一直以来,对urllib库的使用次数很少,初学时便是用的requests库。相比较而言,requests库功能更加强大而且使用起来也很简单,非常适合初学者学习。那么有人可能会问为什么还要了解urllib库呢?因为这是Python内置的HTTP请求模块,可以加深自己对爬虫和其它库的认知和理解,并且运行速度也比较快。当然使用上还是更加推荐requests,稍后会写一篇来介绍requests库。
本文只针对Python3,对于Python2的urllib和urllib2库就不再赘述。
作为Pyhton的标准库,它包含多个使用URL的模块:
- urllib.request:最基本的HTTP请求模块,用来模拟发送请求,打开和阅读URLs。
- urllib.error:异常处理模块,包含 urllib.request 抛出的异常。
- urllib.parse:用于处理URL,比如拆分、拆解、合并等。
- urllib.robotparser:用于解析 robots.txt 文件,然后判断哪些网站可以爬,哪些网站不能爬。
注意:在导入模块时,不建议采用 import urllib 的方式使用,因为urllib文件夹的__init__.py文件里面是空的,并没有将其它几个文件导入进来,使用时会报错,但是用一些编译器运行时还是会编译成功,因为有些插件有容错功能。建议采用 import urllib.request 或 from urllib import request 的方式导入,不会出问题。
发送请求
1.urlopen()方法
使用 urllib.request 可以很方便地构造HTTP请求,先举一个抓取网页的例子:
import urllib.request
response = urllib.request.urlopen("https://www.python.org")
print(response.read().decode('utf-8'))
运行结果:
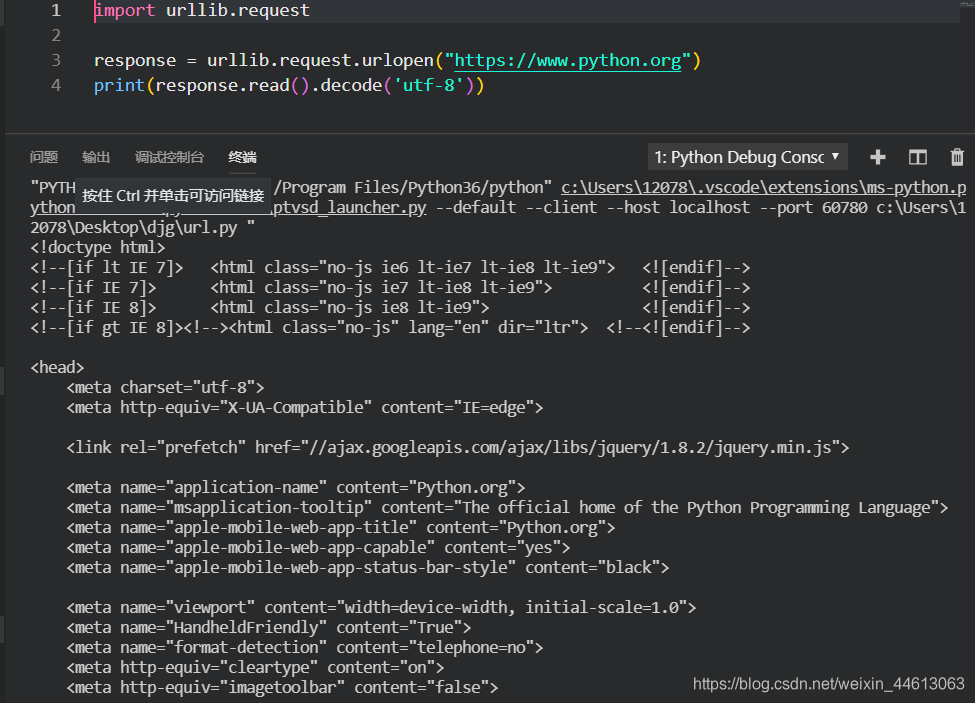
可以看到Pyhton官网的网页源代码已经被爬取下来了,这样一些链接和文本信息就都可以提取下来了。
整个网页是一个 HTTPResponse 类型的对象,把它赋值给 response 变量后,就可以调用 read() 等方法来读取一些信息。
常用方法和属性举例:
| method | 说明 |
|---|---|
| read() | 读取源代码 |
| status | 返回响应状态码 |
| getheaders() | 返回响应的头信息 |
| getheader(name) | 返回头信息里面name对应的内容 |
如果要给链接传递一些参数,可以放在后面一起传递。先看一下urlopen()的API:
urlopen(url, data=None, [timeout,]*, cafile=None,
capath=None, cadefault=False, context=None)
几个参数的作用:
| parameter | 说明 |
|---|---|
| url | 请求URL(必传) |
| data | 提交信息 |
| timeout | 超时时间(s) |
| cafile | 指定CA证书 |
| capath | CA证书的路径 |
| (已弃用) | |
| context | 指定SSL设置 |
2.Request
当请求中需要加入Headers等信息时,可以利用更强大的Request类来构建。
先举个例子:
import urllib.request
request = urllib.request.Request("https://www.python.org")
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
依然是用 urlopen() 方法来发送请求,只不过参数变成了一个Request类型的对象。这样不仅可以将请求独立成一个对象,还可以更加丰富和灵活地配置参数。
下面看一下Request的构造方法:
class Request:
def __init__(self, url, data=None, headers={},
origin_req_host=None, unverifiable=False,
method=None):
几个参数的作用:
| parameter | 说明 |
|---|---|
| url | 请求URL(必传) |
| data | 提交信息 |
| headers | 请求头(字典形式) |
| origin_req_host | 请求方的host名称或IP地址 |
| unverifiable | 表示请求是否是无法验证 |
| method | 指示请求方法(字符串形式) |
3.Handler类
对于一些高级操作,比如Cookies和代理等,就需要靠一些Handler类来充当处理器。urllib.request里面有一个BaseHandler类,是所有其它Handler的父类,它提供最基本的方法。
以下是一些Handler子类,列举下来:
| class | 说明 |
|---|---|
| HTTPDefaultErrorHandler | 定义HTTP错误响应的默认处理程序的类 |
| HTTPRedirectHandler | 处理重定向的类 |
| HTTPCookieProcessor | 处理HTTP Cookie的类 |
| ProxyHandler | 用于设置代理,默认代理为空 |
| HTTPPasswordMgr | 保留映射数据库 |
| HTTPBasicAuthHandler | 处理远程主机的身份验证 |
就不一一举例和介绍了,还有一些其它的Handler类可以参考官方文档:https://docs.python.org/zh-cn/3/library/urllib.request.html#urllib.request.BaseHandler
处理异常
1.URLError
URLError类来自urlib库的error模块.它继承自OSError类,是error异常模块的基类,由reqpuest莫块生的异常都可以通过捕获这个类来处理。
举个例子:
from urllib import request, error
try:
response = request.urlopen('https://www.csdn.net/index')
except error.URLError as e:
print(e.reason)
我们打开一个不存在的页面,照理来说应该会报错,但是这时我们捕获了URLError这个异常,运行结果如下:

程序没有直接报错,而是输出了如上内容,这样我们就可以避免程序异常终止,同时异常得到了有效处理。
2.HTTPError
用来处理HTTP请求错误,有一下属性:
- code:返回HTTP状态码
- reason:返回错误的原因
- headers:返回请求头
解析链接
urlparse
将URL解析为六个组件,返回一个6元组。这对应于URL的一般结构:scheme://netloc/path;parameters?query#fragment。每个元组项都是一个字符串,可能是空的。组件不会以较小的部分分解(例如,网络位置是单个字符串),并且不会展开 %escapes 。如上所示的分隔符不是结果的一部分,除了路径组件中的前导斜杠,如果存在则保留。例如:
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=1#comment')
print(type(result), result)
运行结果:
<class 'urllib.parse.ParseResult'>
ParseResult(scheme='http', netloc='www.baidu.com', path='/index.html', params='user', query='id=1', fragment='comment')
返回一个ParseResult的对象,包含6个部分。
还有一些方法可以看官方文档:https://docs.python.org/zh-cn/3/library/urllib.parse.html#module-urllib.parse
分析 Robots 协议
robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。因为一些系统中的URL是大小写敏感的,所以robots.txt的文件名应统一为小写。robots.txt应放置于网站的根目录下。如果想单独定义搜索引擎的漫游器访问子目录时的行为,那么可以将自定的设置合并到根目录下的robots.txt,或者使用robots元数据(Metadata,又称元数据)。
robots.txt协议并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私。注意robots.txt是用字符串比较来确定是否获取URL,所以目录末尾有与没有斜杠“/”表示的是不同的URL。
robotparser
该类用起来非常简单,只需要在构造方法里传入robots.txt的链接即可。首先看一下它的声明:
urllib.robotparser.RobotFileParser(url='')
常用方法:
| method | 说明 |
|---|---|
| set_url(url) | 设置引用robots.txt文件的URL |
| read() | 读取robots.txtURL并将其提供给解析器 |
| parse(lines) | 解析某些行的参数 |
| can_fetch(useragent, url) | 返回某搜索引擎是否可以抓取这个URL |
| mtime() | 返回robots.txt上次提取文件的时间 |
| modified() | 将robots.txt文件上次提取的时间设置为当前时间 |
| crawl_delay(useragent) | 返回有问题的useragent的Crawl-delay参数值 |
| request_rate(useragent) | 从robots.txt中返回Request-rate参数 |
可以看一下CSDN的:
from urllib.robotparser import RobotFileParser
rp = RobotFileParser()
rp.set_url('https://www.csdn.net/robots.txt')
rp.read()
print(rp.can_fetch('*', 'https://blog.csdn.net/weixin_44613063/article/details/86905577'))
结果: