表和数据完整性
- 表是SQL Server数据库中最重要的数据对象,也是构建高性能数据库的基础。在程序开发与应用过程中,表是存储数据的基本单元。
- 数据表的设计的优劣将影响磁盘空间使用效率、数据处理时内存的利用率以及数据的查询效率。
- 数据完整性则是保证表中数据正确与完整的关键。
3.1 SQL Server 2005 的数据类型
- 数据库中的所有数据都存放在按行与列格式组织的表中,数据类型是数据的一种属性,决定数据存储的空间和格式。
- 数据类型可以为对象定义4个属性:
- 对象包含的数据种类
- 所存储值占有的空间(字节数)和数值范围
- 数值的精度(仅适用于数值类型)
- 数值的小数位数(仅适用于数值类型)
- SQL Server 2005提供的数据类型可以归纳为:数值类型、字符类型、日期时间类型、货币类型和其他数据类型。
3.1.1 数值类型
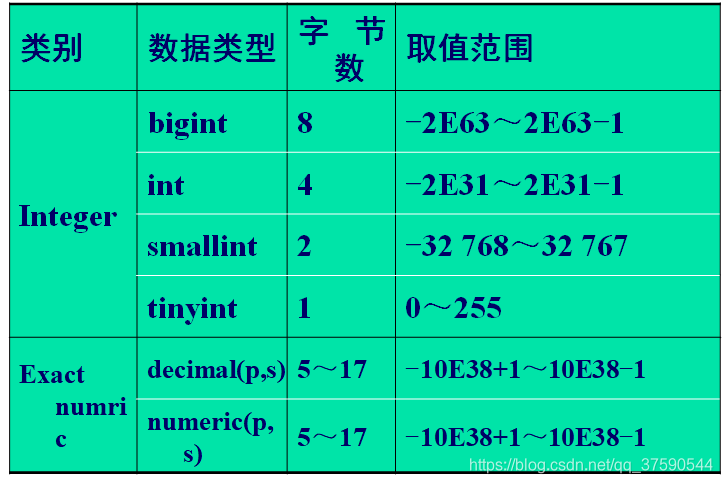
- 精确数值类型
用来存储没有小数位的整数或定点小数。
任何算术运算符都可以操作数值。
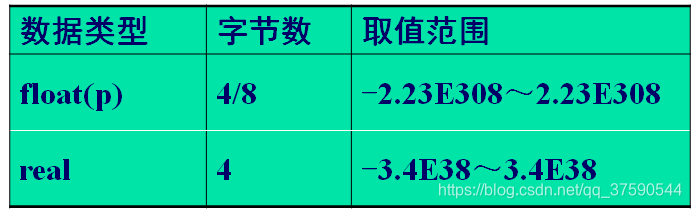
- 近似数值类型
存储十进制值,用于表示浮点数据。
对小数点右边的数进行四舍五入。只有在精确数据类型不够大,不能存储数值时,才考虑使用float。
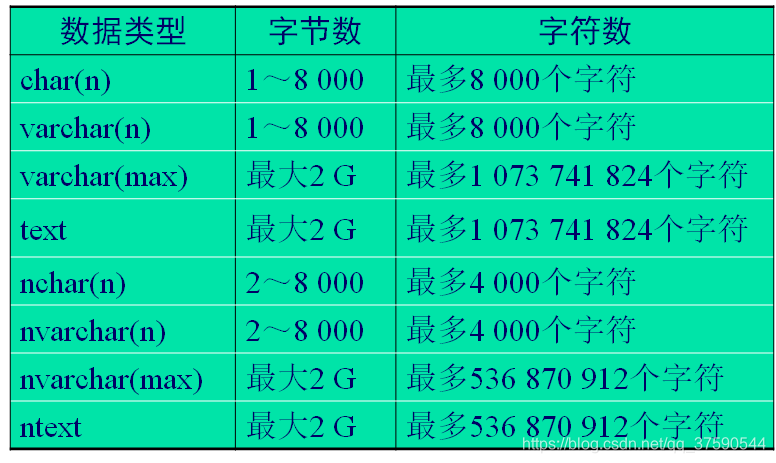
3.1.2 字符类型
- 字符类型是用于存储字符型数据的。
- Unicode标准使用2个字节来表示每个字符。
- 在SQL Server 2005中,Unicode数据以nchar、nvarchar和ntext数据类型存储。定义一个字符数据类型时,指定该列允许存储的最大字节数。
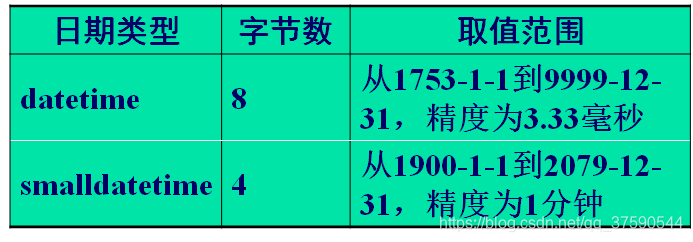
3.1.3 日期时间类型
- 日期时间类型数据,可具体分为datatime与smalldatetime两种类型。datatime和smalldatetime数据类型在计算机内部是作为整数存储的。
- datetime类型存储为一对4字节整数,它们一起表示自1753年1月1日午夜12点钟经过的毫秒数。
- smalltime类型存储为一对2字节整数,它们一起表示自1900年1月1日午夜12点钟经过的分钟数。
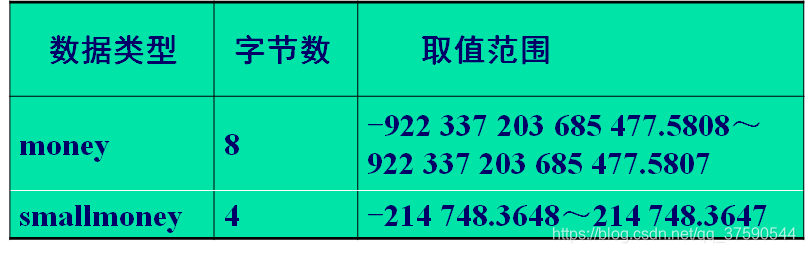
3.1.4 货币类型
- 货币数据类型旨在存储精确到4个小数位的货币值。
3.1.5 其他数据类型
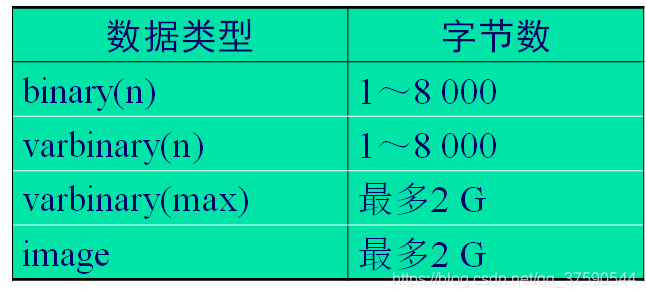
- 二进制数据类型
- 特殊数据类型
SQL Server 2005还提供了7种特殊数据类型,包括cursor、sql_variant、timestamp、table、uniqueidentifier与xml。
- timestamp 用于表示SQL server 活动的先后顺序,以二进投影的格式表示。timestamp 数据与插入数据或者日期和时间没有关系。
- bit 由 1 或者 0 组成,当表示真或者假、on 或者 off 时,使用 bit 数据类型。
- uniqueidentifier 由 16 字节的十六进制数字组成,表示一个全局唯一的。
- 当表的记录行要求唯一时,GUID是非常有用。
- 自定义数据类型
- SQL Server 2005允许用户根据自己的需要自定义数据类型(UDT),并可以用此数据类型来声明变量或列。
- 自定义类型提供了一种可以将更能清楚地说明对象中值的类型的名称应用于数据类型的机制,这使程序员或数据库管理员能够更容易地理解用该数据类型定义的对象的用途。
3.2 表的创建与维护
3.2.1 表的类型
- 按照表的用途分类
(1)系统表
(2)用户表
(3)已分区表 - 按照表的存储时间分类
(1)永久性
(2)临时表
- 所有临时表都是在tempdb数据库中创建的
- 通过使用create table命令并在表名前添加一个字符(#),可以创建局部临时表
3.2.2 表的创建
- 利用Transaxt-SQL语句创建数据表
create table 的语法格式如下:
create table [database_name.[schema_name].|schema_name.]table_name
({<column_dfinition>| computed_column_definition>}
[<table_constraint>][,…n])
[ON{partition_scheme_name(partition_column_name)
| filegroup | “default”}]
[{TEXTIMAGE_ON{filegroup|“default”}}[;]
例3.1
利用CREATE TABLE命令建立课程信息表course,表结构如表所示。
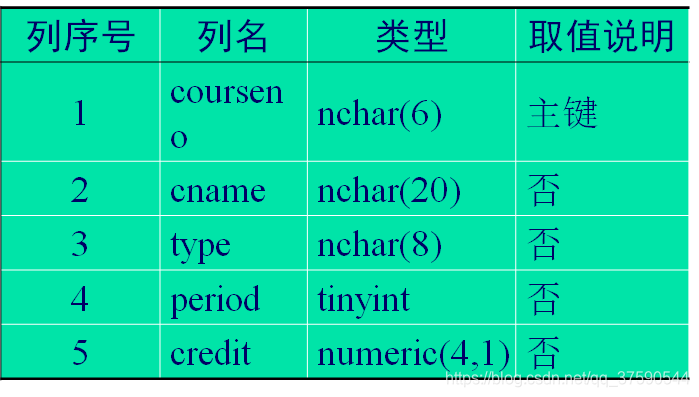
create table teaching.dbo.course(
courseno nchar(6) not null,
cname nchar(20) null,
type nchar(8) null,
credit numeric(4,1) null,
constraint pk_course primary key
clustered(courseno asc))
on [primary]
其中,pk_course 表示创建主键时的索引名称,可以是任意标识符。
clustered 项表示聚集索引类型
asc表示按courseno值升序方式排列数据,若是desc则表示降序
例3.2
利用CREATE TABLE命令建立学生分数表score,表结构如表所示。该表中主键由两个列构成。 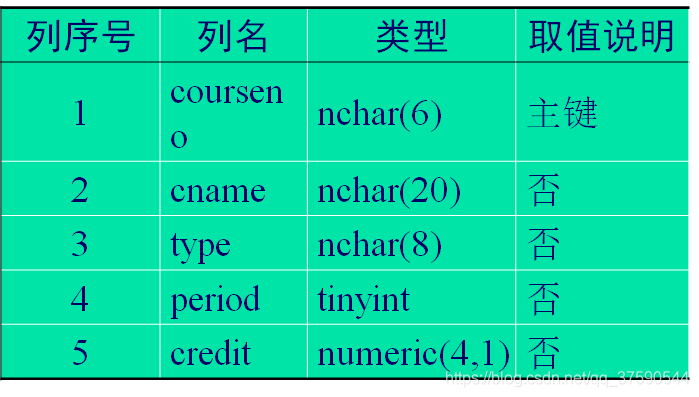
create table score teaching.dbo.score(
studentno nchar(10) not null,
coureno nchar(6) not null,
usually numeric(6,2) null,
final numeric(6,2) null,
constraint pk_score primary key
clustered (studentno asc,courseno asc))
将studentno, courseno列都设为主键
例3.3
利用CREATE TABLE命令建立教师信息表teacher,表结构如表所示。
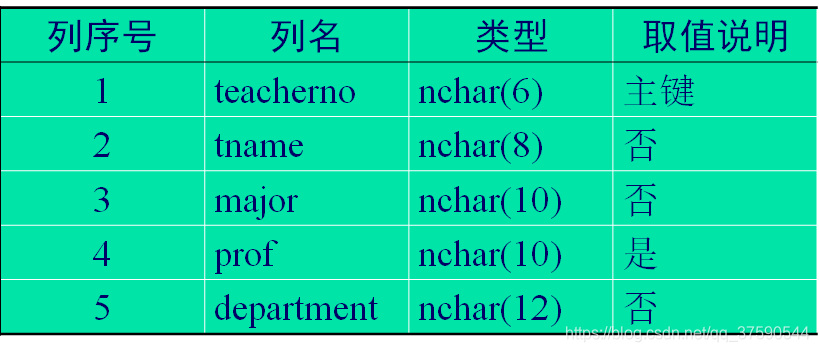
create table teaching.dbo.teacher(
teacherno nchar(6) not null,
tname nchar(8) null,
major nchar(10) null
prof nchar(10) not null,
department nchar(12) null,
constraint pk_teacheer primary key
clustered (teacherno asc))
图形界面方式,生成sql代码
USE [teaching]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[class](
[classno] nchar NOT NULL,
[classname] nchar NULL,
[department] nchar NULL,
[monitor] nchar NULL,
CONSTRAINT [PK_class] PRIMARY KEY CLUSTERED
(
[classno] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
例3.5
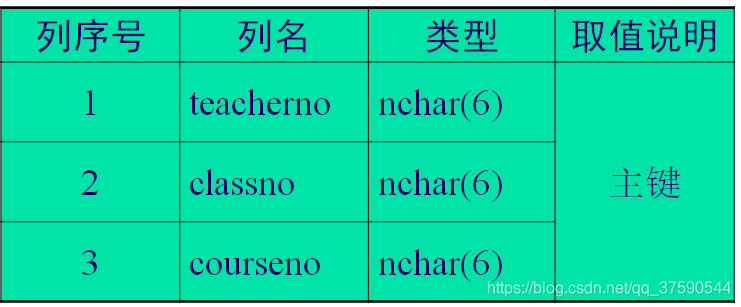
create table teaching.dbo.teach_class(
teacherno nchar(6) not null,
classno nchar(6) not null,
courseno nchar(6) not null,
constraint pk_teaching_class primary key
clustered(teacherno asc,classno asc,courseno asc))
- 为数据表输入数据
图形操作界面:“打开”表,开始输入数据。
3.2.3 数据浏览
- 在查询窗口中浏览表数据
“打开”表,即可查看 - 利用Transact-SQL语句在查询窗口中浏览表数据
select *from course
3.2.4 表结构的修改
- 在SQL Server Management Studio中修改表结构
- 利用Transact-SQL语句修改表结构
alter table的语法格式如下:
alter table [database_name.[schema_name].|schema_name.]table_name
{alter column column_name
{[type_schema_name.]type_name[(precision[,scale]|max|xml_schema_collection})]
[collate collation_name][null|not null]
|{add|drop}{rowguidcol|persisted}
|[with{check|nocheck}]add
{<column_definition>|<computed_column_definition>
|<table_constraint>}[,…n]
|drop
{[constraint] constraint_name
[with(<drop_clustered_constraint_option>[,…n])]
|column column_name}[,…n]}[;]
例3.6
在test01数据库中创建一个新表student1,然后修改其列属性。
create table student1
(column_grade int) --创建新表
go
exec sp_help student1 --查看表的信息
go
alter table student1
add
column_class varchar(20) null --添加列
go
exec sp_help student1
go
alter table student1
drop column
column_grade --删除列
go
exec sp_help student1
go
例3.7
修改test01中表student1的列column_class数据类型和名称。
use test01
go
alter table student1
alter column
column_class char(20) not null
go
exec sp_rename ‘student01.column_class’,‘st_class’
go
3.2.5 表数据的修改
- 利用insert语句输入数据
insert 语句的语法格式如下:
insert [top(expression)[percent]]
[into] {|rowset_function_limited
[with(<table_hint_limited>[…n])]}
{[(column_list)] []
{values({default|null|expression}[,…n])
|derived_table|execute_statement}}
|default values [;]
例3.8
向teaching数据库中的score表中添加数据。
insert into score
(usually,courseno,final,studentno)
values(79,‘c05109’,91,‘0937221508’)
insert into score
value(‘0824113307’,‘c05127’,93,78)
- 利用update语句更新表数据
update 语句的基本语法格式如下:
update [top(expression)[percent]]
{|rowset_function_limited
[with(<table_hint_limited>[…n])]}
set
{column_name=expression|default|null}
}[,…n][<output_clause>][from{<table_source>}
[,…n]][where{<search_condition>}][;]
例3.9
更改teaching数据库中的score表中的学号为0824113307、课程号为c05127的期末成绩修改为87。
update score
set final=87
where studentno=‘0824113307’ and
courseno=‘c05127’
例3.10
为数据库test01中表student1输入3行数据,然后将列st_class的值全部改为jsj1012。
insert into student1
values(‘jixie0809’)
insert int student1
values(‘huag0902’)
insert into student1
values(‘txun0912’)
go
update student1
set st_class = ‘jsj1012’
go
- 利用delete 语句删除表中数据
delete 语句的基本语法格式如下:
delete [top(expression)[percent]]
[from] {|rowset_function_limited
[with(<table_hint_limited>[…n])]}
[] [from<table_sourde>
[,…n]]
[where {search_condition>}] [;]
例3.11
删除数据库test01中表student1的列st_class的值为jsj1012的行。
delete from student1
where st_class=‘jsj1012’
- 利用Truncate Table语句删除表中数据
- Truncate Table语句从一个表中删除所有行的速度要快于delete。语句格式如下:
Truncate table table_name - 若要删除表中的所有行,则Truncate Table语句是一种快速、无日志记录的方法
3.2.6 删除表
- 在SQL Server Management Studio中删除数据表
- 利用Transact-SQL语句删除数据表
利用Transact-SQL语句drop table 就可删除数据表定义及表的所有数据、索引、触发器、约束和指定的权限。其语法格式如下:
drop table[database_name.[schema_name].|schema_name.]table_name[,…n][;]
3.3 数据的完整性
数据的完整性是指数据的精确性和可靠性,是为防止数据库中存在不符合语义规定的数据,防止因错误信息的输入、输出而造成无效的操作或错误信息而提出的,数完整性在数据库管理系统中是十分重要的。
3.3.1 数据完整性的类型
- 域(domain)完整性
- 实体(entity)完整性
- 引用完整性
- 用户定义完整性
3.3.2 约束
- SQL Server 2005支持的约束类型
(1)not null 约束
(2)primary key约束:标识具有唯一标识表中行的值的列或列集。
(3)foreign key约束:外键用于建立和加强两个表数据之间的连接的一列或多列。
(4)unique约束:强制实施列集中值的唯一性
(5)check约束:通过限制可放入列中的值来强制实施域完整性。 - 在SQL Server Management Studio中创建约束
(3)创建foreign key约束
打开外键表,点击关系→添加→表和列规范→选择主键表和外键表及所有共有的列→确定。
(4)创建unique约束
打开表→管理索引和键→添加→是唯一的(是)→关闭
(5)创建check约束
打开表→管理check约束→添加→表达式(sex=‘男’ or sex=‘女’)→确定 - 利用Transact-SQL语句创建或修改约束的语法格式如下:
<table_constraint>::=[constraint constraint_name]
[with{check|nocheck}]
add {table_constraint>}[,…n]
|drop {[constraint]constraint_name
|column column_name}[,…n]
|check|nocheck}constraint
{all|constraint_name[,…n]}
例3.14
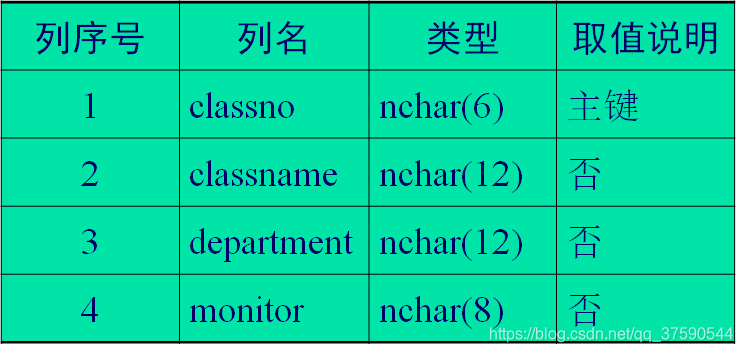
为数据库teaching中的班级表class的列classno创建FOREIGN KEY 约束,并将其中的classname、department、monitor的“允许空”修改为NOT NULL。
alter table class
add constraint pk_class primary key
clustered(classno asc)
go
alter table class
alter column classname nchar(12) not null
go
alter table class
alter column department nchar(12) not null
go
alter table class
alter column monitor nchar(8) not null
go
例3.15
为数据库teaching中的成绩表score的两个列usually和final添加CHECK约束,限定其值在0~100范围内。
alter table score
add constraint ck_usually
check(usually>=0 and usually<=100),
constraint ck_final
check(final>=0 and final<=100)
go
例3.16
为数据库teaching中的学生信息表student的列Email创建一个UNIQUE约束。
alter table class
add constraint u_Email unique
nonclustered(Email)
go
例3.17
为数据库teaching中表score的列studentno创建一个FOREIGN KEY约束。
alter table score
with check
add constraint fk_sc_stud foreign key
(studentno)
references student(studentnno)
go
- 删除约束
通过Transact-SQL语句也可以删除约束,删除约束的语法格式如下:
alter table table_name
drop constraint constraint_name
{ all|constraint_name[,…n]}
例3.18
利用命令删除为数据库teaching中表score的一个约束FK_score_student1。
alter table score
drop constraint fk_score_student1
- 禁止使用约束
禁止约束就是禁止使用在现有数据上的约束检查。
(1)禁用在现有数据上的约束检查;
(2)在加载新数据时禁用约束检查。
3.3.3 规则
- 使用create rule命令创建规则
语法格式如下:
create rule
[schema_name.] rule_name
as condition_expression [;]
例3.19
为数据库teaching创建一条规则score_rule,该规则规定凡是分数类的列值必须在0~100之间。
use teaching
go
create rule score_rule
as @score between 0 and 100
go
- 绑定规则
规则是一种独特的对象。要使之生效,必须用sp_bindrule将其与表中的列绑定。
绑定规则的语句格式:
sp_bindrule [@rulename=]‘rule’,
[@objname=]‘object_name’
[,[@futureonly=]‘futureonly_flag’]
例子
use teaching
exec sp_bindrule ‘score_rule’,‘score.usually’
3. 解除列上绑定的规则
解除规则的绑定sp_unbindrule存储过程,sp_unbindrule存储过程的语法格式如下:
sp_unbindrule[@objname=]‘object_name’
[,[@futureonly=]‘futureonly_flag’]
例如
例如,要解除绑顶定到score表的usually列上的规则,可以使用以下Transact-SQL语句:
use teaching
go
exec sp_unbindrule ‘scroe.usually’
- 解除规则
解除规则绑定后,就可以用drop rule 语句删除规则score_rule了。
drop rule score_rule
3.3.4默认值
默认值是一种数据库对象,属于逐步取消的数据完整性手段。
- 使用create default 命令创建默认值
语句格式如下:
create default
[schema_name.]default_name
as constraint_expression[;]
例如
例如,在teaching数据库中创建一个type_default默认值对象的程序代码如下:
create default type_default as ‘必修’
2. 利用存储过程绑定默认值
在创建默认值后,必须将它与特定表的列绑定后才能使之发挥作用。用sp_bindefault存储过程绑定默认值到列。sp_bindefault存储过程的语法格式如下:
sp_bindefault[@defname=]‘default’,
[@objname=]‘object name’
[[@futureonly=]‘futureonly flag’]
例如
例如,将上面的type_default默认值对象绑定course表的type列上,可以用以下Transact-SQL语句。
exec sp_bindefault ‘type_default’,‘course.type’
- 解除默认值对象的绑定
删除默认值对象时,首先要执行sp_unbindefault存储过程,取消默认值对象的绑定,然后执行drop default语句删除默认值对象。
解除默认值对象绑定的sp_unbindefault存储过程语法格式如下:
sp_unbindefault[@objname=]‘object_name’
[,[@futureonly=]‘futureonly_flag’]
例如
exec sp_unbindefault ‘course.type’
- 删除默认值对象
删除默认值语法格式:
drop default {default_name}[,…n]
3.3.5 强制数据的完整性
通过以下两种方法可以强制数据库完整性:
(1)由声明保证的数据完整性。声明数据完整性是指定义数据标准,规定数据必须作为对象定义的一部分,SQL Server 2005将自动确保数据符合标准。实现基本数据完整性的首选方法是使用由声明保证的完整性。
(2)过程定义数据完整性。使用过程保证的数据完整性,即可以通过编写脚本来定义数据必须满足的标准,并执行这个标准。在SQL Server 2005中可以通过使用触发器和存储过程来实现过程定义数据完整性。
3.4 数据库关系图
数据库关系图(database diagram)是数据库中对象的图形表示形式。
数据库对象图包括表对象、表所包含的列以及它们之间的相互关联的情况。
可以通过创建关系图或打开现有的关系图来打开数据库关系图设计器
- 创建数据库关系图
新建数据库关系图→选择所需的表,添加→继续添加或删除表→ - 在数据库关系图中修改数据库对象
展开数据库关系图,选择→表视图|标准、列名或键命令→输入新的列名→ - 数据库关系图中的要素
(1) 表功能
A. 标题栏:显示表的名称;
B. 行选择器:选择表中的数据库列;
C. 属性列:仅在表的某些视图中可见。
(2) 在数据库关系图中,每个关系都可以带有3种不同的功能:终结点、线型和相关表。
A. 终结点如果某个关系在一个终结点处有键,在另一个终结点处有无穷符号,则该关系是一对多关系。如果某个关系在每个终结点处都有键,则该关系是一对一关系。
B. 线型线本身表示当向外键表添加新数据时,DBMS是否强制关系的引用完整性。如果为实线,则在外键表中添加或修改行时,DBMS将强制关系的引用完整性。如果为点线,则在外键表中添加或修改行时,DBMS不强制关系的引用完整性。
C. 相关表关系线表示两个表之间存在外键关系。对于一对多关系,外键表是靠近线的无穷符号的那个表。如果线的两个终结点连接到同一个表,则该关系是自反关系。可以打开数据库关系图以查看或编辑关系图的结构。 - 查看数据库关系图
查看数据库关系图的步骤如下:
(1)在对象资源管理器中,右击相应数据库的“数据库关系图”节点下的已经建成的数据库关系图。
(2)在弹出菜单中,单击“修改”命令。即可查看和修改选择的关系图。
(3)或者在对象资源管理器中,展开“数据库关系图”文件夹。双击要打开的数据库关系图的名称。
由此可见,数据库关系图还是一种可视化工具,可用于对所连接的数据库进行设计和可视化处理。
3.5 数据的导入和导出
3.5.1 数据转换概述
- SQL Server 2005 Integration Services (SSIS)是一种企业数据转换和数据集成解决方案,用户可以以此从不同的数据源提取、转换、复制及合并数据,并将其移至单个或多个目标。SSIS的典型用途如下。
- 合并来自异类数据存储区的数据,包括文本格式、Excel和Access等数据。
- 自动填充数据仓库,进行数据库的海量导入、导出操作。
- 对数据的格式在使用前进行数据标准化转换。
- 将商业智能置入数据转换过程。
- 使数据库的管理功能和数据处理自动化。
- Integration Services 的数据转换类型
数据转换将输入列中的数据转换为其他数据类型,然后将其复制到新的输出列。例如,可从多种数据源中提取数据,然后用此转换将列转换为目标数据存储所需的数据类型。如果需要配置数据转换,可以采用下列方法:
- 指定包含要转换的数据的列和要执行的数据转换的类型。
- 指定转换输出列是使用 Microsoft SQL Server 2005 Integration Services (SSIS) 提供的不区分区域设置的较快分析例程,还是使用标准的区分区域设置的分析例程
Integration Services 数据引擎支持具有多个源、多个转换和多个目标的数据流。利用数据转换,开发人员可以方便地生成具有复杂数据流的包,而无需编写任何代码。
- SQL Server数据的导入导出向导
SQL Server 导入和导出向导提供了最低限度的数据转换功能。
(1)向导的主要功能是复制数据。是快速创建在两个数据存储区间复制数据的Integration Services 包的最简单方法。
(2)在SQL Server2005中的新增功能。通过使用 SQL Server 导入和导出向导创建的已保存的包可以在Business Intelligence Development Studio 中打开,并可以使用 SSIS 设计器进行扩展。
(3)访问的数据源。SQL Server 导入和导出向导可以访问下列类型的数据源:SQL Server、平面文件、Access、Excel以及其他 OLE DB访问接口。此外,还可以将ADO.NET用作源。 - 启动 SQL Server 导入导出向导的常用方法
在 Business Intelligence Development Studio 中,右键单击“SSIS包”文件夹,再单击“SSIS导入和导出向导”。
在 Business Intelligence Development Studio 中的“项目”菜单上,单击“SSIS 导入和导出向导”。
在 SQL Server Management Studio 中,连接到数据库引擎服务器类型,展开数据库,右键单击一个数据库,指向“任务”,再单击“导入数据”或“导出数据”。
3.6 小结
重点掌握如下几方面的基本操作。
- 各种数据类型的特点和用途。
- 数据库表结构的创建、修改和删除等基本操作和命令。
- 表数据的插入、更新和删除。
- 如何在创建表时进行数据完整性的设置。
- 各种数据格式之间的转换。
附件:
使用到的数据库:
https://pan.baidu.com/s/1Lmbw_qSmC04wnPUUgwSKRA
提取码:djsz