的状态变化。
- 1
这些接口如下表所示:
| 方法名 | 方法功能描述 |
| Stringcreate(String path, byte[] data, List acl,CreateMode createMode) | 创建一个给定的目录节点 path, 并给它设置数据,CreateMode 标识有四种形式的目录节点,分别是 PERSISTENT:持久化目录节点,这个目录节点存储的数据不会丢失;PERSISTENT_SEQUENTIAL:顺序自动编号的目录节点,这种目录节点会根据当前已近存在的节点数自动加 1,然后返回给客户端已经成功创建的目录节点名;EPHEMERAL:临时目录节点,一旦创建这个节点的客户端与服务器端口也就是 session 超时,这种节点会被自动删除;EPHEMERAL_SEQUENTIAL:临时自动编号节点 |
| Statexists(String path, boolean watch) | 判断某个 path 是否存在,并设置是否监控这个目录节点,这里的 watcher 是在创建 ZooKeeper 实例时指定的 watcher,exists方法还有一个重载方法,可以指定特定的watcher |
| Statexists(String path,Watcher watcher) | 重载方法,这里给某个目录节点设置特定的 watcher,Watcher 在 ZooKeeper 是一个核心功能,Watcher 可以监控目录节点的数据变化以及子目录的变化,一旦这些状态发生变化,服务器就会通知所有设置在这个目录节点上的 Watcher,从而每个客户端都很快知道它所关注的目录节点的状态发生变化,而做出相应的反应 |
| void delete(String path, int version) | 删除 path 对应的目录节点,version 为 -1 可以匹配任何版本,也就删除了这个目录节点所有数据 |
| ListgetChildren(String path, boolean watch) | 获取指定 path 下的所有子目录节点,同样getChildren方法也有一个重载方法可以设置特定的 watcher 监控子节点的状态 |
| StatsetData(String path, byte[] data, int version) | 给 path 设置数据,可以指定这个数据的版本号,如果 version 为 -1 怎可以匹配任何版本 |
| byte[] getData(String path, boolean watch,Stat stat) | 获取这个 path 对应的目录节点存储的数据,数据的版本等信息可以通过 stat 来指定,同时还可以设置是否监控这个目录节点数据的状态 |
| void addAuthInfo(String scheme, byte[] auth) | 客户端将自己的授权信息提交给服务器,服务器将根据这个授权信息验证客户端的访问权限。 |
| StatsetACL(String path,List acl, int version) | 给某个目录节点重新设置访问权限,需要注意的是 Zookeeper 中的目录节点权限不具有传递性,父目录节点的权限不能传递给子目录节点。目录节点 ACL 由两部分组成:perms 和 id。 |
| Perms 有 ALL、READ、WRITE、CREATE、DELETE、ADMIN 几种 | |
| 而 id 标识了访问目录节点的身份列表,默认情况下有以下两种: | |
| ANYONE_ID_UNSAFE = new Id(“world”, “anyone”) 和 AUTH_IDS = new Id(“auth”, “”) 分别表示任何人都可以访问和创建者拥有访问权限。 | |
| ListgetACL(String path,Stat stat) | 获取某个目录节点的访问权限列表 |
除了以上这些上表中列出的方法之外还有一些重载方法,如都提供了一个回调类的重载方法以及可以设置特定 Watcher 的重载方法,具体的方法可以参考 org.apache.zookeeper. ZooKeeper 类的 API 说明。
基本操作
下面给出基本的操作 ZooKeeper 的示例代码,这样你就能对 ZooKeeper 有直观的认识了。下面的清单包括了创建与 ZooKeeper 服务器的连接以及最基本的数据操作:
清单 2. ZooKeeper 基本的操作示例
// 创建一个与服务器的连接
ZooKeeper zk = new ZooKeeper("localhost:" + CLIENT_PORT,
ClientBase.CONNECTION_TIMEOUT, new Watcher() {
// 监控所有被触发的事件
public void process(WatchedEvent event) {
System.out.println("已经触发了" + event.getType() + "事件!");
}
});
// 创建一个目录节点
zk.create("/testRootPath", "testRootData".getBytes(), Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
// 创建一个子目录节点
zk.create("/testRootPath/testChildPathOne", "testChildDataOne".getBytes(),
Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
System.out.println(new String(zk.getData("/testRootPath",false,null)));
// 取出子目录节点列表
System.out.println(zk.getChildren("/testRootPath",true));
// 修改子目录节点数据
zk.setData("/testRootPath/testChildPathOne","modifyChildDataOne".getBytes(),-1);
System.out.println("目录节点状态:["+zk.exists("/testRootPath",true)+"]");
// 创建另外一个子目录节点
zk.create("/testRootPath/testChildPathTwo", "testChildDataTwo".getBytes(),
Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
System.out.println(new String(zk.getData("/testRootPath/testChildPathTwo",true,null)));
// 删除子目录节点
zk.delete("/testRootPath/testChildPathTwo",-1);
zk.delete("/testRootPath/testChildPathOne",-1);
// 删除父目录节点
zk.delete("/testRootPath",-1);
// 关闭连接
zk.close(); 输出的结果如下:
已经触发了 None 事件!
testRootData
[testChildPathOne]
目录节点状态:[5,5,1281804532336,1281804532336,0,1,0,0,12,1,6]
已经触发了 NodeChildrenChanged 事件!
testChildDataTwo
已经触发了 NodeDeleted 事件!
已经触发了 NodeDeleted 事件!当对目录节点监控状态打开时,一旦目录节点的状态发生变化,Watcher 对象的 process 方法就会被调用。