前言
MapReduce是一种分布式计算模型,由Google 2004年提出,主要用于搜索领域,解决海量数据的计算问题。
MR由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式计算,非常简单。这两个函数的形参是key、value对,表示函数的输入信息。
特点:离线批处理、分布式计算、高容错。
缺点:不支持实时计算、流失计算、DAG(有向无环图)计算。
1. MapReduce 1.0 工作原理
下图是MapReduce1的工作原理图,主要由三个实体构成,分别如下 :
- 客户端:用于提交MapReduce作业
- JobTracker:协调作业的运行,JobTracker是一个Java的应用程序,它的主类是JobTracker
- TaskTracker:运行作业划分后的任务,TaskTracker是一个Java的应用程序,它的主类是 TaskTracker
分布式文件系统:用来在其他实体间共享作业文件:
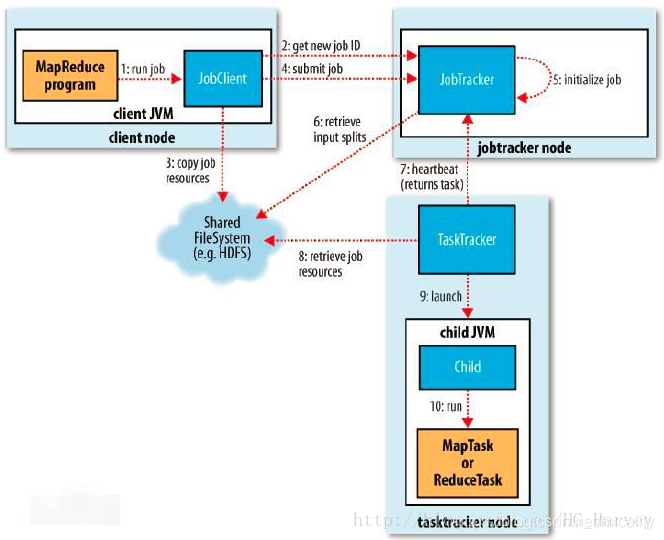
具体流程如下:
-
客户端通过submit()方法提交作业。
-
submit()方法会创建一个内部的JobSummiter实例,并且调用submitJobInternal()方法提交作业,JobSummiter向JobTracker请求一个新的作业ID,该实例会检查本次作业是否可执行(比如:检查输出路径,计算作业的输入分片等),如果可执行会将运行所需要的作业资源(JAR、配置文件等)上传到文件系统(HDFS)。
-
JobTracker接受到提交任务请求后,会放到一个内部队列里中,交由作业调度器(Job Scheduler)进行调度并初始化任务,从文件系统中获取客户端已经好的输入分片,(每个分片计算一个map),reduce任务数量由setNumReduceTask()方法设置。
-
TaskTracker会定期向JobTracker发送“心跳”,表明TaskTracker是否存活,同时“心跳”是两者之间的消息通道,当TaskTracker空闲后,会通过“心跳”发送给JobTracker,然后JobTracker会为它分配任务。
-
TaskTracker接收到JobTracker分配的任务后,从分布式文件系统中JAR文件复制到本地,开始运行任务。任务运行过程中TaskTracker会定期通过“心跳”会将任务的状态及运行情况告知JobTracker。
-
JobTracker接收到最后一个任务已完成的通知后,Job会打印一条消息告知用户,然后从waitForCompletion()方法返回,同时Job的统计信息及计数值也会打印到控制台。
2. MapReduce 2.0 工作原理
下图为MapReduce2的工作原理,主要包括如下实体
- 客户端:提交MapReduce作业。
- ResourceManager:简称RM,负责协调集群上计算资源的分配 。
- NodeManager:简称NM,负责启动和监视集群中机器上的计算容器(Container)。
- ApplicationMaster:简称AM,Yarn 中每个应用都会启动一个AM,负责向RM申请资源,请求NM启动Container,并告诉Container做什么事情。
- Container:资源容器,YARN中所有的应用是在container之上运行的。AM也是在container上运行的,不过AM的container是RM申请的。
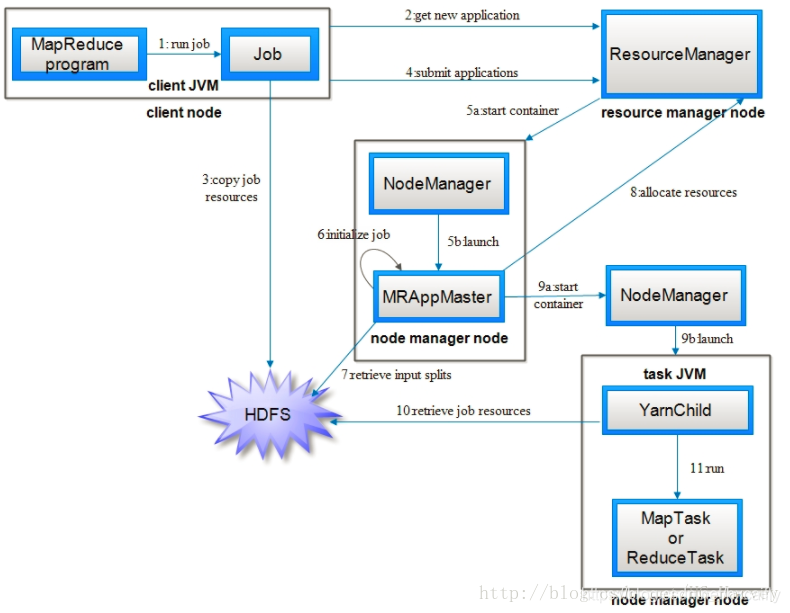
步骤1)和2)通MapReduce相似,不同的是作业ID是从资源管理器(RM)中获取,而不是JobTracker,在YARN中命名法中它是一个应用程序ID,最后调用submitApplication()方法提交作业
3).资源管理器收到作业请求后,便把请求传递给调度器,调度器分配一个容器,然后资源管理器在节点管理器的管理下在容器中启动应用程序的master进程。
4).master进程是一个java应用程序,它的主类是MRAppMaster,它对作业进行初始化:通过创建多个薄记对象以保持对作业进度的跟踪,因为它将接受来自任务的进度和完成报告。
5).master接受来自HDFS在客户端计算的输入分片,对每个分片创建一个map任务对象以及由mapreduce.job.reduces属性确定的多个reduce任务对象。
6).如果作业不适合在单个节点上运行,那么application master就会为该作业中的所有map任务和reduce任务向资源管理器请求容器,附着心跳信息的请求包括每个map任务的数据本地化信息,特别是输入分片所在的主机和相应机架信息,调度器使用这些信息来做调度决策,先数据本地化,再机架本地化。
7).一旦资源管理器的调度器为任务分配了容器,application master就通过与节点管理器通信来启动容器,在运行任务之前,首先将任务所需要的资源本地化,包括作业的配置、jar文件和所有来自分布式缓存的文件,然后执行map任务或reduce任务。
3. MapReduce WordCount
hadoop的一个jar中已经实现了wordcount,在这笔者主要介绍自己编写代码实现wordcount,使用hadoop自带的jar实现wordcount,可以执行如下命令:
$ cd hadoop/share/hadoop/mapreduce/
$ hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /wordcount/input /wordcount/output
- /wordcount/input:输入目录
- /wordcount/output:输出目录
(1).启动Hadoop集群(伪分布式)
[hadoop@harvey ~]$ start-all.sh
Starting namenodes on [harvey]
Starting datanodes
Starting secondary namenodes [harvey]
Starting resourcemanager
Starting nodemanagers
[hadoop@harvey ~]$ jps
2512 Jps
2065 ResourceManager
1635 DataNode
1844 SecondaryNameNode
2228 NodeManager
1525 NameNode
访问Hadoop Web UI 页面(注意要关闭防火墙)。
Hadoop 3.x 访问端口是9870,Hadoop 2.x 为 50070。
(2).创建Maven项目
pom.xml中引入如下依赖:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.11</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<!--<scope>test</scope>-->
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
(3).拷贝Hadoop配置文件
拷贝Hadoop的配置文件到工程的src\main\resources目录下。
配置文件位置:hadoop安装目录下的etc/hadoop中。
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
workers
(4).配置log4j.properties
src\main\resources目录下新建文件log4j.properties,配置如下:
#OFF,systemOut,logFile,logDailyFile,logRollingFile,logMail,logDB,ALL
log4j.rootLogger=ALL,systemOut
#输出到控制台
log4j.appender.systemOut= org.apache.log4j.ConsoleAppender
log4j.appender.systemOut.layout= org.apache.log4j.PatternLayout
log4j.appender.systemOut.layout.ConversionPattern= [%-5p][%-22d{yyyy/MM/dd HH:mm:ssS}][%l]%n%m%n
log4j.appender.systemOut.Threshold= INFO
log4j.appender.systemOut.ImmediateFlush= TRUE
log4j.appender.systemOut.Target= System.out
(5).MapReduce实现单词统计
words.txt 文件内容如下:
Deer Bear River
Car Car River
Deer Car Bear
分析(参考下图): 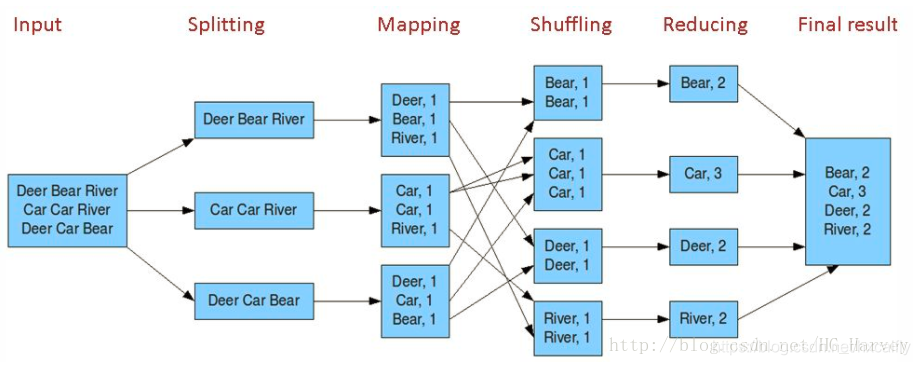
Map阶段:
1).将一个输入作为一个映射,即 key:value
说明:文件中的每行会执行一次map,针对words.txt文件中的内容会执行三次map,以文件中的第一行为例
# 行号:一行内容
1:Deer Bear River
2).处理value,拆分成独立的单词数组(按空格分隔)
{Deer} {Bear} {River}
3).当单词数组中的每个元素组成一个映射,即 key:value
Deer:1 Bear:1 River:1
Reduce阶段:
1).将map阶段产生所有key:value通过洗牌排序产生新的key:value
Deer:{1, 1} Bear{1, 1} River{1, 1} Car{1, 1, 1}
2).遍历key,累加value值,最终结果如下
Deer:2
Bear:2
River:2
Car:3
代码:
package com.bigdata.mapreduce.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* Hadoop MapReduce 单词统计
*/
public class WordCount {
/**
* Object:输入key
* Text:输入value
* Text:输出key
* IntWritable:输出value
*/
public static class WordCountMapper extends Mapper<Object, Text, Text, IntWritable> {
// (1).将一个输入作为一个映射,即 key:value
// 行号:一行内容
// 1:Deer Bear River
private final Text workKey = new Text();
private final IntWritable wordValue = new IntWritable();
/**
* Map 阶段
* @param key 输入key
* @param value 输入value
* @param context 用于输出key和value,即单词和单词次数
*/
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
// (2).处理value,拆分成独立的单词数组(按空格分隔)
// {Deer} {Bear} {River}
String[] words = line.split(" ");
if (words != null && words.length > 0){
// (3).当单词数组中的每个元素组成一个映射,即 key:value
// Deer:1 Bear:1 River:1
for (String word: words) {
workKey.set(word);
wordValue.set(1);
context.write(workKey, wordValue);
}
}
}
}
/**
* Text:输入key,等同于Map的输出key
* IntWritable:输入value,等同于Map的输出value
* Text:输出key
* IntWritable:输出value
*/
public static class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
//(1).将map阶段产生所有key:value通过洗牌排序产生新的key:value
// Deer:{1, 1} Bear{1, 1} River{1, 1} Car{1, 1, 1}
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
// (2).遍历key,累加value值,最终结果如下
for (IntWritable n: values) {
sum += n.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
conf.set("mapred.jar", "D:\\code\\study\\hadoop_mapreduce\\target\\hadoop_mapreduce-1.0.jar");
Job job = Job.getInstance(conf, "WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.out.println(job.waitForCompletion(true) ? 0 : 1);
}
}