编程环境:jupyter notebook ,python3.6 ,tensorflow1.12
0.准备文件夹

在桌面新建此名文件夹,文件夹中输入cmd:
跳出命令行输入jupyter notebook

新建一个word2vec_test.ipynb:
rename为:word2vec_test
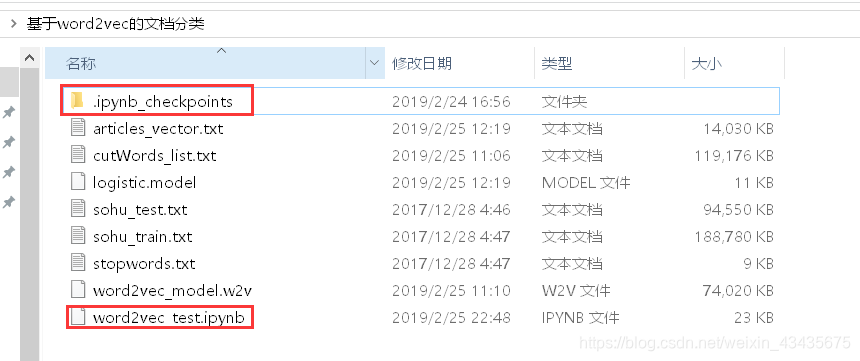
此时文件夹多了以下两个文件:
1.数据的准备
训练集共有24000条样本,12个分类,每个分类2000条样本。
测试集共有12000条样本,12个分类,每个分类1000条样本。
链接:https://pan.baidu.com/s/1UbPjMpcp3kqvdd0HMAgMfQ 提取码:b53e
下图红色框里为压缩包解压的文件:
加载训练集到变量train_df中,并打印训练集前5行,代码如下:
#训练集数据共有24000条,测试集数据共有12000条
import pandas as pd
#加载训练集到变量train_df中,并打印训练集前5行,代码如下。
#read_csv方法中有3个参数,第1个参数是加载文本文件的路径,第2个关键字参数sep是分隔符,第3个关键字参数header是文本文件的第1行是否为字段名。
train_df = pd.read_csv('sohu_train.txt', sep='\t', header=None)
train_df.head()

#查看训练集每个分类的名字以及样本数量
for name, group in train_df.groupby(0):
print(name,len(group))

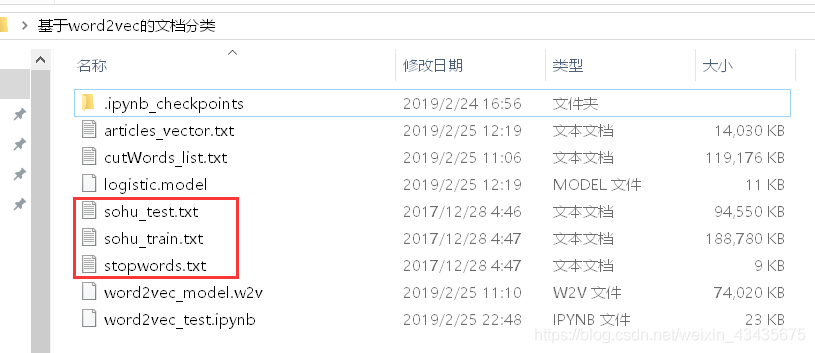
#加载测试集并查看每个分类的名字以及样本数量
test_df = pd.read_csv('sohu_test.txt', sep='\t', header=None)
for name, group in test_df.groupby(0):
print(name, len(group))
分词:
#对训练集的24000条样本循环遍历,使用jieba库的cut方法获得分词列表赋值给变量cutWords
#判断分词是否为停顿词,如果不为停顿词,则添加进变量cutWords中
import jieba
import time
train_df.columns = ['分类', '文章']
stopword_list = [k.strip() for k in open('stopwords.txt', encoding='utf8').readlines() if k.strip() != '']
cutWords_list = []
i = 0
startTime = time.time()
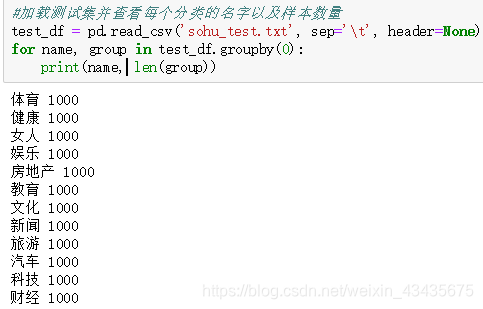
for article in train_df['文章']:
cutWords = [k for k in jieba.cut(article) if k not in stopword_list]
i += 1
if i % 1000 == 0:
print('前%d篇文章分词共花费%.2f秒' %(i, time.time()-startTime))
cutWords_list.append(cutWords)
运行结果:
#将分词结果保存为本地文件cutWords_list.txt
with open('cutWords_list.txt', 'w') as file:
for cutWords in cutWords_list:
file.write(' '.join(cutWords) + '\n')
本文作者提供已经分词完成的文本文件:
链接:https://pan.baidu.com/s/1oKjLZjSkqE0LfLEvLxkBNw 提取码:oh3u
#载入分词文件
with open('cutWords_list.txt') as file:
cutWords_list = [k.split() for k in file.readlines()]
2.word2vec模型
完成此步骤需要先安装gensim库,安装命令:pip install gensim
#调用gensim.models.word2vec库中的LineSentence方法实例化模型对象
from gensim.models import Word2Vec
word2vec_model = Word2Vec(cutWords_list, size=100, iter=10, min_count=20)
#调用模型对象的方法时,一直提示警告信息,避免出现警告信息
import warnings
warnings.filterwarnings('ignore')
#调用Word2Vec模型对象的wv.most_similar方法查看与摄影含义最相近的词。
#wv.most_similar方法有2个参数,第1个参数是要搜索的词,第2个关键字参数topn数据类型为正整数,是指需要列出多少个最相关的词汇,默认为10,即列出10个最相关的词汇。
#wv.most_similar方法返回值的数据类型为列表,列表中的每个元素的数据类型为元组,元组有2个元素,第1个元素为相关词汇,第2个元素为相关程度,数据类型为浮点型。
word2vec_model.wv.most_similar('摄影')
运行结果:

wv.most_similar方法使用positive和negative这2个关键字参数的简单示例:查看女人+先生-男人的结果:
word2vec_model.most_similar(positive=['女人', '先生'], negative=['男人'], topn=1)
运行结果:
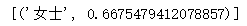
查看两个词的相关性,如下图所示:

保存Word2Vec模型为word2vec_model.w2v文件,代码如下:
word2vec_model.save('word2vec_model.w2v')
3.特征工程:
#对于每一篇文章,获取文章的每一个分词在word2vec模型的相关性向量
#然后把一篇文章的所有分词在word2vec模型中的相关性向量求和取平均数,即此篇文章在word2vec模型中的相关性向量
#实例化Word2Vec对象时,关键字参数size定义为100,则相关性矩阵都为100维
#定义getVector函数获取每个文章的词向量,传入2个参数,第1个参数是文章分词的结果,第2个参数是word2vec模型对象
#变量vector_list是通过列表推导式得出单篇文章所有分词的词向量,通过np.array方法转成ndarray对象再对每一列求平均值
#第1种方法,用for循环常规计算
''''import numpy as np
import time
def getVector_v1(cutWords, word2vec_model):
count = 0
article_vector = np.zeros(word2vec_model.layer1_size)
for cutWord in cutWords:
if cutWord in word2vec_model:
article_vector += word2vec_model[cutWord]
count += 1
return article_vector / count
startTime = time.time()
vector_list = []
i = 0
for cutWords in cutWords_list[:5000]:
i += 1
if i % 1000 ==0:
print('前%d篇文章形成词向量花费%.2f秒' %(i, time.time()-startTime))
vector_list.append(getVector_v1(cutWords, word2vec_model))
X = np.array(vector_list)
#第2种方法,用pandas的mean方法计算
''''import time
import pandas as pd
def getVector_v2(cutWords, word2vec_model):
vector_list = [word2vec_model[k] for k in cutWords if k in word2vec_model]
vector_df = pd.DataFrame(vector_list)
cutWord_vector = vector_df.mean(axis=0).values
return cutWord_vector
startTime = time.time()
vector_list = []
i = 0
for cutWords in cutWords_list[:5000]:
i += 1
if i % 1000 ==0:
print('前%d篇文章形成词向量花费%.2f秒' %(i, time.time()-startTime))
vector_list.append(getVector_v2(cutWords, word2vec_model))
X = np.array(vector_list)
#第3种方法,用numpy的mean方法计算
import time
import numpy as np
def getVector_v3(cutWords, word2vec_model):
vector_list = [word2vec_model[k] for k in cutWords if k in word2vec_model]
cutWord_vector = np.array(vector_list).mean(axis=0)
return cutWord_vector
startTime = time.time()
vector_list = []
i = 0
for cutWords in cutWords_list:
i += 1
if i % 1000 ==0:
print('前%d篇文章形成词向量花费%.2f秒' %(i, time.time()-startTime))
vector_list.append(getVector_v3(cutWords, word2vec_model))
X = np.array(vector_list)
运行结果:

#第4种方法,用numpy的add、divide方法计算
''''import time
import numpy as np
def getVector_v4(cutWords, word2vec_model):
i = 0
index2word_set = set(word2vec_model.wv.index2word)
article_vector = np.zeros((word2vec_model.layer1_size))
for cutWord in cutWords:
if cutWord in index2word_set:
article_vector = np.add(article_vector, word2vec_model.wv[cutWord])
i += 1
cutWord_vector = np.divide(article_vector, i)
return cutWord_vector
startTime = time.time()
vector_list = []
i = 0
for cutWords in cutWords_list[:5000]:
i += 1
if i % 1000 ==0:
print('前%d篇文章形成词向量花费%.2f秒' %(i, time.time()-startTime))
vector_list.append(getVector_v4(cutWords, word2vec_model))
X = np.array(vector_list)
#因为形成特征矩阵的花费时间较长,为了避免以后重复花费时间,把特征矩阵保存为文件。
#使用ndarray对象的dump方法,需要1个参数,数据类型为字符串,为保存文件的文件名
X.dump('articles_vector.txt')
#加载此文件中的内容赋值给变量X
X = np.load('articles_vector.txt')
4.模型训练,模型评估
4.1 标签编码:
#标签编码
#调用sklearn.preprocessing库的LabelEncoder方法对文章分类做标签编码
from sklearn.preprocessing import LabelEncoder
import pandas as pd
train_df = pd.read_csv('sohu_train.txt', sep='\t', header=None)
train_df.columns = ['分类', '文章']
labelEncoder = LabelEncoder()
y = labelEncoder.fit_transform(train_df['分类'])
4.2 逻辑回归模型
#调用sklearn.linear_model库的LogisticRegression方法实例化模型对象。
#调用sklearn.model_selection库的train_test_split方法划分训练集和测试集
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2)
logistic_model = LogisticRegression()
logistic_model.fit(train_X, train_y)
logistic_model.score(test_X, test_y)
运行结果:
0.789375
4.3 保存模型
#调用sklearn.externals库中的joblib方法保存模型为logistic.model文件
from sklearn.externals import joblib
joblib.dump(logistic_model, 'logistic.model')
#加载模型
from sklearn.externals import joblib
logistic_model = joblib.load('logistic.model')
4.4 交叉验证
#交叉验证的结果更具有说服力。
#调用sklearn.model_selection库的ShuffleSplit方法实例化交叉验证对象。
#调用sklearn.model_selection库的cross_val_score方法获得交叉验证每一次的得分
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import cross_val_score
cv_split = ShuffleSplit(n_splits=5, train_size=0.7, test_size=0.2)
logistic_model = LogisticRegression()
score_ndarray = cross_val_score(logistic_model, X, y, cv=cv_split)
print(score_ndarray)
print(score_ndarray.mean())
运行结果:
[0.79104167 0.77375 0.78875 0.77979167 0.78958333]
0.7845833333333333
4.5 模型测试
#模型测试
#调用sklearn.externals库的joblib对象的load方法加载模型赋值给变量logistic_model。
#调用pandas库read_csv方法读取测试集数据。
#调用DataFrame对象的groupby方法对每个分类分组,从而每种文章类别的分类准确性。
#调用自定义的getVector方法将文章转换为相关性向量。
#自定义getVectorMatrix方法获得测试集的特征矩阵。
#调用StandardScaler对象的transform方法将预测标签做标签编码,从而获得预测目标值
import pandas as pd
import numpy as np
from sklearn.externals import joblib
import jieba
def getVectorMatrix(article_series):
return np.array([getVector_v3(jieba.cut(k), word2vec_model) for k in article_series])
logistic_model = joblib.load('logistic.model')
test_df = pd.read_csv('sohu_test.txt', sep='\t', header=None)
test_df.columns = ['分类', '文章']
for name, group in test_df.groupby('分类'):
featureMatrix = getVectorMatrix(group['文章'])
target = labelEncoder.transform(group['分类'])
print(name, logistic_model.score(featureMatrix, target))
上段代码运行结果:
体育 0.968
健康 0.814
女人 0.772
娱乐 0.765
房地产 0.879
教育 0.886
文化 0.563
新闻 0.575
旅游 0.82
汽车 0.934
科技 0.817
财经 0.7
5.总结
word2vec模型应用,训练集数据共有24000条,测试集数据共有12000条。经过交叉验证,模型平均得分为0.78左右。(测试集的验证效果中,体育、教育、健康、文化、旅游、汽车、娱乐这7个分类得分较高,即容易被正确分类。女人、娱乐、新闻、科技、财经这5个分类得分较低,即难以被正确分类。)