1、python的变量都是引用形式,类似于linux的硬管道,只有链接数为0时才会回收内存
name = "Alex Li"
name2 = name
print
(name,name2)
name
=
"Jack"
print
(
"What is the value of name2 now?"
)
为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5。
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。
GB2312 支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的PC平台必须支持GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。
从ASCII、GB2312、GBK 到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK到GB18030都属于双字节字符集 (DBCS)。
有的中文Windows的缺省内码还是GBK,可以通过GB18030升级包升级到GB18030。不过GB18030相对GBK增加的字符,普通人是很难用到的,通常我们还是用GBK指代中文Windows内码。
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...

3、Python是一门先编译后解释的语言
4、万恶的字符串拼接:
str="world"
print("hello ",str)
print("hello %s"%str)
print("hello {_str}".format(_str=str))
format :
>>> msg = "my name is {}, and age is {}"
>>> msg.format("alex",22)
'my name is alex, and age is 22'
>>> msg = "my name is {1}, and age is {0}"
>>> msg.format("alex",22)
'my name is 22, and age is alex'
>>> msg = "my name is {name}, and age is {age}"
>>> msg.format(age=22,name="ale")
'my name is ale, and age is 22'
format_map
>>> msg.format_map({'name':'alex','age':22})
'my name is alex, and age is 22'
http://www.runoob.com/python/att-string-maketrans.html
5、字典
每个键与值用冒号隔开(:),每对用逗号,每对用逗号分割,整体放在花括号中({})。
键必须独一无二,但值则不必。
值可以取任何数据类型,键必须不可变,必须是不可变的,如字符串,数或元组。
Python字典是另一种可变容器模型,且可存储任意类型对象,如字符串、数字、元组等其他容器模型。
一、创建字典
字典由键和对应值成对组成。字典也被称作关联数组或哈希表。基本语法如下:
dict = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
也可如此创建字典
dict1 = { 'abc': 456 }
dict2 = { 'abc': 123, 98.6: 37 }
注意:
每个键与值用冒号隔开(:),每对用逗号,每对用逗号分割,整体放在花括号中({})。
键必须独一无二,但值则不必。
值可以取任何数据类型,但必须是不可变的,如字符串,数或元组。
二、访问字典里的值
把相应的键放入熟悉的方括弧,如下实例:

dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'};
print "dict['Name']: ", dict['Name'];
print "dict['Age']: ", dict['Age'];
#以上实例输出结果:
#dict['Name']: Zara
#dict['Age']: 7
如果用字典里没有的键访问数据,会输出错误如下:
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'};
print "dict['Alice']: ", dict['Alice'];
以上实例输出结果:
#KeyError: 'Alice'[/code]
三、修改字典
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下实例:
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'};
dict['Age'] = 8; # update existing entry
dict['School'] = "DPS School"; # Add new entry
print "dict['Age']: ", dict['Age'];
print "dict['School']: ", dict['School'];
#以上实例输出结果:
#dict['Age']: 8
#dict['School']: DPS School
四、删除字典元素
能删单一的元素也能清空字典,清空只需一项操作。
显示删除一个字典用del命令,如下实例:
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'};
del dict['Name']; # 删除键是'Name'的条目
dict.clear(); # 清空词典所有条目
del dict ; # 删除词典
print "dict['Age']: ", dict['Age'];
print "dict['School']: ", dict['School'];
#但这会引发一个异常,因为用del后字典不再存在:
dict['Age']:
五、字典键的特性
字典值可以没有限制地取任何python对象,既可以是标准的对象,也可以是用户定义的,但键不行。
两个重要的点需要记住:
1)不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住,如下实例:
dict = {'Name': 'Zara', 'Age': 7, 'Name': 'Manni'};
print "dict['Name']: ", dict['Name'];
#以上实例输出结果:
#dict['Name']: Manni
2)键必须不可变,所以可以用数,字符串或元组充当,所以用列表就不行,如下实例:
dict = {['Name']: 'Zara', 'Age': 7};
print "dict['Name']: ", dict['Name'];
#以上实例输出结果:
#TypeError: list objects are unhashable
六、字典内置函数&方法
Python字典包含了以下内置函数:
cmp(dict1, dict2) #比较两个字典元素。 len(dict) #计算字典元素个数,即键的总数。 str(dict) #输出字典可打印的字符串表示。 type(variable) #返回输入的变量类型,如果变量是字典就返回字典类型。
Python字典包含了以下内置方法:
radiansdict.clear() #删除字典内所有元素 radiansdict.copy() #返回一个字典的浅复制 radiansdict.fromkeys() #创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 radiansdict.get(key, default=None) #返回指定键的值,如果值不在字典中返回default值 radiansdict.has_key(key) #如果键在字典dict里返回true,否则返回false radiansdict.items() #以列表返回可遍历的(键, 值) 元组数组 radiansdict.keys() #以列表返回一个字典所有的键 radiansdict.setdefault(key, default=None) #和get()类似, 但如果键不已经存在于字典中,将会添加键并将值设为default radiansdict.update(dict2) #把字典dict2的键/值对更新到dict里 radiansdict.values() #以列表返回字典中的所有值
七、字典练习代码
print('''|---欢迎进入通讯录程序---|
|---1、 查询联系人资料---|
|---2、 插入新的联系人---|
|---3、 删除已有联系人---|
|---4、 退出通讯录程序---|''')
addressBook={}#定义通讯录
while 1:
temp=input('请输入指令代码:')
if not temp.isdigit():
print("输入的指令错误,请按照提示输入")
continue
item=int(temp)#转换为数字
if item==4:
print("|---感谢使用通讯录程序---|")
break
name = input("请输入联系人姓名:")
if item==1:
if name in addressBook:
print(name,':',addressBook[name])
continue
else:
print("该联系人不存在!")
if item==2:
if name in addressBook:
print("您输入的姓名在通讯录中已存在-->>",name,":",addressBook[name])
isEdit=input("是否修改联系人资料(Y/N):")
if isEdit=='Y':
userphone = input("请输入联系人电话:")
addressBook[name]=userphone
print("联系人修改成功")
continue
else:
continue
else:
userphone=input("请输入联系人电话:")
addressBook[name]=userphone
print("联系人加入成功!")
continue
if item==3:
if name in addressBook:
del addressBook[name]
print("删除成功!")
continue
else:
print("联系人不存在")
1. copy.copy 浅拷贝 只拷贝父对象,不会拷贝对象的内部的子对象。(比深拷贝更加节省内存)
2. copy.deepcopy 深拷贝 拷贝对象及其子对象
用一个简单的例子说明如下:
>>>import copy升
>>>a = [1, 2, 3, 4, ['a', 'b', 'c']]
>>> b = a
>>> c = copy.copy(a)
>>> d = copy.deepcopy(a)
很容易理解:a是一个列表,表内元素a[4]也是一个列表(也就是一个内部子对象);b是对a列表的又一个引用,所以a、b是完全相同的,可以通过id(a)==id(b)证明。
第4行是浅拷贝,第五行是深拷贝,通过id(c)和id(d)可以发现他们不相同,且与id(a)都不相同:
>>> id(a)
19276104
>>> id(b)
19276104
>>> id(c)
19113304
>>> id(d)
19286976
至于如何看深/浅拷贝的区别,可以通过下面的操作来展现:
>>> a.append(5) #操作1
>>> a[4].append('hello') #操作2
这时再查看结果:
>>> a
[1, 2, 0, 4, ['a', 'b', 'c', 'hello'], 5]
>>> b
[1, 2, 0, 4, ['a', 'b', 'c', 'hello'], 5]
>>> c
[1, 2, 3, 4, ['a', 'b', 'c', 'hello']]
>>> d
[1, 2, 3, 4, ['a', 'b', 'c']]
可以发现a、b受了操作1、2的影响,c只受操作2影响,d不受影响。a、b结果相同很好理解。由于c是a的浅拷贝,只拷贝了父对象,因此a的子对象( ['a', 'b', 'c', 'hello'])改变时会影响到c;d是深拷贝,完全不受a的影响
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
#!/usr/bin/env python3
#antuor:Alan
import
copy
# 数字, 字符串
print
(
'-----------------------------------数字---------------------------------'
)
a1
=
123
###赋值
a2
=
123
print
(
id
(a1))
print
(
'数字赋值:'
,
id
(a2))
print
(
'-----------------------------------字符串---------------------------------'
)
a3
=
'asd'
a4
=
a3
print
(
id
(a3))
print
(
'字符串赋值:'
,
id
(a4))
print
(
'-----------------------------------数字,字符串深浅拷贝---------------------------------'
)
a5
=
'alan'
a6
=
copy.copy(a5)
###浅拷贝
a7
=
copy.deepcopy(a5)
###深拷贝
print
(
id
(a5))
print
(
'字符串浅拷贝:'
,
id
(a6))
print
(
'字符串深拷贝:'
,
id
(a7))
"""字符串和数字,对这三种方法,用的是同一个内存地址"""
print
(
'-----------------------------------元祖,列表,字典---------------------------------'
)
print
(
'---------------------字典-------------------------'
)
n1
=
{
'k1'
:
'wu'
,
'k2'
:
133
,
'k3'
:[
'alan'
,
123
]}
n2
=
n1
print
(
id
(n1))
print
(
'字典赋值:'
,
id
(n2))
n3
=
copy.copy(n1)
###只拷贝第一层
n4
=
copy.deepcopy(n1)
###深拷贝
print
(
'字典浅拷贝:'
,
id
(n3))
print
(
'字典深拷贝:'
,
id
(n4))
print
(
'---------------------第1层-------------------------'
)
print
(
id
(n1[
'k1'
]))
print
(
'深浅拷贝第一层:'
,
id
(n3[
'k1'
]))
print
(
'深浅拷贝第一层:'
,
id
(n4[
'k1'
]))
print
(
'---------------------第2层-------------------------'
)
print
(
id
(n1[
'k3'
][
1
]))
print
(
'浅拷贝第二层:'
,
id
(n3[
'k3'
][
1
]))
print
(
'深拷贝第二层:'
,
id
(n4[
'k3'
][
1
]))
print
(
'-----------------------------------浅拷贝应用---------------------------------'
)
dic
=
{
"cpu"
:[
80
,],
"mem"
:[
80
,],
"disk"
:[
80
,]
}
print
(
"原数据:"
,dic)
new_copy_dic
=
copy.copy(dic)
new_copy_dic[
'cpu'
][
0
]
=
50
###因为新数据是对旧数据的浅拷贝,只拷贝父对象,不拷贝子对象,所以新子对象变影响旧,旧子对象影响新
print
(
"浅拷贝后原数据:"
,dic)
print
(
"浅拷贝数据:"
,new_copy_dic)
print
(
'-----------------------------------深拷贝应用---------------------------------'
)
#################################应用: 深拷贝###########################
dic
=
{
"cpu"
:[
80
,],
"mem"
:[
80
,],
"disk"
:[
80
,]
}
print
(
"原数据:"
,dic)
new_deepcopy_dic
=
copy.deepcopy(dic)
new_deepcopy_dic[
'cpu'
]
=
90
print
(
"深拷贝后原数据:"
,dic)
print
(
"深拷贝数据:"
,new_deepcopy_dic)
|
===========
浅拷贝是指拷贝的只是原对象元素的引用,换句话说,浅拷贝产生的对象本身是新的,但是它的内容不是新的,只是对原对象的一个引用。这里有个例子
>>> aList=[[1, 2], 3, 4]
>>> bList = aList[:] #利用切片完成一次浅拷贝
>>> id(aList)
3084416588L
>>> id(bList)
3084418156L
>>> aList[0][0] = 5
>>> aList
[[5, 2], 3, 4]
>>> bList
[[5, 2], 3, 4]
可以看到,浅拷贝生产了一个新的对象bList,但是aList的内容确实对aList的引用,所以但改变aList中值的时候,bList的值也跟着变化了。
但是有点需要特别提醒的,如果对象本身是不可变的,那么浅拷贝时也会产生两个值,见这个例子:
>>> aList = [1, 2]
>>> bList = aList[:]
>>> bList
[1, 2]
>>> aList
[1, 2]
>>> aList[1]=111
>>> aList
[1, 111]
>>> bList
[1, 2]
为什么bList的第二个元素没有变成111呢?因为数字在python中是不可变类型!!
这个顺便回顾下Python标准类型的分类:
可变类型: 列表,字典
不可变类型:数字,字符串,元组
理解了浅拷贝,深拷贝是什么自然就很清楚了。
python中有一个模块copy,deepcopy函数用于深拷贝,copy函数用于浅拷贝。
最后,对象的赋值是深拷贝还是浅拷贝?
对象赋值实际上是简单的对象引用
>>> a = 1
>>> id(a)
135720760
>>> b = a
>>> id(b)
135720760
a和b完全是一回事
#通过一个列表生成默认dict,有个没办法解释的坑,少用吧这个
>>> dict.fromkeys([1,2,3],'testd')
{1: 'testd', 2: 'testd', 3: 'testd'}
在python的词典中,有一个函数fromkeys,这里需要注意它的使用方法,如图:
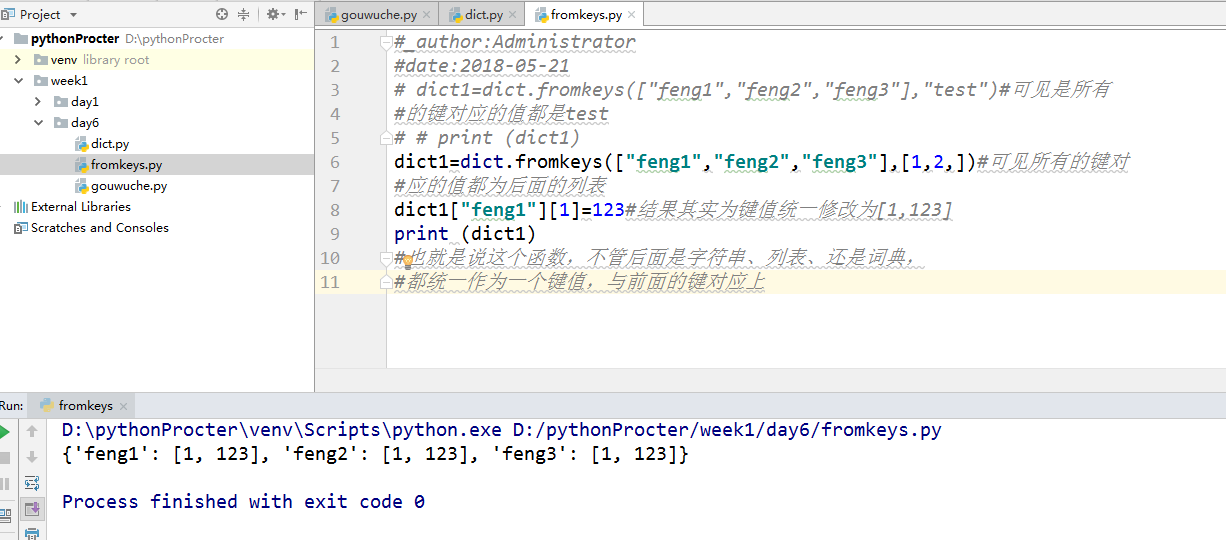
目前暂且先这样理解
python with关键字学习
1.with语句时用于对try except finally 的优化,让代码更加美观,
例如常用的开发文件的操作,用try except finally 实现:
f=open('file_name','r')
try:
r=f.read()
except:
pass
finally:
f.close()
打开文件的时候,为了能正常释放文件的句柄,都要加个try,然后再finally里把f close掉,但是这样的代码不美观,finally就像个尾巴,一直托在后面,尤其是当try里面的语句时几十行
用with的实现:
with open('file_name','r') as f:
r=f.read()
这条语句就好简洁很多,当with里面的语句产生异常的话,也会正常关闭文件
2.除了打开文件,with语句还可以用于哪些地方呢?
with只适用于上下文管理器的调用,除了文件外,with还支持 threading、decimal等模块,当然我们也可以自己定义可以给with调用的上下文管理器
2.1使用类定义上下文管理器
class A():
def __enter__(self):
self.a=1
return self
def f(self):
print 'f'
def __exit__(self,a,b,c):
print 'exit'
def func():
return A()
with A() as a:
1/0
a.f()
print a.a
使用类定义上下文管理器需要在类上定义__enter__和__exit__方法,执行with A() as a: 语句时会先执行__enter__方法,这个方法的返回值会赋值给后面的a变量,当with里面的语句产生异常或正常执行完时,都好调用类中的__exit__方法。
2.2使用生成器定义上下文管理器
from contextlib import contextmanager
@contextmanager
def demo():
print '这里的代码相当于__enter__里面的代码'
yield 'i ma value'
print '这里的代码相当于__exit__里面的代码'
with demo() as value:
print value
2.3 自定义支持 closing 的对象
class closing(object):
def __init__(self, thing):
self.thing = thing
def __enter__(self):
return self.thing
def __exit__(self, *exc_info):
self.thing.close()
class A():
def __init__(self):
self.thing=open('file_name','w')
def f(self):
print '运行函数'
def close(self):
self.thing.close()
with closing(A()) as a:
a.f()
在开发的过程中,会有很多对象在使用之后,是需要执行一条或多条语句来进行关闭,释放等操作的,例如上面说的的文件,还有数据库连接,锁的获取等,这些收尾的操作会让代码显得累赘,也会造成由于程序异常跳出后,没有执行到这些收尾操作,而导致一些系统的异常,还有就是很多程序员会忘记写上这些操作-_-!-_-!,为了避免这些错误的产生,with语句就被生产出来了。with语句的作用就是让程序员不用写这些收尾的代码,并且即使程序异常也会执行到这些代码(finally的作用)
python with as的用法
With语句是什么? 有一些任务,可能事先需要设置,事后做清理工作。对于这种场景,Python的with语句提供了一种非常方便的处理方式。一个很好的例子是文件处理,你需要获取一个文件句柄,从文件中读取数据,然后关闭文件句柄。 如果不用with语句,代码如下:
file = open("/tmp/foo.txt")
data = file.read()
file.close()
这里有两个问题。一是可能忘记关闭文件句柄;二是文件读取数据发生异常,没有进行任何处理。下面是处理异常的加强版本:
file = open("/tmp/foo.txt")
try:
data = file.read()
finally:
file.close()
虽然这段代码运行良好,但是太冗长了。这时候就是with一展身手的时候了。除了有更优雅的语法,with还可以很好的处理上下文环境产生的异常。下面是with版本的代码:
with open("/tmp/foo.txt") as file:
data = file.read()
with如何工作?
这看起来充满魔法,但不仅仅是魔法,Python对with的处理还很聪明。基本思想是with所求值的对象必须有一个__enter__()方法,一个__exit__()方法。 紧跟with后面的语句被求值后,返回对象的__enter__()方法被调用,这个方法的返回值将被赋值给as后面的变量。当with后面的代码块全部被执行完之后,将调用前面返回对象的__exit__()方法。 下面例子可以具体说明with如何工作:
#!/usr/bin/env python
# with_example01.py
class Sample:
def __enter__(self):
print "In __enter__()"
return "Foo"
def __exit__(self, type, value, trace):
print "In __exit__()"
def get_sample():
return Sample()
with get_sample() as sample:
print "sample:", sample
运行代码,输出如下
In __enter__() sample: Foo In __exit__()
正如你看到的, 1. __enter__()方法被执行 2. __enter__()方法返回的值 - 这个例子中是"Foo",赋值给变量'sample' 3. 执行代码块,打印变量"sample"的值为 "Foo" 4. __exit__()方法被调用 with真正强大之处是它可以处理异常。可能你已经注意到Sample类的__exit__方法有三个参数- val, type 和 trace。 这些参数在异常处理中相当有用。我们来改一下代码,看看具体如何工作的。
#!/usr/bin/env python
# with_example02.py
class Sample:
def __enter__(self):
return self
def __exit__(self, type, value, trace):
print "type:", type
print "value:", value
print "trace:", trace
def do_something(self):
bar = 1/0
return bar + 10
with Sample() as sample:
sample.do_something()
这个例子中,with后面的get_sample()变成了Sample()。这没有任何关系,只要紧跟with后面的语句所返回的对象有__enter__()和__exit__()方法即可。此例中,Sample()的__enter__()方法返回新创建的Sample对象,并赋值给变量sample。 代码执行后:
bash-3.2$ ./with_example02.py
type: <type 'exceptions.ZeroDivisionError'>
value: integer division or modulo by zero
trace: <traceback object at 0x1004a8128>
Traceback (most recent call last):
File "./with_example02.py", line 19, in <module>
sample.do_something()
File "./with_example02.py", line 15, in do_something
bar = 1/0
ZeroDivisionError: integer division or modulo by zero
实际上,在with后面的代码块抛出任何异常时,__exit__()方法被执行。正如例子所示,异常抛出时,与之关联的type,value和stack trace传给__exit__()方法,因此抛出的ZeroDivisionError异常被打印出来了。开发库时,清理资源,关闭文件等等操作,都可以放在__exit__方法当中。 因此,Python的with语句是提供一个有效的机制,让代码更简练,同时在异常产生时,清理工作更简单。
需知:
1.在python2默认编码是ASCII, python3里默认是unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
Python字典是另一种可变容器模型,且可存储任意类型对象,如字符串、数字、元组等其他容器模型。
一、创建字典
字典由键和对应值成对组成。字典也被称作关联数组或哈希表。基本语法如下:
dict = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
也可如此创建字典
dict1 = { 'abc': 456 }
dict2 = { 'abc': 123, 98.6: 37 }
注意:
每个键与值用冒号隔开(:),每对用逗号,每对用逗号分割,整体放在花括号中({})。
键必须独一无二,但值则不必。
值可以取任何数据类型,但必须是不可变的,如字符串,数或元组。
二、访问字典里的值
把相应的键放入熟悉的方括弧,如下实例:
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'};
print "dict['Name']: ", dict['Name'];
print "dict['Age']: ", dict['Age'];
#以上实例输出结果:
#dict['Name']: Zara
#dict['Age']: 7
如果用字典里没有的键访问数据,会输出错误如下:
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'};
print "dict['Alice']: ", dict['Alice'];
以上实例输出结果:
#KeyError: 'Alice'[/code]
三、修改字典
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下实例:
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'};
dict['Age'] = 8; # update existing entry
dict['School'] = "DPS School"; # Add new entry
print "dict['Age']: ", dict['Age'];
print "dict['School']: ", dict['School'];
#以上实例输出结果:
#dict['Age']: 8
#dict['School']: DPS School
四、删除字典元素
能删单一的元素也能清空字典,清空只需一项操作。
显示删除一个字典用del命令,如下实例:
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'};
del dict['Name']; # 删除键是'Name'的条目
dict.clear(); # 清空词典所有条目
del dict ; # 删除词典
print "dict['Age']: ", dict['Age'];
print "dict['School']: ", dict['School'];
#但这会引发一个异常,因为用del后字典不再存在:
dict['Age']:
五、字典键的特性
字典值可以没有限制地取任何python对象,既可以是标准的对象,也可以是用户定义的,但键不行。
两个重要的点需要记住:
1)不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住,如下实例:
dict = {'Name': 'Zara', 'Age': 7, 'Name': 'Manni'};
print "dict['Name']: ", dict['Name'];
#以上实例输出结果:
#dict['Name']: Manni
2)键必须不可变,所以可以用数,字符串或元组充当,所以用列表就不行,如下实例:
dict = {['Name']: 'Zara', 'Age': 7};
print "dict['Name']: ", dict['Name'];
#以上实例输出结果:
#TypeError: list objects are unhashable
六、字典内置函数&方法
Python字典包含了以下内置函数:
cmp(dict1, dict2) #比较两个字典元素。 len(dict) #计算字典元素个数,即键的总数。 str(dict) #输出字典可打印的字符串表示。 type(variable) #返回输入的变量类型,如果变量是字典就返回字典类型。
Python字典包含了以下内置方法:
radiansdict.clear() #删除字典内所有元素 radiansdict.copy() #返回一个字典的浅复制 radiansdict.fromkeys() #创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 radiansdict.get(key, default=None) #返回指定键的值,如果值不在字典中返回default值 radiansdict.has_key(key) #如果键在字典dict里返回true,否则返回false radiansdict.items() #以列表返回可遍历的(键, 值) 元组数组 radiansdict.keys() #以列表返回一个字典所有的键 radiansdict.setdefault(key, default=None) #和get()类似, 但如果键不已经存在于字典中,将会添加键并将值设为default radiansdict.update(dict2) #把字典dict2的键/值对更新到dict里 radiansdict.values() #以列表返回字典中的所有值
七、字典练习代码
print('''|---欢迎进入通讯录程序---|
|---1、 查询联系人资料---|
|---2、 插入新的联系人---|
|---3、 删除已有联系人---|
|---4、 退出通讯录程序---|''')
addressBook={}#定义通讯录
while 1:
temp=input('请输入指令代码:')
if not temp.isdigit():
print("输入的指令错误,请按照提示输入")
continue
item=int(temp)#转换为数字
if item==4:
print("|---感谢使用通讯录程序---|")
break
name = input("请输入联系人姓名:")
if item==1:
if name in addressBook:
print(name,':',addressBook[name])
continue
else:
print("该联系人不存在!")
if item==2:
if name in addressBook:
print("您输入的姓名在通讯录中已存在-->>",name,":",addressBook[name])
isEdit=input("是否修改联系人资料(Y/N):")
if isEdit=='Y':
userphone = input("请输入联系人电话:")
addressBook[name]=userphone
print("联系人修改成功")
continue
else:
continue
else:
userphone=input("请输入联系人电话:")
addressBook[name]=userphone
print("联系人加入成功!")
continue
if item==3:
if name in addressBook:
del addressBook[name]
print("删除成功!")
continue
else:
print("联系人不存在")
1. copy.copy 浅拷贝 只拷贝父对象,不会拷贝对象的内部的子对象。(比深拷贝更加节省内存)
2. copy.deepcopy 深拷贝 拷贝对象及其子对象
用一个简单的例子说明如下:
>>>import copy升
>>>a = [1, 2, 3, 4, ['a', 'b', 'c']]
>>> b = a
>>> c = copy.copy(a)
>>> d = copy.deepcopy(a)
很容易理解:a是一个列表,表内元素a[4]也是一个列表(也就是一个内部子对象);b是对a列表的又一个引用,所以a、b是完全相同的,可以通过id(a)==id(b)证明。
第4行是浅拷贝,第五行是深拷贝,通过id(c)和id(d)可以发现他们不相同,且与id(a)都不相同:
>>> id(a)
19276104
>>> id(b)
19276104
>>> id(c)
19113304
>>> id(d)
19286976
至于如何看深/浅拷贝的区别,可以通过下面的操作来展现:
>>> a.append(5) #操作1
>>> a[4].append('hello') #操作2
这时再查看结果:
>>> a
[1, 2, 0, 4, ['a', 'b', 'c', 'hello'], 5]
>>> b
[1, 2, 0, 4, ['a', 'b', 'c', 'hello'], 5]
>>> c
[1, 2, 3, 4, ['a', 'b', 'c', 'hello']]
>>> d
[1, 2, 3, 4, ['a', 'b', 'c']]
可以发现a、b受了操作1、2的影响,c只受操作2影响,d不受影响。a、b结果相同很好理解。由于c是a的浅拷贝,只拷贝了父对象,因此a的子对象( ['a', 'b', 'c', 'hello'])改变时会影响到c;d是深拷贝,完全不受a的影响
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
#!/usr/bin/env python3
#antuor:Alan
import
copy
# 数字, 字符串
print
(
'-----------------------------------数字---------------------------------'
)
a1
=
123
###赋值
a2
=
123
print
(
id
(a1))
print
(
'数字赋值:'
,
id
(a2))
print
(
'-----------------------------------字符串---------------------------------'
)
a3
=
'asd'
a4
=
a3
print
(
id
(a3))
print
(
'字符串赋值:'
,
id
(a4))
print
(
'-----------------------------------数字,字符串深浅拷贝---------------------------------'
)
a5
=
'alan'
a6
=
copy.copy(a5)
###浅拷贝
a7
=
copy.deepcopy(a5)
###深拷贝
print
(
id
(a5))
print
(
'字符串浅拷贝:'
,
id
(a6))
print
(
'字符串深拷贝:'
,
id
(a7))
"""字符串和数字,对这三种方法,用的是同一个内存地址"""
print
(
'-----------------------------------元祖,列表,字典---------------------------------'
)
print
(
'---------------------字典-------------------------'
)
n1
=
{
'k1'
:
'wu'
,
'k2'
:
133
,
'k3'
:[
'alan'
,
123
]}
n2
=
n1
print
(
id
(n1))
print
(
'字典赋值:'
,
id
(n2))
n3
=
copy.copy(n1)
###只拷贝第一层
n4
=
copy.deepcopy(n1)
###深拷贝
print
(
'字典浅拷贝:'
,
id
(n3))
print
(
'字典深拷贝:'
,
id
(n4))
print
(
'---------------------第1层-------------------------'
)
print
(
id
(n1[
'k1'
]))
print
(
'深浅拷贝第一层:'
,
id
(n3[
'k1'
]))
print
(
'深浅拷贝第一层:'
,
id
(n4[
'k1'
]))
print
(
'---------------------第2层-------------------------'
)
print
(
id
(n1[
'k3'
][
1
]))
print
(
'浅拷贝第二层:'
,
id
(n3[
'k3'
][
1
]))
print
(
'深拷贝第二层:'
,
id
(n4[
'k3'
][
1
]))
print
(
'-----------------------------------浅拷贝应用---------------------------------'
)
dic
=
{
"cpu"
:[
80
,],
"mem"
:[
80
,],
"disk"
:[
80
,]
}
print
(
"原数据:"
,dic)
new_copy_dic
=
copy.copy(dic)
new_copy_dic[
'cpu'
][
0
]
=
50
###因为新数据是对旧数据的浅拷贝,只拷贝父对象,不拷贝子对象,所以新子对象变影响旧,旧子对象影响新
print
(
"浅拷贝后原数据:"
,dic)
print
(
"浅拷贝数据:"
,new_copy_dic)
print
(
'-----------------------------------深拷贝应用---------------------------------'
)
#################################应用: 深拷贝###########################
dic
=
{
"cpu"
:[
80
,],
"mem"
:[
80
,],
"disk"
:[
80
,]
}
print
(
"原数据:"
,dic)
new_deepcopy_dic
=
copy.deepcopy(dic)
new_deepcopy_dic[
'cpu'
]
=
90
print
(
"深拷贝后原数据:"
,dic)
print
(
"深拷贝数据:"
,new_deepcopy_dic)
|
===========
浅拷贝是指拷贝的只是原对象元素的引用,换句话说,浅拷贝产生的对象本身是新的,但是它的内容不是新的,只是对原对象的一个引用。这里有个例子
>>> aList=[[1, 2], 3, 4]
>>> bList = aList[:] #利用切片完成一次浅拷贝
>>> id(aList)
3084416588L
>>> id(bList)
3084418156L
>>> aList[0][0] = 5
>>> aList
[[5, 2], 3, 4]
>>> bList
[[5, 2], 3, 4]
可以看到,浅拷贝生产了一个新的对象bList,但是aList的内容确实对aList的引用,所以但改变aList中值的时候,bList的值也跟着变化了。
但是有点需要特别提醒的,如果对象本身是不可变的,那么浅拷贝时也会产生两个值,见这个例子:
>>> aList = [1, 2]
>>> bList = aList[:]
>>> bList
[1, 2]
>>> aList
[1, 2]
>>> aList[1]=111
>>> aList
[1, 111]
>>> bList
[1, 2]
为什么bList的第二个元素没有变成111呢?因为数字在python中是不可变类型!!
这个顺便回顾下Python标准类型的分类:
可变类型: 列表,字典
不可变类型:数字,字符串,元组
理解了浅拷贝,深拷贝是什么自然就很清楚了。
python中有一个模块copy,deepcopy函数用于深拷贝,copy函数用于浅拷贝。
最后,对象的赋值是深拷贝还是浅拷贝?
对象赋值实际上是简单的对象引用
>>> a = 1
>>> id(a)
135720760
>>> b = a
>>> id(b)
135720760
a和b完全是一回事
#通过一个列表生成默认dict,有个没办法解释的坑,少用吧这个
>>> dict.fromkeys([1,2,3],'testd')
{1: 'testd', 2: 'testd', 3: 'testd'}
在python的词典中,有一个函数fromkeys,这里需要注意它的使用方法,如图:
目前暂且先这样理解
python with关键字学习
1.with语句时用于对try except finally 的优化,让代码更加美观,
例如常用的开发文件的操作,用try except finally 实现:
f=open('file_name','r')
try:
r=f.read()
except:
pass
finally:
f.close()
打开文件的时候,为了能正常释放文件的句柄,都要加个try,然后再finally里把f close掉,但是这样的代码不美观,finally就像个尾巴,一直托在后面,尤其是当try里面的语句时几十行
用with的实现:
with open('file_name','r') as f:
r=f.read()
这条语句就好简洁很多,当with里面的语句产生异常的话,也会正常关闭文件
2.除了打开文件,with语句还可以用于哪些地方呢?
with只适用于上下文管理器的调用,除了文件外,with还支持 threading、decimal等模块,当然我们也可以自己定义可以给with调用的上下文管理器
2.1使用类定义上下文管理器
class A():
def __enter__(self):
self.a=1
return self
def f(self):
print 'f'
def __exit__(self,a,b,c):
print 'exit'
def func():
return A()
with A() as a:
1/0
a.f()
print a.a
使用类定义上下文管理器需要在类上定义__enter__和__exit__方法,执行with A() as a: 语句时会先执行__enter__方法,这个方法的返回值会赋值给后面的a变量,当with里面的语句产生异常或正常执行完时,都好调用类中的__exit__方法。
2.2使用生成器定义上下文管理器
from contextlib import contextmanager
@contextmanager
def demo():
print '这里的代码相当于__enter__里面的代码'
yield 'i ma value'
print '这里的代码相当于__exit__里面的代码'
with demo() as value:
print value
2.3 自定义支持 closing 的对象
class closing(object):
def __init__(self, thing):
self.thing = thing
def __enter__(self):
return self.thing
def __exit__(self, *exc_info):
self.thing.close()
class A():
def __init__(self):
self.thing=open('file_name','w')
def f(self):
print '运行函数'
def close(self):
self.thing.close()
with closing(A()) as a:
a.f()
在开发的过程中,会有很多对象在使用之后,是需要执行一条或多条语句来进行关闭,释放等操作的,例如上面说的的文件,还有数据库连接,锁的获取等,这些收尾的操作会让代码显得累赘,也会造成由于程序异常跳出后,没有执行到这些收尾操作,而导致一些系统的异常,还有就是很多程序员会忘记写上这些操作-_-!-_-!,为了避免这些错误的产生,with语句就被生产出来了。with语句的作用就是让程序员不用写这些收尾的代码,并且即使程序异常也会执行到这些代码(finally的作用)
python with as的用法
With语句是什么? 有一些任务,可能事先需要设置,事后做清理工作。对于这种场景,Python的with语句提供了一种非常方便的处理方式。一个很好的例子是文件处理,你需要获取一个文件句柄,从文件中读取数据,然后关闭文件句柄。 如果不用with语句,代码如下:
file = open("/tmp/foo.txt")
data = file.read()
file.close()
这里有两个问题。一是可能忘记关闭文件句柄;二是文件读取数据发生异常,没有进行任何处理。下面是处理异常的加强版本:
file = open("/tmp/foo.txt")
try:
data = file.read()
finally:
file.close()
虽然这段代码运行良好,但是太冗长了。这时候就是with一展身手的时候了。除了有更优雅的语法,with还可以很好的处理上下文环境产生的异常。下面是with版本的代码:
with open("/tmp/foo.txt") as file:
data = file.read()
with如何工作?
这看起来充满魔法,但不仅仅是魔法,Python对with的处理还很聪明。基本思想是with所求值的对象必须有一个__enter__()方法,一个__exit__()方法。 紧跟with后面的语句被求值后,返回对象的__enter__()方法被调用,这个方法的返回值将被赋值给as后面的变量。当with后面的代码块全部被执行完之后,将调用前面返回对象的__exit__()方法。 下面例子可以具体说明with如何工作:
#!/usr/bin/env python
# with_example01.py
class Sample:
def __enter__(self):
print "In __enter__()"
return "Foo"
def __exit__(self, type, value, trace):
print "In __exit__()"
def get_sample():
return Sample()
with get_sample() as sample:
print "sample:", sample
运行代码,输出如下
In __enter__() sample: Foo In __exit__()
正如你看到的, 1. __enter__()方法被执行 2. __enter__()方法返回的值 - 这个例子中是"Foo",赋值给变量'sample' 3. 执行代码块,打印变量"sample"的值为 "Foo" 4. __exit__()方法被调用 with真正强大之处是它可以处理异常。可能你已经注意到Sample类的__exit__方法有三个参数- val, type 和 trace。 这些参数在异常处理中相当有用。我们来改一下代码,看看具体如何工作的。
#!/usr/bin/env python
# with_example02.py
class Sample:
def __enter__(self):
return self
def __exit__(self, type, value, trace):
print "type:", type
print "value:", value
print "trace:", trace
def do_something(self):
bar = 1/0
return bar + 10
with Sample() as sample:
sample.do_something()
这个例子中,with后面的get_sample()变成了Sample()。这没有任何关系,只要紧跟with后面的语句所返回的对象有__enter__()和__exit__()方法即可。此例中,Sample()的__enter__()方法返回新创建的Sample对象,并赋值给变量sample。 代码执行后:
bash-3.2$ ./with_example02.py
type: <type 'exceptions.ZeroDivisionError'>
value: integer division or modulo by zero
trace: <traceback object at 0x1004a8128>
Traceback (most recent call last):
File "./with_example02.py", line 19, in <module>
sample.do_something()
File "./with_example02.py", line 15, in do_something
bar = 1/0
ZeroDivisionError: integer division or modulo by zero
实际上,在with后面的代码块抛出任何异常时,__exit__()方法被执行。正如例子所示,异常抛出时,与之关联的type,value和stack trace传给__exit__()方法,因此抛出的ZeroDivisionError异常被打印出来了。开发库时,清理资源,关闭文件等等操作,都可以放在__exit__方法当中。 因此,Python的with语句是提供一个有效的机制,让代码更简练,同时在异常产生时,清理工作更简单。
需知:
1.在python2默认编码是ASCII, python3里默认是unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
1.with语句时用于对try except finally 的优化,让代码更加美观,
例如常用的开发文件的操作,用try except finally 实现:
f=open('file_name','r')
try:
r=f.read()
except:
pass
finally:
f.close()
打开文件的时候,为了能正常释放文件的句柄,都要加个try,然后再finally里把f close掉,但是这样的代码不美观,finally就像个尾巴,一直托在后面,尤其是当try里面的语句时几十行
用with的实现:
with open('file_name','r') as f:
r=f.read()
这条语句就好简洁很多,当with里面的语句产生异常的话,也会正常关闭文件
2.除了打开文件,with语句还可以用于哪些地方呢?
with只适用于上下文管理器的调用,除了文件外,with还支持 threading、decimal等模块,当然我们也可以自己定义可以给with调用的上下文管理器
2.1使用类定义上下文管理器
class A():
def __enter__(self):
self.a=1
return self
def f(self):
print 'f'
def __exit__(self,a,b,c):
print 'exit'
def func():
return A()
with A() as a:
1/0
a.f()
print a.a
使用类定义上下文管理器需要在类上定义__enter__和__exit__方法,执行with A() as a: 语句时会先执行__enter__方法,这个方法的返回值会赋值给后面的a变量,当with里面的语句产生异常或正常执行完时,都好调用类中的__exit__方法。
2.2使用生成器定义上下文管理器
from contextlib import contextmanager
@contextmanager
def demo():
print '这里的代码相当于__enter__里面的代码'
yield 'i ma value'
print '这里的代码相当于__exit__里面的代码'
with demo() as value:
print value
2.3 自定义支持 closing 的对象
class closing(object):
def __init__(self, thing):
self.thing = thing
def __enter__(self):
return self.thing
def __exit__(self, *exc_info):
self.thing.close()
class A():
def __init__(self):
self.thing=open('file_name','w')
def f(self):
print '运行函数'
def close(self):
self.thing.close()
with closing(A()) as a:
a.f()
在开发的过程中,会有很多对象在使用之后,是需要执行一条或多条语句来进行关闭,释放等操作的,例如上面说的的文件,还有数据库连接,锁的获取等,这些收尾的操作会让代码显得累赘,也会造成由于程序异常跳出后,没有执行到这些收尾操作,而导致一些系统的异常,还有就是很多程序员会忘记写上这些操作-_-!-_-!,为了避免这些错误的产生,with语句就被生产出来了。with语句的作用就是让程序员不用写这些收尾的代码,并且即使程序异常也会执行到这些代码(finally的作用)
python with as的用法
With语句是什么? 有一些任务,可能事先需要设置,事后做清理工作。对于这种场景,Python的with语句提供了一种非常方便的处理方式。一个很好的例子是文件处理,你需要获取一个文件句柄,从文件中读取数据,然后关闭文件句柄。 如果不用with语句,代码如下:
file = open("/tmp/foo.txt")
data = file.read()
file.close()
这里有两个问题。一是可能忘记关闭文件句柄;二是文件读取数据发生异常,没有进行任何处理。下面是处理异常的加强版本:
file = open("/tmp/foo.txt")
try:
data = file.read()
finally:
file.close()
虽然这段代码运行良好,但是太冗长了。这时候就是with一展身手的时候了。除了有更优雅的语法,with还可以很好的处理上下文环境产生的异常。下面是with版本的代码:
with open("/tmp/foo.txt") as file:
data = file.read()
with如何工作?
这看起来充满魔法,但不仅仅是魔法,Python对with的处理还很聪明。基本思想是with所求值的对象必须有一个__enter__()方法,一个__exit__()方法。 紧跟with后面的语句被求值后,返回对象的__enter__()方法被调用,这个方法的返回值将被赋值给as后面的变量。当with后面的代码块全部被执行完之后,将调用前面返回对象的__exit__()方法。 下面例子可以具体说明with如何工作:
#!/usr/bin/env python
# with_example01.py
class Sample:
def __enter__(self):
print "In __enter__()"
return "Foo"
def __exit__(self, type, value, trace):
print "In __exit__()"
def get_sample():
return Sample()
with get_sample() as sample:
print "sample:", sample
运行代码,输出如下
In __enter__() sample: Foo In __exit__()
正如你看到的, 1. __enter__()方法被执行 2. __enter__()方法返回的值 - 这个例子中是"Foo",赋值给变量'sample' 3. 执行代码块,打印变量"sample"的值为 "Foo" 4. __exit__()方法被调用 with真正强大之处是它可以处理异常。可能你已经注意到Sample类的__exit__方法有三个参数- val, type 和 trace。 这些参数在异常处理中相当有用。我们来改一下代码,看看具体如何工作的。
#!/usr/bin/env python
# with_example02.py
class Sample:
def __enter__(self):
return self
def __exit__(self, type, value, trace):
print "type:", type
print "value:", value
print "trace:", trace
def do_something(self):
bar = 1/0
return bar + 10
with Sample() as sample:
sample.do_something()
这个例子中,with后面的get_sample()变成了Sample()。这没有任何关系,只要紧跟with后面的语句所返回的对象有__enter__()和__exit__()方法即可。此例中,Sample()的__enter__()方法返回新创建的Sample对象,并赋值给变量sample。 代码执行后:
bash-3.2$ ./with_example02.py
type: <type 'exceptions.ZeroDivisionError'>
value: integer division or modulo by zero
trace: <traceback object at 0x1004a8128>
Traceback (most recent call last):
File "./with_example02.py", line 19, in <module>
sample.do_something()
File "./with_example02.py", line 15, in do_something
bar = 1/0
ZeroDivisionError: integer division or modulo by zero
实际上,在with后面的代码块抛出任何异常时,__exit__()方法被执行。正如例子所示,异常抛出时,与之关联的type,value和stack trace传给__exit__()方法,因此抛出的ZeroDivisionError异常被打印出来了。开发库时,清理资源,关闭文件等等操作,都可以放在__exit__方法当中。 因此,Python的with语句是提供一个有效的机制,让代码更简练,同时在异常产生时,清理工作更简单。
需知:
1.在python2默认编码是ASCII, python3里默认是unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
With语句是什么? 有一些任务,可能事先需要设置,事后做清理工作。对于这种场景,Python的with语句提供了一种非常方便的处理方式。一个很好的例子是文件处理,你需要获取一个文件句柄,从文件中读取数据,然后关闭文件句柄。 如果不用with语句,代码如下:
file = open("/tmp/foo.txt")
data = file.read()
file.close()
这里有两个问题。一是可能忘记关闭文件句柄;二是文件读取数据发生异常,没有进行任何处理。下面是处理异常的加强版本:
file = open("/tmp/foo.txt")
try:
data = file.read()
finally:
file.close()
虽然这段代码运行良好,但是太冗长了。这时候就是with一展身手的时候了。除了有更优雅的语法,with还可以很好的处理上下文环境产生的异常。下面是with版本的代码:
with open("/tmp/foo.txt") as file:
data = file.read()
with如何工作?
这看起来充满魔法,但不仅仅是魔法,Python对with的处理还很聪明。基本思想是with所求值的对象必须有一个__enter__()方法,一个__exit__()方法。 紧跟with后面的语句被求值后,返回对象的__enter__()方法被调用,这个方法的返回值将被赋值给as后面的变量。当with后面的代码块全部被执行完之后,将调用前面返回对象的__exit__()方法。 下面例子可以具体说明with如何工作:
#!/usr/bin/env python
# with_example01.py
class Sample:
def __enter__(self):
print "In __enter__()"
return "Foo"
def __exit__(self, type, value, trace):
print "In __exit__()"
def get_sample():
return Sample()
with get_sample() as sample:
print "sample:", sample
运行代码,输出如下
In __enter__() sample: Foo In __exit__()
正如你看到的, 1. __enter__()方法被执行 2. __enter__()方法返回的值 - 这个例子中是"Foo",赋值给变量'sample' 3. 执行代码块,打印变量"sample"的值为 "Foo" 4. __exit__()方法被调用 with真正强大之处是它可以处理异常。可能你已经注意到Sample类的__exit__方法有三个参数- val, type 和 trace。 这些参数在异常处理中相当有用。我们来改一下代码,看看具体如何工作的。
#!/usr/bin/env python
# with_example02.py
class Sample:
def __enter__(self):
return self
def __exit__(self, type, value, trace):
print "type:", type
print "value:", value
print "trace:", trace
def do_something(self):
bar = 1/0
return bar + 10
with Sample() as sample:
sample.do_something()
这个例子中,with后面的get_sample()变成了Sample()。这没有任何关系,只要紧跟with后面的语句所返回的对象有__enter__()和__exit__()方法即可。此例中,Sample()的__enter__()方法返回新创建的Sample对象,并赋值给变量sample。 代码执行后:
bash-3.2$ ./with_example02.py
type: <type 'exceptions.ZeroDivisionError'>
value: integer division or modulo by zero
trace: <traceback object at 0x1004a8128>
Traceback (most recent call last):
File "./with_example02.py", line 19, in <module>
sample.do_something()
File "./with_example02.py", line 15, in do_something
bar = 1/0
ZeroDivisionError: integer division or modulo by zero
实际上,在with后面的代码块抛出任何异常时,__exit__()方法被执行。正如例子所示,异常抛出时,与之关联的type,value和stack trace传给__exit__()方法,因此抛出的ZeroDivisionError异常被打印出来了。开发库时,清理资源,关闭文件等等操作,都可以放在__exit__方法当中。 因此,Python的with语句是提供一个有效的机制,让代码更简练,同时在异常产生时,清理工作更简单。
需知:
1.在python2默认编码是ASCII, python3里默认是unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string