这次整理的为三个原理上相近的排序算法,便于比较对比分析,通过他们之间的不同理解三个算法的特点,从而能够设计出符合三者的算法。首先呢,这三个算法都不是基于比较的算法,这和前面的那些算法不同,其核心内容不再通过比较然后交换两者的位置了,而这次要说的是在排序的时候将其顺序和“桶”的顺序相关联起来,通过不同的排序规则,进行排序,然后按照顺序进行输出,这些就是此三类算法的大致流程。
计数排序
解释这一通是为了有个大体印象,不至于在阅读代码的时候产生浑然不知。首先我们看一个较为简单的,叫做计数排序,这个排序可以很好的应用到整数排序,其主要的核心思想为寻找出数组中最大和最小元素,然后开辟max-min大小的数组,然后对原数组进行遍历,原数组某位置的元素值为多少,则在新开辟的辅助数组中的对应位置(辅助数组下标为原数组元素值)加1(可能有重复的数字),然后将其按照某一顺序重新写回原来的数组。来看下代码是怎么完成这个过程的:
public class CountSort {
public static void countSort(int[] array, int size){
int max_vaue = array[0];//序列中的最大值
int min_value = array[0];//序列中的最小值
//找到序列中的最大值和最小值
for(int i = 0; i < size; i++){
if(array[i] >= max_vaue) {
max_vaue = array[i];
}
if(array[i] <= min_value){
min_value = array[i];
}
}
//计算辅助数组的长度并开辟相应的空间
int range = max_vaue - min_value + 1;
int[] helpCount = new int [range];
//helpCount[array[i]-min_value]++; 将对应的数字放置
//即求得array[i]相对于min_value值的距离是多少
//到对应的位置
for(int i = 0; i < size; i++){
helpCount[array[i] - min_value] ++;
}
int index = 0;
//遍历辅助空间
for(int i = 0; i < range; i++){
while (helpCount[i] -- > 0){//下标是几则说明出现了几次
//将下标处的数字拉回原来数组
array[index++] = i + min_value;
}
}
}
}其实一点本质的东西就是将原数组的元素的值和help数组的下标值联系起来,因为我们在进行比较排序的时候比较的也是元素的值,也即说明顺序包含在原数组的值当中,所以我们改变一下策略,使得原数组元素值对因为新数组的下标索引值。
好了,如果理解好了上面这个计数排序算法之后,再来一个桶排序吧,所谓的循序渐进嘛:
桶排序
说道桶排序,其核心的思想有点和散列表有些向,有原来的一排桶中现在变为了多排桶,桶的第一排来接受经过计算后被分配到这一列桶,后续插入的元素则在这一咧往下排列,这么说抽象哈,可以参考下面的图和博客。
https://www.cnblogs.com/ECJTUACM-873284962/p/6935506.html
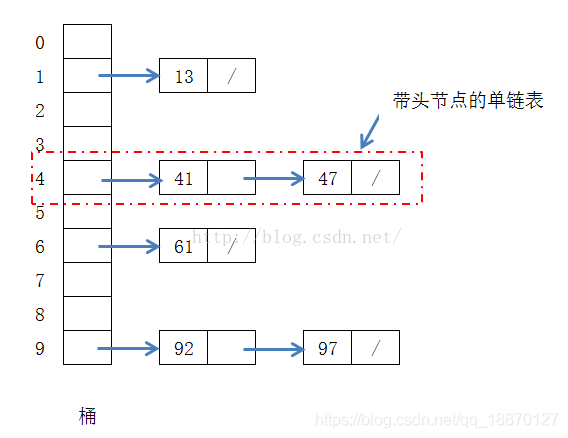
是不是很像定址法散列表的样子?那该怎么设计呢,参考下面的代码:
public class BucketSort {
public void bucketSort(int[] array, int bucketSize){
//用于存放排序后的结果
int[] result = new int[array.length];
//开辟bucket的大小为bucketSize
Node[] bucket = new Node[bucketSize];
//初始化每个节点
for(int i = 0 ; i < bucket.length; i++){
bucket[i] = new Node();
}
//核心部分,将各个元素按照刚才所示的图的形式进行分组放入
//桶中
for(int i = 0; i < array.length; i++){
int bucketIndex = hash(array[i]);
Node node = new Node(array[i]);
Node p = bucket[bucketIndex];
if(p.next == null){//无节点的情况
p.next = node;
}else{
//插入到连表中的情况,链表的插入操作还是比较快速的
while (p.next != null && p.next.val <= node.val){
p = p.next;
}
//更新链表节点
node.next = p.next;
p.next = node;
}
}
int j = 0;
//将桶中的结果放入到结果数组中
for(int i = 0; i < bucket.length; i++){
for (Node p = bucket[i].next; p != null; p = p.next){
result[j++] = p.val;
}
}
//将结果拷贝回原数组
for(int i = 0; i < array.length; i++){
array[i] = result[i];
}
}
//此哈希非彼哈希,这个主要是为了能够将元素“散列”到各个桶之中
public int hash(int val){
return val / 10;
}
//定义节点Node类型
class Node{
public Node(){
this(0);
}
public Node(int val){
this.val = val;
}
private int val;
private Node next;
}
}基数排序
基数排序是一种来自于老式的穿卡机上的算法,一个卡片有80列,每一列可以在12个位置上穿孔,排序器可以被机器机械的“程序化”,其利用这样的方式方便了老式机器对卡片进行检查。对于我们通用的10进制数字来说,每一列中只用到10个位置,一个d位数字占用d个列,因为卡片器一次只能查看一个数列。直觉上可以利用高位数字进行判别,但是其是不然,因为如果这样排序的话,10个位置的9个必须放置到一边,这个过程产生了较大的空间浪费,如果以低位进行,则会有效的解决这个问题。此时的基数排序则相当于对于数列先按照个位数进行排列,然后按照十位进行,然后不断的进行到最高位(若没有的话,用0代替)。对于此算法来说重要的问题就是排序算法一定要稳定。说了这么多不如一个图,也许你看下图就明白了:
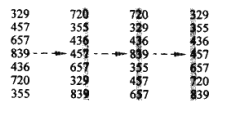
算法核心较为简单,但是如何设计这个算法呢,有这么几个地方需要注意:首先要注意排序的顺序,是由低位到高位,其次还要注意算法的另一个问题,如何保存每次排序的结果,在一个就是,如何比较长度不同的数字,其次就是如何正确的将其放入到正确的桶的位置,可以参考一下代码:
public class RadixSort {
/**
* 获取array数组中的最大值
* @param array 待排序数组
* @return 返回数组中的最大值
*/
private static int getMaxValue(int[] array){
int max_value;
max_value = array[0];
for(int i = 1; i < array.length; i++){
if(array[i] > max_value){
max_value = array[i];
}
}
return max_value;
}
public static void radixSortCore(int[] array, int exp){
//开辟辅助数据,用于存放每次得到的排序结果
int[] output = new int [array.length];
//bucket用于存放每一位数字对应的在0-9的位置,其值
//为每个数字的数量
int[] bucket = new int[10];
//按照每次指定了exp(此为对于某一位进行取余然后寻找位置)
for(int i = 0; i < array.length; i++){
bucket[(array[i] / exp) % 10]++;
}
//此过程可以更改bucket,使得更改后的bucket数组中的值
// 为array数组中数据,在经过排序之后在output数组中的下标
//需要注意的是,需要结合下面两个for循环过程
for(int i = 1; i < 10; i++){
bucket[i] += bucket[i - 1];
}
//例如array = 12,34,63,79,86,45;则bucket中的索引值从0-9所对
//对应的内容为;0,0,1,1,1,1,1,0,0,1,经过上面的for循环后
//可以得到0,0,1,2,3,4,5,5,5,6 此时,
// [bucket[(array[array[i] / exp]) % 10] - 1,可以分析为:若按照个位计算,
//(array[i] / exp) % 10 为bucket数组的索引,若i = 5 时,可以得到
//(array[i] / exp) % 10 为5,则bucket [(array[i] / exp) % 10]为4
//则output的索引值(array[i] / exp) % 10] - 1为3,即output的第四个位置
//而排序之后的结果为:12,63,34,45,86,79。可以发现符合结果
for (int i = array.length - 1; i >= 0; i--){
output[bucket [(array[i] / exp) % 10] - 1 ] = array[i];
//当有重复数字的时候有效,即当此位置的数字个数-1
bucket[(array[i] / exp)% 10 ] --;
}
/**
* 移动到原来的数组
*/
for (int i = 0; i < array.length; i++){
array[i] = output[i];
}
output = null;
bucket = null;
}
public static void radix_sort(int[] array){
int max = getMaxValue(array);
for(int exp = 1; max / exp > 0; exp *= 10){
radixSortCore(array,exp);
}
}
}