版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_41723615/article/details/88045392
首先回顾下传统MVC思想的工作流程:
用户在视图发送请求给控制器,控制器调用模型处理业务返回响应数据,接着选择视图现实响应数据
下面简述下MVC思想的优点:
| 1.多个视图能共享一个模型:提高了模型层程序代码的可重用性 |
| 2.模型是自包含的,与控制器和视图保持相对独立,因此可以方便地改变应用程序的业务数据和业务规则。例如同一项目,不同数据库之间的移植,由于MVC的三个模块相互独立,改变其中一个不会影响其他两个,所以依据这种设计思想能构造良好的松耦合的组件。 |
| 3.控制器提高了应用程序的灵活性和可配置性。 控制器可以用来连接不同的模型和视图去完成用户的需求,控制器为构造应用程序提供了强有力的重组手段。给定一些可重用的模型和视图,控制器可以根据用户的需求选择适当的模型进行业务逻辑处理,然后选择适当的视图将处理结果显示给用户。 |
先来看看springmvc的三大组件之间的关系:见图(图片来自网络):

| 1.用户发送request请求到前端控制器(DispatcherServlet)——接收用户请求和响应 |
| 2.DispatcherServlet请求HandlerMapping(处理器映射器)查找Handler,根据xml配置和注解查找 |
| 3.随后HandlerMapping回头返回Handler给dispatcherServlet |
| 4.dispatcherServlet请求调用处理器适配器(HandlerAdapter)帮忙执行返回过来的Handler(Controller) |
| 5.执行完后Handler给适配器返回modelAndView |
| 6.接着处理器适配器就要把modelAndView返回给dispatcherServlet |
| 7.随后dispatcherServlet请求视图解析器(ViewResolver)来对视图进行解析 |
| 8.解析完后,ViewResolver向dispatcherServlet返回View |
| 9.dispatcherServlet对View渲染(把在ModelAndView对象中的模型数据填充到request域中) |
| 10.最后dispatcherServlet向用户响应结果 |
| 总结:清楚在springmvc中M-V-C三层中的关系 |
了解了MVC思想与springmvc的工作流程,接下来对struts2的工作流程进行解析:见图(图片来自网络)
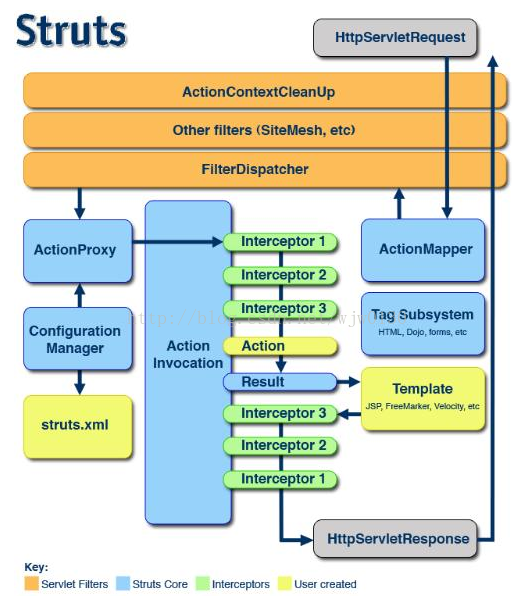
| 1.用户在客户端用浏览器发送请求,请求会被Tomcat接收到,接着Tomcat服务器来选择处理这个请求的Web应用。 |
| 2.接着Web容器会去读取这个应用工程的web.xml文件,在web.xml中进行匹配,此过程会调用struts2.1之后的过滤器(StrutsPrepareAndExecuteFilter)进行处理,根据过滤器找到struts2的调度中心(FilterDispatcher)。 |
| 3.接着获取FilterDispatcher实例,随后回调doFilter()方法。 |
| 4.接着FilterDispatcher会将请求转发给ActionMapper,让ActionMapper来识别请求是否需要struts2做出处理,若需要,则ActionMapper会通知FilterDispatcher来处理这个请求,随后FilterDispatcher会停止过滤器链以后的部分。然后建立一个ActionProxy实例。 |
| 5.ActionProxy对象在被创建出来的时候,并不知道要运行哪个Action,它手里只有FilterDispatcher中拿到的请求的URL。而真正知道要运行哪个Action的时ConfigurationManager。因为只有它,才能读取我们的struts.xml文件。在服务器启功的时候,ConfigurationManager就会把struts.xml中的所有信息读取到内存里,并缓存,当ActionProxy带着URL向它询问要运行哪个Action的时候,就可以直接匹配,查找并回答了。 |
| 6.ActionProxy知道自己该干什么事之后(运行哪个Action、相关的拦截器以及所有可能使用的result信息),然后马上建立ActionInvocation对象了,ActionInvocation对象描述了Action运行的整个过程。Action完整的调用过程都是由ActionInvocation对象负责。 |
| 7.在execute方法之前,好像URL请求中的参数已经赋值到了Action的属性上,这就是拦截器。拦截器的运行被分成两部分,一部分在Action之前运行,一部分在Result之后运行,而且顺序是刚好反过来的。也就是在Action执行前的顺序,比如是拦截器1、拦截器2、拦截器3,那么运行Result之后,再次运行拦截器的时候,顺序就变成拦截器3、拦截器2、拦截器1了。 |
| 8.到了拦截器1的时候,就执行Action的execute方法。 |
| 9.接着根据execute方法返回的结果(Result),去struts.xml中匹配选择下一个页面。 |
| 10.根据result找到页面后,在页面上(有很多Struts2提供的模板),可以通过Struts2自带的标签库来访问需要的数据,并生成最终页面,这时还没有给客户端应答,只是生成了页面。 |
| 11.最后,ActionInvocation对象倒序执行拦截器,从拦截器1的位置回来 |
| 12.ActionInvocation对象执行完毕后,已经得到响应对象(HttpServletResponse)了,最后按与过滤器(Filter)配置定义相反的顺序依次经过过滤器,向客户端展示出响应的结果。 |
springmvc与struts2的区别:
- 1、Struts2是类级别的拦截, 一个类对应一个request上下文,SpringMVC是方法级别的拦截,一个方法对应一个request上下文,而方法同时又跟一个url对应,所以说从架构本身上SpringMVC就容易实现restful url,而struts2的架构实现起来要费劲,因为Struts2中Action的一个方法可以对应一个url,而其类属性却被所有方法共享,这也就无法用注解或其他方式标识其所属方法了。
- 2、由上边原因,SpringMVC的方法之间基本上独立的,独享request response数据,请求数据通过参数获取,处理结果通过ModelMap交回给框架,方法之间不共享变量,而Struts2搞的就比较乱,虽然方法之间也是独立的,但其所有Action变量是共享的,这不会影响程序运行,却给我们编码 读程序时带来麻烦,每次来了请求就创建一个Action,一个Action对象对应一个request上下文。
- 3、由于Struts2需要针对每个request进行封装,把request,session等servlet生命周期的变量封装成一个一个Map,供给每个Action使用,并保证线程安全,所以在原则上,是比较耗费内存的。
- 4、 拦截器实现机制上,Struts2有以自己的interceptor机制,SpringMVC用的是独立的AOP方式,这样导致Struts2的配置文件量还是比SpringMVC大。
- 5、SpringMVC的入口是servlet,而Struts2是filter(这里要指出,filter和servlet是不同的。以前认为filter是servlet的一种特殊),这就导致了二者的机制不同,这里就牵涉到servlet和filter的区别了。
- 6、SpringMVC集成了Ajax,使用非常方便,只需一个注解@ResponseBody就可以实现,然后直接返回响应文本即可,而Struts2拦截器集成了Ajax,在Action中处理时一般必须安装插件或者自己写代码集成进去,使用起来也相对不方便。
- 7、SpringMVC验证支持JSR303,处理起来相对更加灵活方便,而Struts2验证比较繁琐,感觉太烦乱。
- 8、Spring MVC和Spring是无缝的。从这个项目的管理和安全上也比Struts2高(当然Struts2也可以通过不同的目录结构和相关配置做到SpringMVC一样的效果,但是需要xml配置的地方不少)。
- 9、 设计思想上,Struts2更加符合OOP的编程思想, SpringMVC就比较谨慎,在servlet上扩展。
- 10、SpringMVC开发效率和性能高于Struts2。
- 11、SpringMVC可以认为已经100%零配置。