来源:elitedatascience
编译:BigQuant
成千上万的数据科学新手会在不知不觉中犯下一个错误,你知道是什么吗?
这个错误可以一手毁掉你的机器学习模型,这并不夸张。
我们现在来讨论应用机器学习中最棘手的障碍之一:过拟合(overfitting)。
在本文中,我们将详细介绍过拟合、如何在模型中识别过拟合,以及如何处理过拟合。
最后你会学会如何一劳永逸地处理这个棘手的问题。你将读到下面这些内容:
- 过拟合的例子
- 信号与噪音
- 拟合优度
- 过拟合和欠拟合
- 如何检查过拟合
- 如何避免过拟合
过拟合的例子
假设我们想根据一个学生的简历预测她是否会获得面试机会。
现在,假设我们从10000份简历的数据集及其结果中训练模型。
接下来,我们在原始数据集上尝试这个模型,它预测结果的准确率达到99%……哇!
但这是个坏消息。
当我们在简历的新(“没见过的”)数据集上运行模型时,我们只能获得50%的准确度…即
我们的模型从训练数据到新数据的泛化能力并不好。
这被称为过拟合,也是机器学习和数据科学中的常见问题。
事实上,过拟合在现实世界中也一直在发生着。看看新闻频道:

信号与噪音
您可能听说过Nate Silver著名的《信号与噪音》一书。
在预测建模中,您可以将“信号”视为希望从数据中学习到的真正底层模式。
另一方面,“噪音”指的是数据集中无关的信息或随机性。
例如,假设您正在建模儿童身高与年龄的关系。如果您对大部分人口进行抽样,您会发现一个非常明确的关系:
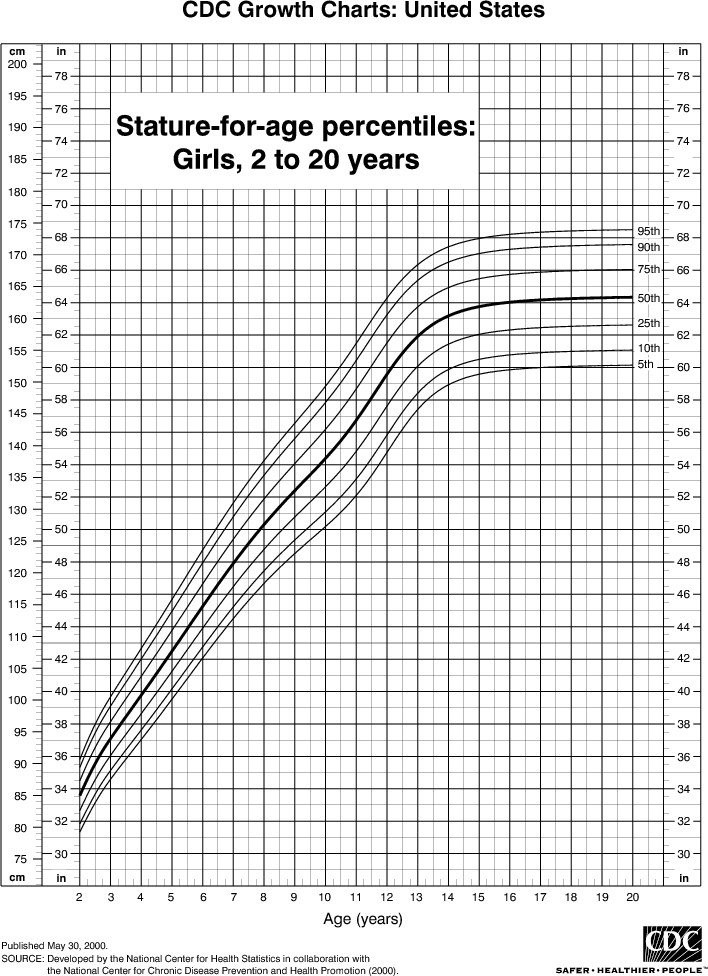
这就是是信号。然而,如果你只能对当地的一所学校进行抽样调查,这种关系可能会更加复杂。 它会受到异常值(比如,爸爸是NBA球员的孩子)和随机性(例如在不同年龄段进入青春期的孩子)的影响。
“噪音干扰了信号”
这就是机器学习的用武之地。一个运行良好的机器学习算法能将信号从噪声中分离出来。
如果算法过于复杂或灵活(例如,它有太多的输入特性或它没有适当的正则化),它最终可能“记住噪音”而不是找到信号。
这个过拟合模型将基于这些噪声进行预测。它将在训练数据上表现得异常出色……但在新的、未见过的数据上表现得非常糟糕。
拟合优度
在统计学中,拟合优度是指模型的预测值与观测值(真实)的匹配程度。
一个学习了噪声而不是信号的模型被认为是“过拟合”的,因为它适合训练数据集,但与新数据集的拟合度较差。
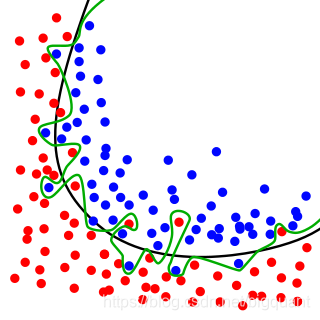
过拟合与欠拟合
通过观察相反的问题,我们可以更好地理解欠拟合。 当一个模型过于简单时,因为它的特性太少,或者过于正则化,就会出现欠拟合现象,这使得它在学习数据集时不够灵活。
简单的模型在预测结果上往往有较小的方差和较大的偏差(见:偏差-方差权衡)。
另一方面,复杂的模型往往在预测中有更大的方差。
偏差和方差都是机器学习中预测误差的两种形式。
通常,我们可以减少由偏差引起的误差,但同时可能会增加由方差带来的误差,反之亦然。
太简单(高偏差)与过于复杂(高方差)之间的权衡是统计和机器学习中的关键概念,也是影响所有监督学习算法的关键概念。
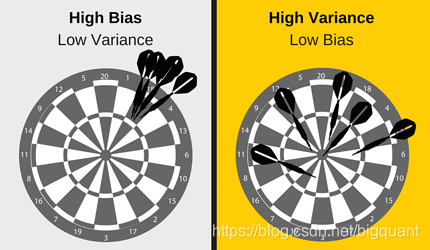
如何检查过拟合
过拟合以及机器学习的一个关键挑战是,在我们实际测试之前,我们无法知道模型对新数据的执行情况。
为了解决这个问题,我们可以将初始数据集拆分为单独的训练和测试子集。
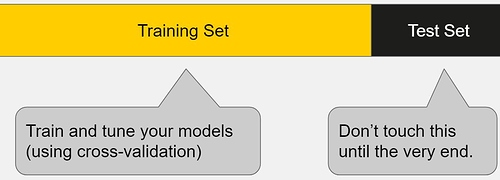
这种方法可以估计出我们的模型在新数据上的表现。
如果我们的模型在训练集上比在测试集中表现得好得多,那么我们很可能会过拟合。
例如,如果我们的模型在训练集上有99%的准确率,但在测试集上只有55%的准确率,那将是一个很危险的信号。
另一个建议是从一个非常简单的模型开始,以此作为基准。
然后,当您尝试更复杂的算法时,您将有一个参考基准来查看额外的复杂性是否值得。
这是奥卡姆剃刀试验。如果两个模型具有类似的性能,那么通常应该选择比较简单的一个。
如何避免过拟合
检查过拟合是有用的,但它不能解决问题。幸运的是,有几个方法您可以尝试。
以下是一些最常用的过拟合解决方案:
交叉验证
交叉验证是预防过拟合的一个强有力措施。
将您的初始训练数据拆分成多个数据集(类似于迷你火车),使用这些拆分子集来调整模型,这是一个聪明的想法。
在标准的K-fold交叉验证中,我们将数据划分为K个子集,称为“折叠(folds)”。
然后我们迭代地在K-1个折叠上训练算法,同时使用剩余的折叠作为测试集。
交叉验证允许您仅使用原始训练集来调整超参数。这使您可以将测试集保存为真正“未见过”的数据集,以便选择最终模型。

使用更多数据
它不会每次都有效,但是使用更多数据进行训练可以帮助算法更好地检测到信号。
在早期的儿童身高与年龄建模的例子中,很明显如何抽样更多的学校将有助于您的模型。
当然,情况并非总是如此。如果我们只是添加更多的噪声数据,这种技术将无济于事。
这就是为什么您应该始终确保您的数据是干净和相关的。
删除无用特征
有些算法有内置的特征选择。 您可以通过删除不相关的输入特性来手动改进它们的通用性。
一种有趣的方法是通过描述每个特性是如何融入模型的。如果很难证明一些特性的存在合理性,
说明这些特征是没必要的。
及时中止
当您迭代训练学习算法时,您可以度量模型的每次迭代的执行情况。
当迭代至一定次数之前,新的迭代会不断改进模型。然而,在那之后,模型的泛化能力会随着训练数据开始过拟合而减弱。
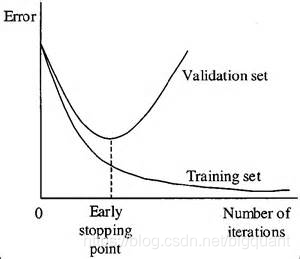
现在,这种方法主要用于深度学习,而其他的方法(如正则化)更适合于经典的机器学习。
正则化
正则化是指人为地迫使模型变得更简单的一系列技术。
这个方法将取决于你使用的模型类型。
例如,您可以修剪决策树,在神经网络上使用dropout,或者在回归中向代价函数添加一个惩罚参数。
通常,正则化方法也是一个超参数,这意味着它可以通过交叉验证进行调优。
集成学习
集成(Ensembling)是一种机器学习方法,用于将多个不同模型的预测组合在一起。
集成有几种不同的方法,但最常见的两种是:
Bagging:降低复杂模型过拟合的可能性。
- 它同时训练大量“强大”的模型。
- 一个“强大”的模型是一个相对不受约束的模型。
- 然后将所有“强大”的模型结合在一起,以“平滑”他们的预测。
Boosting:改进简单模型的预测能力。
- 它训练大量“弱”的模型。
- 一个“弱”模型是一个受约束的模型(例如,你可以限制每个决策树的最大深度)。
- 每个模型都专注于从之前的错误中学习。
- 然后把所有的弱学习者组合成一个强大的学习者。
虽然Bagging和Boosting都是集成方法,但它们从相反的方向解决问题。
Bagging使用复杂的基础模型,试图“平滑”他们的预测,而Boosting使用简单的基础模型,并试图“提高”他们的总复杂度。
原文链接:《机器学习中的过拟合 》
本文由BigQuant人工智能量化投资平台原创推出,版权归BigQuant所有,转载请注明出处。