小码哥虽然学历不高但也不算低嘛,可碰计算机中这些个字符编码,感觉自己宛若文盲。心急之下扒了些资料,结果概念越来越多什么ASCII、Unicode、GB2312、GBK、GB18030、UTF-8、UTF-16、UTF-32等等,此刻内心回想起那句箴言“学海无涯,回头是岸” -_-!。
困苦之际,回想起自己以前一段职业生涯中常说的一句话“如果觉得学的不够爽,那一定是姿势不对!”。那什么是对的姿势呢?先理清脉络,再做好分类,抓主要矛盾,最后举一反三。
而在众多的字符名字中如何厘清脉络进行分类呢,小码哥觉得区分字符集和字符编码是关键,如下:
字符集
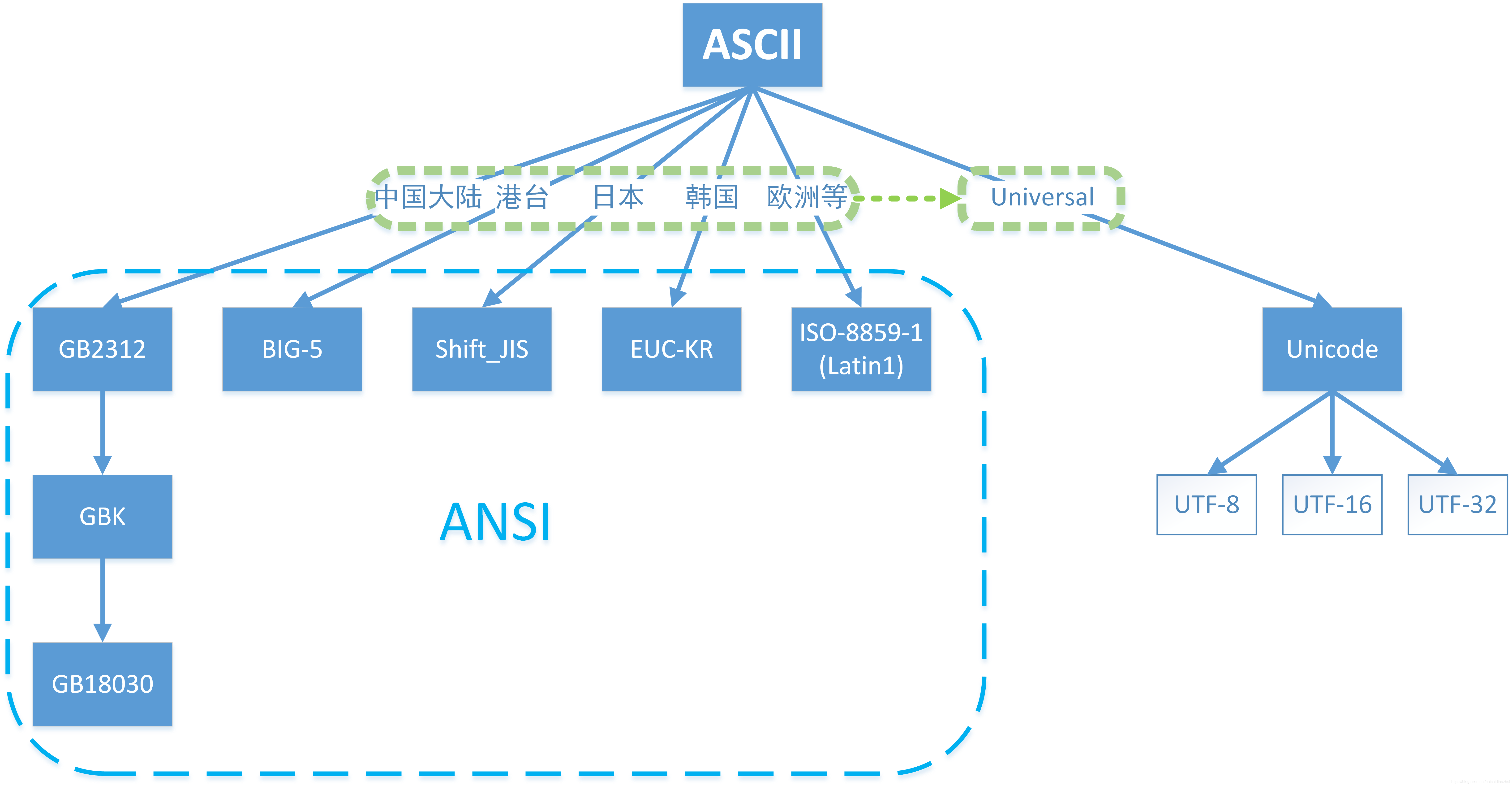
字符集:说白了就是某些特定字符的集合,如果把世界上不同国家文明的所有字符都放在一起组成一个集合,那么我们常见的 ASCII、GB2312、GBK、GB18030、BIG5 字符集都只是包含了该集合的一部分而已。而 Unicode 字符集是可以包含所有国家文明中的所有字符的。
现实生活中的字符例如英文字符、中文汉字等,想要用计算机能读懂的用二进制或十六进制等方式表述,那么必须要建立一个一对一的映射表,而字符集就是这种映射表。而不同的地区都各自为政,他们构建了自己的映射表,所以就有ASCII、GB2312、GBK、GB18030、BIG5这么多不同的字符集,然而这些映射表大多只包含本地区常用的字符,而不关心是否与其他地区相冲突,因此同样的二进制在不同的字符集中可能会翻译为字符例如中文或日文因此这些字符集是非完备的。
而 Unicode 则是一位想要一统江湖的大神,在它的映射表中,建立了全球所有符号对应的二进制码,Unicode 现在的规模可以容纳100多万个符号。
字符编码
字符编码:所有的文件在计算机中最终是以二进制序列来保存的,不同的序列就可以表示不同的内容。字符编码的目的就是对不同的字符编码设计合理的唯一二进制序列在计算机中进行存储表示。
字符编码是与计算机的储存方式相关的,不同的字符集存在其特有的字符编码。 字节是计算机中对二进制序列表达最常用的单位,一字节的长度是8位,能够表达256种不同的状态,也就是256个不同的字符。
- ASCII 字符集:采用一个字节来表示,包括7位表示的ASCII 编码和8位表示的扩展ASCII 编码(ISO-8859-1编码)
- GB2312、GBK、GB18030 编码:采用两个字节来表示一个汉字字符,保证对 ASCII 编码的兼容性,每个字节的最高一位比特总是为 1。
- BIG5、Shift_JIS、EUC-KR 编码:与 GB2312 等编码标准的出现相似,BIG5编码 主要是台湾地区为了解决对繁体字的处理。Shift_JIS 为日本电脑系统常用的编码方案,EUC-KR 为韩国电脑系统常用编码方案。
- Unicode 对应有三种字符编码方式,分别是:UFT-8、UFT-16、UFT-32
UFT-8:一种变长的编码方案,使用 1~6 个字节来存储;
UFT-32:一种固定长度的编码方案,不管字符编号大小,始终使用 4 个字节来存储;
UTF-16:介于 UTF-8 和 UTF-32 之间,使用 2 个或者 4 个字节来存储,长度既固定又可变。
补充概念: 字节是计算机中对二进制序列表达最常用的单位,一字节的长度是8位,能够表达256种不同的状态,也就是256个不同的字符。
小结
总结:经过上边的介绍,我们可以大致认为,现在流行的一些编码方案都是在兼容 ASCII 的基础上来实现的。为了满足各国家地区的更多字符的编码需求,出现了 ANSI 编码标准,但是该编码标准在具体各地区国家的实现上是彼此不兼容的。为了满足世界各国字符编码的兼容性需求,Unicode 定义了一个统一、完备的字符集。为了实现 Unicode 字符集在编码上的需求,又诞生了 UTF-8、UTF-16等等编码方案。
概貌图如下: