图论算法之最小生成树
最小生成树
定义
一幅加权图的最小生成树(MST)是它的一棵权值(树中所有边的权值之和)最小的生成树。
原理
图的一种切分是将图中所有顶点分为两个非空且不重叠的两个集合。横切边是一条连接两个属于不同集合的顶点的边。(下图中的红边即为横切边)
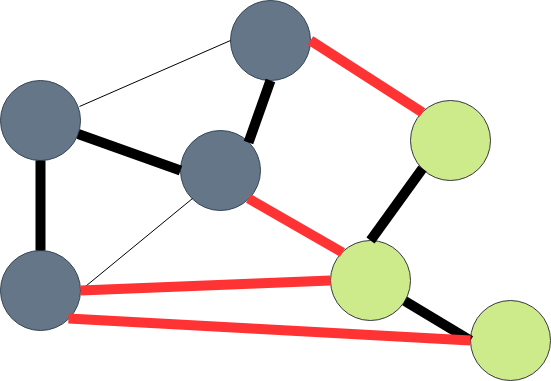
(切分定理):在一幅加权图中,给定任意的切分,它的横切边中的权重最小者必然属于图中的最小生成树。
由此可知我们只需要使用切分定理找到最小生成树的一条边,不断重复直到找到最小生成树的所有边。
数据类型基本实现
带权重的边的数据类型
package chapter4;
/**
* 带权重的边的数据类型
*/
public class Edge implements Comparable<Edge> {
private final int v;//顶点之一
private final int w;//另外一个顶点
private final double weight;//边的权重
Edge(int v, int w, double weight){
this.v=v;
this.w=w;
this.weight=weight;
}
public double weight(){
return weight;
}
/** 查询边的一个顶点 **/
public int either(){
return v;
}
/** 查询边的另外一个顶点 **/
public int other(int vertex) {
if (vertex == v) {
return w;
} else if (vertex == w) {
return v;
} else {
throw new RuntimeException("Inconsistent edge");
}
}
@Override
public int compareTo(Edge that) {
if(this.weight()<that.weight()){
return -1;
}else if(this.weight()>that.weight()){
return 1;
}else {
return 0;
}
}
public String toString(){
return String.format("%d-%d %.2f",v,w,weight);
}
}
加权无向图的数据类型
package chapter4;
import java.util.ArrayList;
import java.util.LinkedList;
public class EdgeWeightedGraph {
private final int V;//顶点总数
private int E;//边的总数
private LinkedList<Edge>[] adj;//邻接表
public EdgeWeightedGraph(int V){
this.V=V;
this.E=0;
adj=new LinkedList[V];
for (int v = 0; v < V; v++) {
adj[v]=new LinkedList<>();
}
}
public int V(){
return V;
}
public int E(){
return E;
}
/** 邻接表的构建 **/
public void addEdge(Edge e){
int v=e.either();
int w=e.other(v);
adj[v].addFirst(e);
adj[w].addFirst(e);
E++;
}
/** 查询与某个顶点v相连接的边 **/
public Iterable<Edge> adj(int v){
return adj[v];
}
/** 查询邻接表所有的边 **/
public Iterable<Edge> edges(){
ArrayList<Edge> list = new ArrayList<>();
for (int v = 0; v < V; v++) {
for (Edge edge : adj[v]) {
if(!list.contains(edge)){
list.add(edge);
}
}
}
return list;
}
}
Prim算法延时实现
算法思想:每次将下一条连接树中的顶点与不在树中的顶点且权重最小的边加入最小生成树中。
原理
每当向树中添加了一条边之后,也向树中添加了一个顶点,就要将连接这个顶点和其他所有不在树中的顶点的边加入优先队列(新加入树中的顶点与其他已经在树中顶点的所有边都失效),然后再取出优先队列中的非失效边,将其添加到最小生成树中。

最小生成树的Prim算法实现
package chapter4;
import edu.princeton.cs.algs4.MinPQ;
import edu.princeton.cs.algs4.Queue;
public class LazyPrimMST {
private boolean[] marked;//最小生成树的顶点,true即为该顶点已被添加到最小生成树中
private Queue<Edge> mst;//最小生成树的边
private MinPQ<Edge> pq;//横切边(包括是小的边),最小权值优先队列
public LazyPrimMST(EdgeWeightedGraph G){
pq=new MinPQ<Edge>();
marked=new boolean[G.V()];
mst=new Queue<>();
visit(G,0);//将起始顶点的所有边添加到优先队列中
while(!pq.isEmpty()){
Edge edge = pq.delMin();//取出优先队列中权值最小的边
int v=edge.either();//取出权值最小边的两个顶点v和w
int w=edge.other(v);
if(marked[v]&&marked[w]){
//如果顶点v和顶点w都已被添加到最小生成树中,证明该权
//值最小边已失效,直接进入下一次循环继续从优先队列
//中取下一条权值最小边
continue;
}
mst.enqueue(edge);//将边添加到最小生成树中
/** 将顶点(v或w)添加到最小生成树中,并将与其连接的非失效边添加到优先队列中 **/
if(!marked[w]){
visit(G,w);
}
if(!marked[v]){
visit(G,v);
}
}
}
/** 将顶点v添加到最小生成树中,将连接顶点v的所有非失效边添加到优先队列中 **/
private void visit(EdgeWeightedGraph G,int v){
marked[v]=true;
for (Edge edge : G.adj(v)) {
/** 添加非失效边 **/
if(!marked[edge.other(v)]){
pq.insert(edge);
}
}
}
}
Kruskal算法
Prim算法是一棵树不断生长的过程,而Kruskal算法是不断地将两棵树合并直到只剩下一棵树。
原理
按照边的权值顺序从小到大处理它们,将边加入到最小生成树中,要求加入的边不会与已经加入的边构成环,直到树中含有V-1条边。(V为顶点总数)

最小生成树的Kruskal算法实现
package chapter4;
import edu.princeton.cs.algs4.MinPQ;
import edu.princeton.cs.algs4.Queue;
import edu.princeton.cs.algs4.UF;
/**使用了一条队列来保存最小生成树的所有边、
*一条优先队列来保存还未被检查的边和一个union-find的数据结构来判断是否会产生环
*/
public class KruskalMST {
private Queue<Edge> mst;//最小生成树队列
public KruskalMST(EdgeWeightedGraph G){
mst=new Queue<>();
MinPQ<Edge> pq=new MinPQ<>();//最小权值优先队列
/** 将所有边插入到优先队列中 **/
for (Edge edge : G.edges()) {
pq.insert(edge);
}
UF uf = new UF(G.V());//连通图
while(!pq.isEmpty()&&mst.size()<G.V()-1){
Edge e=pq.delMin();//取出权值最小的边并得到两个顶点v和w
int v=e.either();
int w=e.other(v);
if(uf.connected(v,w)){//忽略失效边,避免构成环
continue;
}
mst.enqueue(e);//将边添加到最小生成树中
uf.union(v,w);//合并分量
}
}
/** 返回最小生成树 **/
public Iterable<Edge> edges(){
return mst;
}
/** 计算最小生成树权值 **/
public double weight(){
double sumOfWeight=0;
for (Edge edge : mst) {
sumOfWeight+=edge.weight();
}
return sumOfWeight;
}
}